
"GPT-5 Codex" is not a model. It's a family — and OpenAI has released at least seven distinct labels in this family since mid-2025. If you've tried to figure out whether gpt-5.3-codex and gpt-5.2-codex are still usable, whether "High" is a model variant or a reasoning setting, and why the CLI's /model menu shows names that don't match the API docs, this article clears all of that up in one read.

Why GPT-5 Codex Naming Is Confusing
Codex as model family vs product surface
"Codex" refers to two things simultaneously, which is the root of most confusion:
- Codex the product surface — the CLI, IDE extension, desktop app, and cloud agent platform
- Codex the model family — a series of GPT-5 variants optimized for agentic coding
When OpenAI says "GPT-5.3-Codex," they mean the model. When they say "use Codex CLI," they mean the tool. A model from the Codex family can run in the Codex product surface, but GPT-5.5 — which isn't named "Codex" — is also the current default model in Codex CLI.
The naming conflation is intentional product language, not a mistake. But it means "Codex" in documentation can refer to either the model or the tool depending on context.
Why developers still search old labels
GPT-5.1-Codex blog posts, tutorials, and Stack Overflow answers from late 2025 are still indexed. GPT-5.1-Codex-Max documentation was the primary reference for multi-context compaction for several months. GPT-5.2-Codex is still the correct model ID for API-key workflows as of May 2026 because GPT-5.5 isn't yet available without ChatGPT sign-in. People aren't searching old labels out of ignorance — in some cases, those labels still apply.
Current Codex Model Labels
All of the following model names are real, released models. Status is current as of May 2026, based on the official Codex models page and OpenAI help center release notes.
GPT-5.3-Codex
The model that brought GPT-5's reasoning and GPT-5's coding capabilities into a single unified architecture. Released February 2026. Key characteristics:
- 25% faster than GPT-5.2-Codex
- First Codex model to combine the Codex and GPT-5 training stacks
- Supports reasoning effort settings:
low,medium,high,xhigh - Available in the API via
gpt-5.3-codex - Powers GPT-5.4 (GPT-5.4 incorporated GPT-5.3-Codex's coding capabilities into a general-purpose model)
GPT-5.3-Codex-Spark is a separate, smaller variant announced in the same period. It's optimized for near-instant output (1,000+ tokens per second), text-only, has a 128K context window, and is a research preview limited to ChatGPT Pro users. It's not available in the API. For API-key workflows, ignore Spark — it doesn't exist in that context.
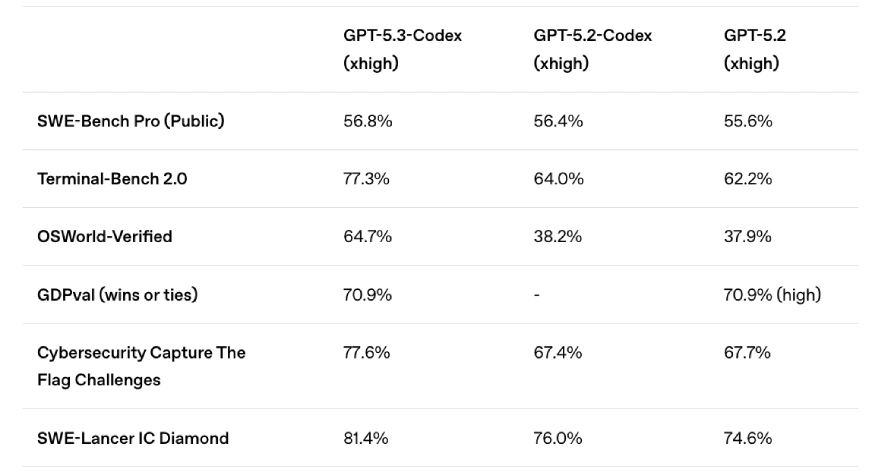
GPT-5.2-Codex and GPT-5.1-Codex legacy searches
GPT-5.2-Codex — released January 2026. Significant for context compaction (native ability to compress context and continue working past the window limit), improved Windows environment support, and stronger performance on SWE-Bench Pro and Terminal-Bench 2.0 at the time of release. Still the recommended model for API-key authentication workflows as of May 2026, because GPT-5.5 doesn't yet support API key auth.
GPT-5.1-Codex — released in late 2025. Superseded by 5.2. Still listed in the API models catalog but legacy. Not recommended for new integrations.
GPT-5.1-Codex-Max — introduced compaction natively (operating coherently across multiple context windows). Built for long-horizon project-scale work. First model trained for Windows environments. Also legacy. GPT-5.2-Codex and later models carry forward these capabilities.
GPT-5.1-Codex retirement note: GPT-5.1 (non-Codex) models were retired from ChatGPT as of March 11, 2026. The Codex-specific variants (GPT-5.1-Codex, GPT-5.1-Codex-Max) remain in the API models catalog but receive no new development.
Mini, Max, and High labels
These three labels cause persistent confusion because they appear in different contexts with different meanings.
Mini — a smaller, cheaper, faster variant of a base model:
- GPT-5-Codex-Mini: announced as providing 4× more subscription usage headroom vs GPT-5-Codex; used for lighter tasks and subagents
- GPT-5.4-Mini: current mini-tier option in Codex; available in CLI and IDE extension; appropriate for interactive edits and subagent roles in multi-agent workflows
Max — extended long-horizon capability, not just "better":
- GPT-5.1-Codex-Max: first model natively trained to operate across multiple context windows via compaction. The "Max" name here specifically meant multi-context, multi-hour task capability. Legacy as of 2026.
High / xhigh — these are reasoning effort settings, not model variants. You set them as configuration parameters:
- Via API:
"reasoning": {"effort": "high"}or"effort": "xhigh" - Via CLI:
/effort highor--effort xhigh - They control how much thinking budget the model applies per turn
A "GPT-5.3-Codex high" reference in documentation means GPT-5.3-Codex with high reasoning effort — not a separate "High" model. This is the most common misread in the naming system.
Context Window and Token Limits Across Codex Models
| Model | Context window | Notes |
|---|---|---|
| gpt-5.5 | 1M tokens | Current default when available |
| gpt-5.4 | 1M tokens | Experimental 1M in Codex; also in API |
| gpt-5.4-mini | 200K tokens | Lighter tasks |
| gpt-5.3-codex | 200K tokens | Confirm viamodel page |
| gpt-5.3-codex-spark | 128K tokens | Text-only; research preview |
| gpt-5.2-codex | Context compaction | Operates across multiple windows |
| gpt-5.1-codex-max | Context compaction | Legacy; multiple windows via compaction |
Context windows are confirmed from official documentation except where noted. Verify current values before production use — these change with model updates.
Why context size matters for coding agents
The practical difference between 128K (Spark), 200K (GPT-5.3-Codex), and 1M (GPT-5.4/5.5) tokens isn't just about how long your conversations can run. In agentic coding workflows, context fills with tool call outputs, file contents, test results, and error logs. A 128K window exhausts in a medium-sized refactor. A 200K window handles most single-feature implementations. 1M opens up large-scale migrations and full codebase analysis without manual chunking.
Compaction (GPT-5.1-Codex-Max onwards) is an architectural alternative: instead of a larger window, the model compresses history and continues working. GPT-5.2-Codex refined this. GPT-5.5's 1M window effectively sidesteps the need for frequent compaction on most tasks.
Which Names Are Still Useful
What to use in docs and workflows
In May 2026, the useful model names are:
gpt-5.5 — default for ChatGPT-authenticated sessions (Codex CLI, app, IDE)
gpt-5.4 — fallback if gpt-5.5 not yet available in your account
gpt-5.4-mini — lighter tasks, subagents, interactive edits
gpt-5.2-codex — API-key authenticated workflows (gpt-5.5 not available this way yet)
gpt-5.3-codex — if you specifically want the Codex-specialized model in the APIIn the CLI, these names work with --model:
codex --model gpt-5.4
codex --model gpt-5.4-mini
codex --model gpt-5.2-codexOr set a default in config.toml:
[model]
name = "gpt-5.4"What to ignore in old screenshots
- Any reference to
gpt-5.1-codexas a current recommendation — it's legacy - "Codex Max" without a version number — likely refers to GPT-5.1-Codex-Max, which is superseded
- "Codex High" as a model name — "high" is a reasoning effort level, not a model
- GPT-5-Codex (original, no version number) — functional but not recommended for new work
How This Affects Coding Workflows
The naming complexity has a practical consequence: if you're following a tutorial or copying config from a blog post written before April 2026, the model IDs may be out of date. An npm i -g @openai/codex installs the current CLI, but your config.toml or your API calls may still point to gpt-5.2-codex when gpt-5.4 or gpt-5.5 is now the right choice.
For ChatGPT-authenticated sessions (Plus, Pro, Business): don't specify a model name. Let Codex default to whatever's current — the default tracks the recommended model automatically. If you pin a model ID in config, you're opting out of automatic upgrades.
For API-key sessions: use gpt-5.2-codex for now, and watch the Codex changelog for when gpt-5.5 becomes available with API key auth. OpenAI has indicated this is coming.
For multi-agent workflows where a cheaper subagent model matters: gpt-5.4-mini is the current right answer. Its predecessor, GPT-5-Codex-Mini, provided 4× more subscription usage headroom — the Mini tier exists specifically for high-frequency subagent calls.
FAQ
What does GPT-5.3-Codex actually mean?
It's the third major iteration of the Codex-specific model, built on GPT-5.3's base. OpenAI released it on February 5, 2026. The significance: it was the first Codex model to combine the Codex training stack (optimized for coding) with GPT-5's reasoning and general intelligence stack — previous Codex models were derived from specific GPT-5 variants but weren't unified. It's 25% faster than GPT-5.2-Codex and supports four reasoning effort levels.
Is GPT-5.1-Codex or GPT-5.2-Codex still usable in 2026?
GPT-5.2-Codex: yes, actively recommended for API-key authentication workflows because GPT-5.5 isn't available that way yet. GPT-5.1-Codex: technically still in the API model catalog but legacy — OpenAI won't route you there by default and there's no reason to use it over 5.2 or 5.3-Codex.
Which model name should I use in the CLI right now?
For ChatGPT-authenticated sessions: don't pin a model; use Codex's default (currently GPT-5.5 where available, GPT-5.4 as fallback). For API-key sessions: use gpt-5.2-codex until GPT-5.5 API auth ships. Switch to gpt-5.4-mini for subagent roles where speed and cost matter more than peak capability.
Do different Codex models have different context windows?
Yes, significantly. GPT-5.3-Codex-Spark has 128K (text-only research preview). GPT-5.3-Codex and GPT-5.4-Mini have 200K. GPT-5.4 and GPT-5.5 support up to 1M tokens (GPT-5.4's 1M is currently labeled experimental in Codex). GPT-5.2-Codex and GPT-5.1-Codex-Max use context compaction rather than a fixed large window — they compress history and continue working past the base window limit.
Related Reading
