
Three models, three fundamentally different bets on what agentic coding infrastructure should look like. Before the numbers: one framing note you need upfront. Claude Opus 4.6 is no longer Anthropic's flagship — Opus 4.7 shipped on April 16, 2026, at the same $5/$25 price. If you're evaluating "best Anthropic model for coding," the right comparison is Opus 4.7. This article uses Opus 4.6 because it's the reference point in DeepSeek V4's official benchmark table and because many teams are still running 4.6 in production. Where 4.7 changes the picture, it's noted.
Three Very Different Coding Bets
DeepSeek V4 as open-weight agentic coder
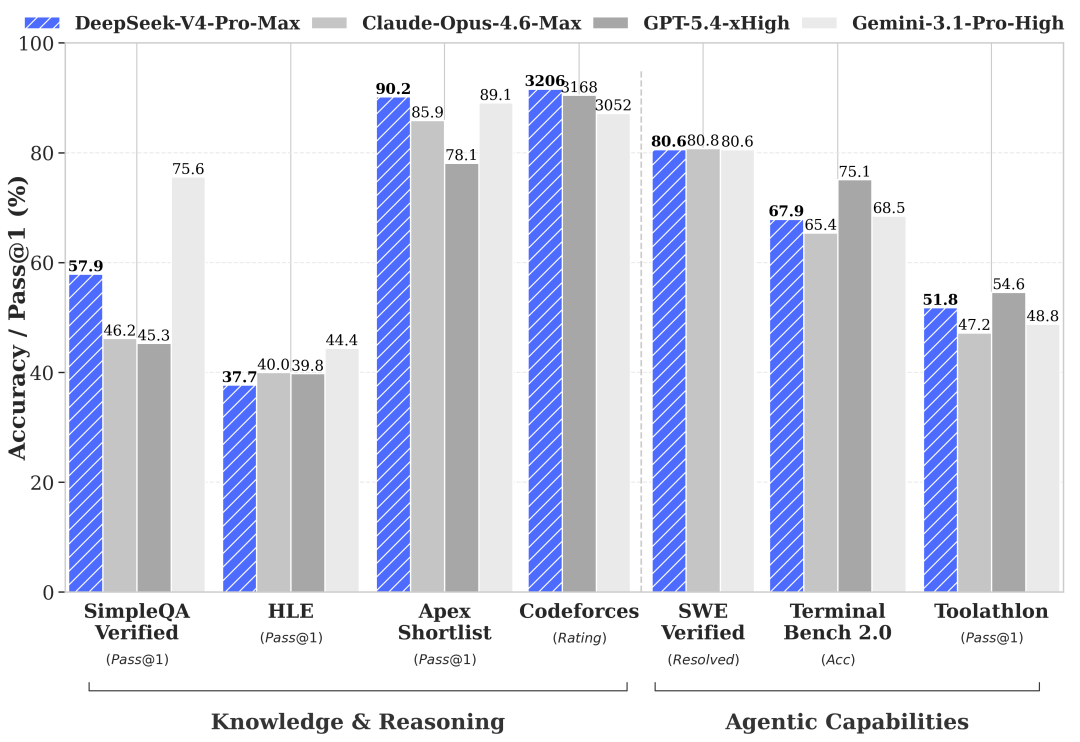
DeepSeek V4 Preview (April 24, 2026) is the only open-weight model in this comparison. Weights are on Hugging Face under MIT. The API is live. The "Preview" label means behavior isn't finalized — but the model is production-testable now. V4-Pro's primary claims are agentic coding at competitive quality and infrastructure costs that sit roughly 3–35× below the closed alternatives. The open-weight path is what no other model here offers.
Claude Opus 4.6 as deep coding reasoner
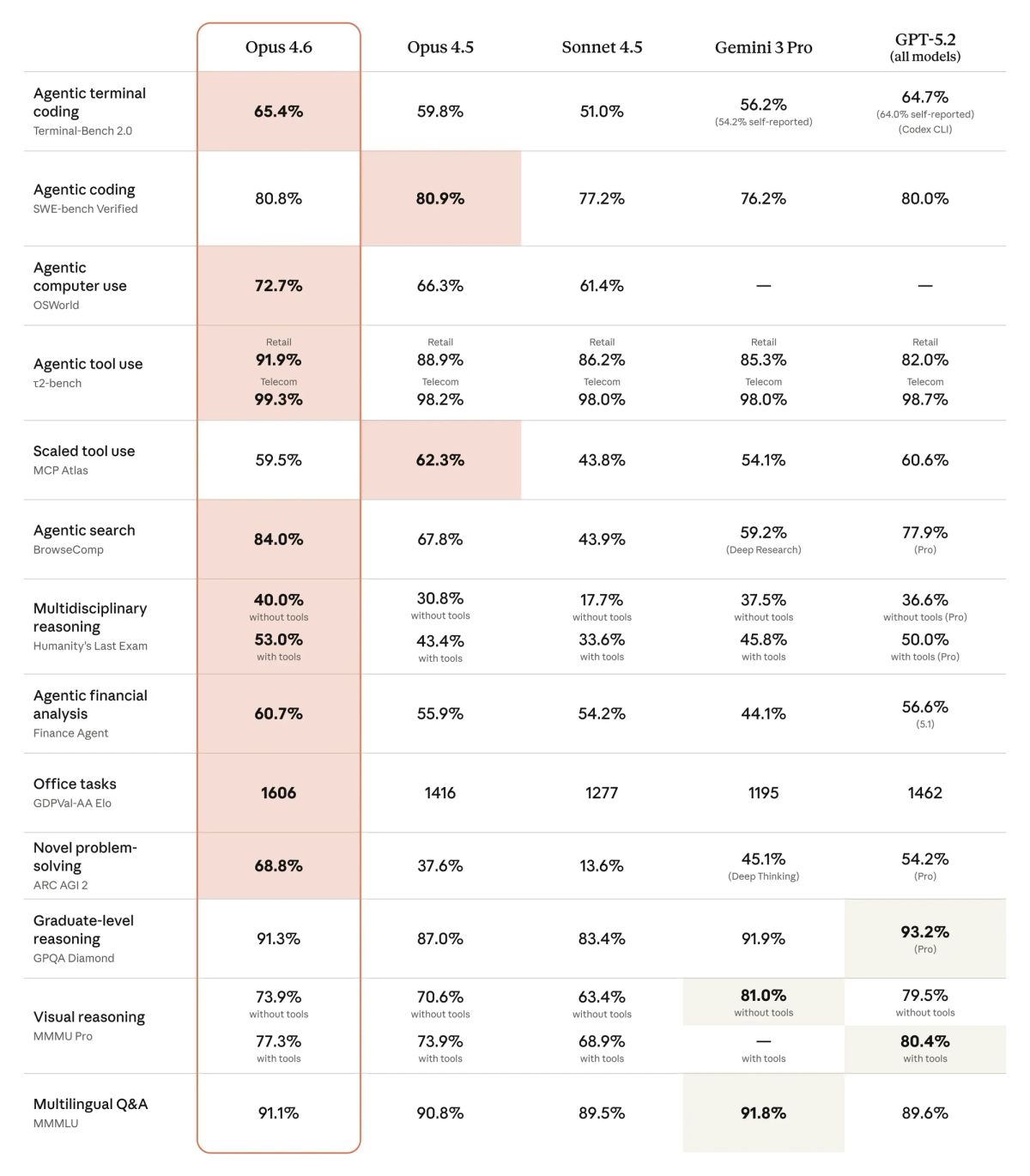
Opus 4.6 is Anthropic's previous flagship — still widely deployed, still receiving full platform support, and the model most teams associate with the "highest-quality Anthropic coding output" position it held before 4.7. Its SWE-Bench Verified score (80.8%) was best-in-class at launch. Its reasoning depth on complex, multi-file, ambiguous tasks remains a practical strength. The case for staying on 4.6 instead of migrating to 4.7 is narrow — primarily inertia and regression risk — but it's the dominant model in current production Claude deployments.
GPT-5.5 as tool-using work model
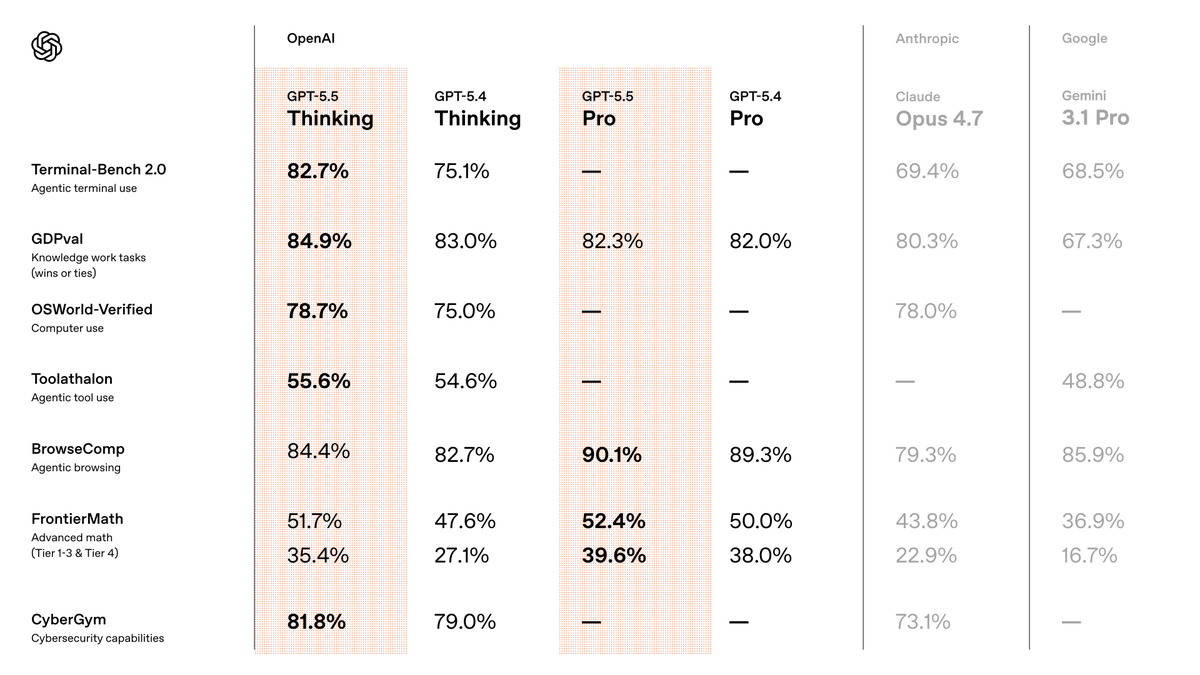
GPT-5.5 (April 23, 2026) is OpenAI's current positioning as the model for "real work." The benchmark story is Terminal-Bench 2.0 at 82.7% — the strongest published number on tool-coordination workflows in this comparison. The framing is explicitly agentic: fewer prompting steps, more autonomous task completion, built for messy multi-part work rather than single-turn quality. API went live April 24. Cost doubled vs GPT-5.4.
Comparison Table
Availability and access
| DeepSeek V4-Pro | Claude Opus 4.6 | GPT-5.5 | |
|---|---|---|---|
| API | Live (deepseek-v4-pro) | Live (claude-opus-4-6) | Live (gpt-5.5) |
| Open weights | ✅ MIT, Hugging Face | ❌ | ❌ |
| Self-hosted | ✅ (865GB, needs 8×H100) | ❌ | ❌ |
| Status | Preview (behavior may change) | GA (superseded by 4.7) | GA |
| ChatGPT / product | chat.deepseek.com | claude.ai | ChatGPT Plus+ |
| IDE integration | Via API / community plugins | Claude Code, VS Code ext | Codex, Cursor |
Hosted API vs ChatGPT/Codex vs open weights
For API teams the access pattern is identical: POST to an endpoint, get a response. The operational differences emerge from stability guarantees (Preview vs GA), version-freezing (DeepSeek hasn't committed to V4 behavior stability; Anthropic and OpenAI do), and data residency (V4 self-hosted eliminates cloud vendor dependency).
Codex integration for GPT-5.5 gives it a native IDE path at 400K context. Claude Code with Opus 4.6 is the comparable native path for Anthropic. DeepSeek V4 lacks a first-party IDE tool; third-party integrations via OpenAI-compatible API work in Cursor and similar tools.
Context and workflow fit
| DeepSeek V4-Pro | Claude Opus 4.6 | GPT-5.5 | |
|---|---|---|---|
| Context window | 1M tokens | 200K tokens | 1M tokens |
| Max output | 384K tokens | 32K tokens | 128K tokens |
| Thinking mode | Yes (3 effort levels) | Yes (extended thinking) | Yes (xhigh reasoning) |
| Tool use | Yes | Yes | Yes |
| Computer use | Not documented | No | Yes (OSWorld 78.7%) |
| Multimodal input | Text + image | Text + image | Text + image |
Opus 4.6's 200K context is the ceiling that matters most for teams loading large codebases in a single pass. At 200K, you can fit most mid-size repos but not large monorepos. V4-Pro and GPT-5.5 both hit 1M, which opens up different use cases — not just bigger repos, but longer accumulated tool-call history in agentic loops.
Cost and deployment trade-offs
| DeepSeek V4-Flash | DeepSeek V4-Pro | Claude Opus 4.6 | GPT-5.5 | |
|---|---|---|---|---|
| Input ($/1M) | $0.14 | $1.74 | $5.00 | $5.00 |
| Output ($/1M) | $0.28 | $3.48 | $25.00 | $30.00 |
| 10M output tokens/month | $2.80 | $34.80 | $250 | $300 |
| Self-host option | ✅ | ✅ | ❌ | ❌ |
At production agent scale — 50M+ output tokens per month — the cost gap between DeepSeek V4-Pro and Opus 4.6 is roughly 7× on output. Between V4-Flash and GPT-5.5, it's 100×. These aren't rounding errors; they change what agent workflows are financially viable to run at high frequency.
Where DeepSeek V4 Wins
Open-weight flexibility
This is the uncontested dimension. No other model in this comparison offers MIT-licensed weights you can download, modify, fine-tune, and deploy without a vendor relationship. For teams with strict data residency requirements, regulated-industry compliance constraints, or a strategic preference for infrastructure independence, V4-Pro is currently the strongest open-weight coding model available — larger than Kimi K2.6 (1.1T vs 1.6T parameters) and with a more recent training cutoff than DeepSeek V3.2.
Fine-tuning is also exclusively V4's territory here. If your coding workflow benefits from domain adaptation — codebase-specific patterns, internal API conventions, proprietary framework idioms — you can fine-tune V4-Flash on your data in ways that Opus 4.6 and GPT-5.5 don't allow.
Cost-sensitive agentic workflows
At $1.74/$3.48 for V4-Pro and $0.14/$0.28 for V4-Flash, DeepSeek is pricing for teams where token economics limit what's feasible. Retry-heavy agentic loops, multi-pass code review pipelines, and high-concurrency developer tooling all benefit from per-token costs that don't compound into budget constraints. The workflows that hit GPT-5.5 or Opus 4.6 budget ceilings may run continuously on V4-Flash.
The caveat: lower cost per token only wins if quality is sufficient for your task type. V4-Pro's self-reported benchmark positioning (between GPT-5.2 and GPT-5.4 on standard evaluations) is plausible for many production coding tasks. Whether it's sufficient for yours requires your own workload testing — not the launch benchmarks.
Where Claude Opus 4.6 Wins
Complex refactors and reasoning-heavy coding
Anthropic's RLHF tuning for coding behavior shows up most clearly in tasks that require inferring developer intent from ambiguous requirements, reasoning through multi-file architectural decisions, and producing code that follows existing patterns rather than inventing new ones. This is harder to benchmark than SWE-Bench scores capture.
On SWE-Bench Pro — real GitHub issue resolution, single-pass — Opus 4.6 scored 53.4%. Claude Opus 4.7 scores 64.3% at the same price. The honest picture: if complex reasoning is why you're on Claude, Opus 4.7 is the current expression of that bet. Opus 4.6 remains competitive but is no longer the frontier within the Anthropic family.
The 200K context ceiling is the practical constraint against V4-Pro and GPT-5.5. For the majority of coding tasks, 200K is more than sufficient. For loading entire large codebases in a single pass without chunking, it isn't.
Where GPT-5.5 Wins
Tool use and messy multi-step work
Terminal-Bench 2.0 at 82.7% is the benchmark where GPT-5.5 most clearly leads this comparison. Terminal-Bench measures exactly what the framing claims — planning, iteration, tool coordination across complex command-line workflows. If your coding agents call tools dozens or hundreds of times per task, this number is more relevant to your decision than SWE-Bench Verified.
Computer use (OSWorld-Verified: 78.7%) is exclusively GPT-5.5's terrain here. Neither Opus 4.6 nor DeepSeek V4 documents equivalent capability in their official materials. For agent workflows that interact with browsers, IDEs, or GUIs as part of their execution path, GPT-5.5 is the only option in this comparison with a published and documented capability.
The cost argument for GPT-5.5 vs Opus 4.6 is narrower than it looks: both are $5/M input, but GPT-5.5 is $30/M output vs Opus 4.6's $25/M. Output costs favor Opus 4.6 for output-heavy workloads. GPT-5.5's edge is performance, not price.
Why the Benchmarks Need Caution
Official claims vs independent evals
All benchmark numbers in this comparison carry provenance limitations:
| Model | Benchmark source | Independent validation |
|---|---|---|
| DeepSeek V4-Pro | DeepSeek self-reported, launch week | None published at time of writing |
| Claude Opus 4.6 | Anthropic self-reported | SEAL leaderboardputs SWE-Bench Pro at 51.9% vs Anthropic's 53.4% |
| GPT-5.5 | OpenAI self-reported | Artificial Analysis confirms top-tier overall; specific benchmark replication limited |
V4's numbers have had the least independent scrutiny — the model is four days old at the time this comparison was written. DeepSeek's Codeforces rating (3,206, approximately rank 23 among humans) is a credible competitive programming data point. The claim that V4-Pro sits between GPT-5.2 and GPT-5.4 on standard benchmarks comes from third-party analysis at launch, not DeepSeek's own documentation.
Cross-harness comparisons are not clean
The most important limitation: Terminal-Bench 2.0 numbers for these models were not all generated under the same harness. GPT-5.5's 82.7% uses OpenAI's evaluation setup. Claude Opus 4.6's 65.4% uses Anthropic's. DeepSeek V4 has not published a Terminal-Bench 2.0 score at all. Cross-harness comparisons on this benchmark have shown deltas of 5–10 points in prior evaluations — enough to invert rankings. Don't use Terminal-Bench numbers from different sources to rank these models against each other.
For SWE-Bench Pro, both Anthropic and DeepSeek have published numbers, but the agent scaffolding differs. The numbers are directionally useful; treat them as ±3–5 points relative to each other.
Decision Framework
If you want open deployment
DeepSeek V4 is the only option. If data residency, compliance, fine-tuning, or infrastructure independence are requirements, the choice is made before you look at any benchmark. Test V4-Flash first (faster iteration, lower compute requirements, comparable to V4-Pro on simpler tasks). Move to V4-Pro if V4-Flash falls short on quality. Plan for behavior changes before final release.
If you want best-in-class reasoning
Claude Opus 4.7 (not 4.6) is the current answer if you're choosing within the closed-API space for reasoning-heavy coding tasks. Opus 4.7 costs the same as Opus 4.6 and scores 87.6% on SWE-Bench Verified vs 80.8% for 4.6. If you're committed to Opus 4.6 for regression risk reasons, that's a valid operational decision — but not a quality-maximizing one. For teams where Anthropic's instruction-following behavior and existing prompt engineering investment matters more than frontier benchmark scores, staying on 4.6 has lower switching cost.
If you want tool-using execution today
GPT-5.5 is the answer for workflows that depend on tool coordination over long task sequences and for anything involving computer use. The Terminal-Bench 2.0 lead is real. The $30/M output cost is also real — for output-heavy workloads at scale, this adds up faster than Opus 4.6 or DeepSeek.
FAQ
Is DeepSeek V4 better than Claude for coding?
On independent benchmarks: not established yet. DeepSeek V4's launch numbers are self-reported and unverified by third parties at time of writing. On the open-source field, V4 is the current leader. Against Opus 4.6 and GPT-5.5 specifically, the comparison depends heavily on task type and harness — and the answer will be clearer in 3–4 weeks when independent evaluations catch up to the release. Test on your own workloads rather than waiting for a consensus benchmark.
Is GPT-5.5 available in the API?
Yes, since April 24, 2026. Model IDs: gpt-5.5 and gpt-5.5-pro. Standard pricing is $5/$30 per million tokens. Both the Responses API and Chat Completions API support it. Context window is 1M tokens (up to 922K input, 128K output). See our full GPT-5.5 review for the complete breakdown.
Should teams run all three in one workflow?
For specialized workflows, yes — the models have complementary strengths. A reasonable routing pattern: V4-Flash for high-volume, lower-complexity agent tasks where cost dominates; GPT-5.5 for tool-coordination and computer-use steps; Opus 4.6 (or 4.7) for reasoning-intensive code review and architecture decisions. The overhead of managing multiple API keys and routing logic is real, but for teams where cost and capability both matter, model routing is increasingly standard practice. External orchestration frameworks handle the routing layer without requiring hand-coded model selection per request.
Conclusion
The three-way comparison resolves into different slots faster than the benchmark table suggests. DeepSeek V4 wins on open-weight access and cost economics — by a margin large enough that it changes workflow designs, not just line items. GPT-5.5 wins on tool-coordination performance for messy multi-step work. Opus 4.6 wins on reasoning depth for ambiguous, complex coding tasks — though Opus 4.7 now does that better at the same price.
The benchmark caution is real: don't cross-harness compare Terminal-Bench numbers, don't treat V4's self-reported launch data as settled, and don't conflate "open-source SOTA" with "better than GPT-5.5 or Opus 4.7." The right model for your team is the one that clears your quality bar on your actual workloads at a cost that makes the workflow financially viable. For most teams, that means testing V4-Flash against your current provider before committing to either the open-weight path or the closed-model premium.
Related Reading
