
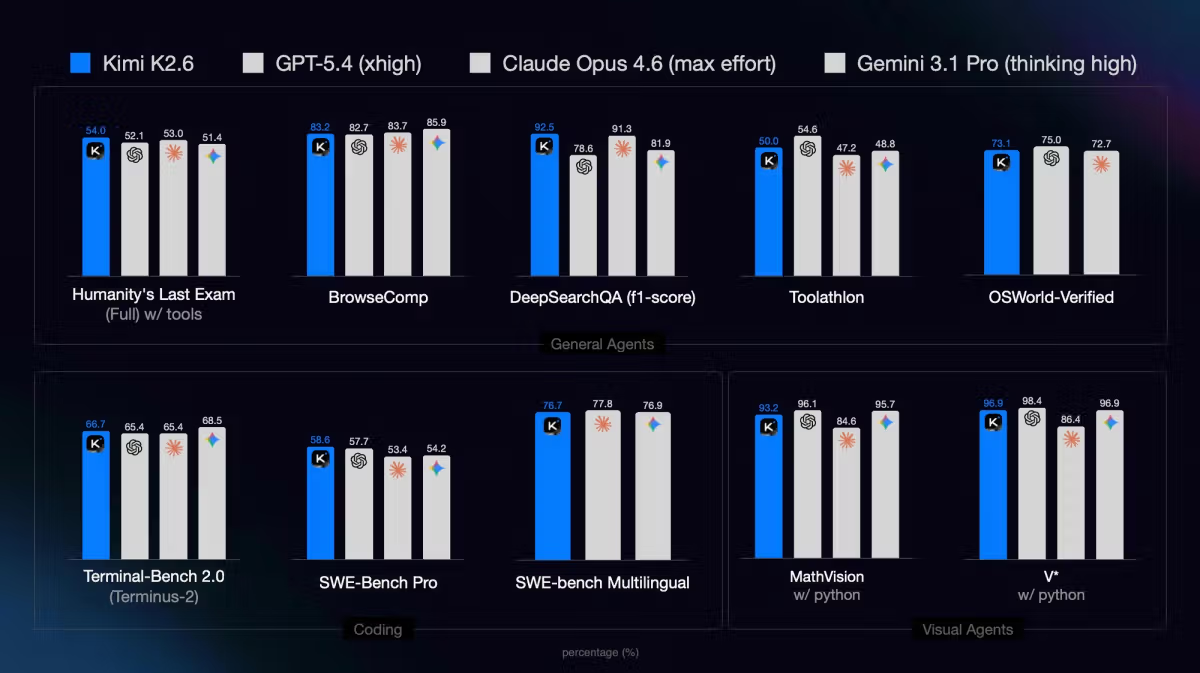
Moonshot AI, Kimi K2.6'yı 20 Nisan 2026'da yayımladı: 1 trilyon parametre, 32B aktif, open-weight, native multimodal, hızlı chat'ten 300 agent'lı paralel swarm'lara uzanan dört varyant. Çok adımlı coding agent'ları çalıştırıyorsan ya da Claude ve GPT-5.4'e open-weight alternatifler değerlendiriyorsan, bunu anlamaya değer. Değilsen, acil değil.
Aşağıda mimari, dört varyant, K2.5'ten gerçekte ne değişti, lisans koşulları ve dürüst limitler var.
Tek Paragrafta Kimi K2.6

Kimi K2.6, Pekin merkezli Moonshot AI'dan 1 trilyon parametreli bir Mixture-of-Experts modeli — Modified MIT Lisansı altında open-weight yayımlandı. Çıkarım sırasında token başına 32 milyar parametre aktive ediyor, 262.144 token context penceresi destekliyor ve native INT4 quantization ile geliyor. Model ayrı görü modülleri olmadan aynı mimaride metin, görüntü ve videoyu işliyor. Dört varyant farklı kullanım senaryolarını kapsıyor: hız için Instant, derin akıl yürütme için Thinking, otonom araştırma ve belge görevleri için Agent ve büyük ölçekli paralel çalışma için Agent Swarm. Ağırlıklar Hugging Face'te, API ise platform.moonshot.ai adresinde.
Mimariye Hızlı Bakış
1T MoE, 32B aktif, 384 uzman
K2.6, K2 ve K2.5 ile aynı çekirdek mimariyi devralıyor: 384 toplam uzmandan oluşan seyrek Mixture-of-Experts tasarımı; token başına 8'i yönlendiriliyor artı 1 paylaşımlı uzman. Bu ona yaklaşık 32B yoğun model çıkarım maliyetiyle 1T parametreli bir modelin parametre genişliğini veriyor. Mimari, Moonshot'ın trilyon parametre ölçeğinde eğitimi stabilize etmek için orijinal olarak K2 için geliştirdiği Muon optimizer'ı (MuonClip) kullanıyor — MoE modelleri bu boyutta dikkat patlamalarına ve kayıp sıçramalarına eğilimli ve MuonClip bunları önlemek için inşa edildi.
SwiGLU (Swish-Gated Linear Unit) aktivasyon fonksiyonu olarak kullanılıyor — önceki alternatiflere kıyasla daha donanım verimli ve Meta'nın Llama serisi dahil birkaç başka önemli open-weight ailesi tarafından kullanılıyor.
256K context, MLA, INT4
Pratik context penceresi 262.144 token. Moonshot'ın K2.5'e kıyasla belirttiği iyileştirme boyut değil — K2.5'te zaten 256K vardı — bu uzunlukta kararlılık. Uzun vadeli kodlama görevleri context dolunca bozulma eğiliminde; K2.6 bu bozulmayı spesifik olarak hedefliyor.
| Kapasite | K2.5 | K2.6 |
|---|---|---|
| Maks paralel subagent | 100 | 300 |
| Maks araç çağrısı adımı | 1.5 | 4 |
| Maks otonom çalışma süresi | Belirtilmemiş | 12+ saat |
| Video girişi | Hayır | Evet |
| Mimari | Aynı K2 MoE tabanı | Aynı K2 MoE tabanı |
Multi-head Latent Attention (MLA), uzun context'lerde ve multi-agent kurulumlarında önem taşıyan KV cache'in bellek ayak izini standart multi-head attention'a kıyasla azaltıyor.
INT4 quantization native: Moonshot, post-training aşamasında Quantization-Aware Training (QAT) kullandı; bu modelin sonradan sıkıştırılmak yerine 4-bit ağırlıklarla uyumlu temsiller öğrendiği anlamına geliyor. Pratik sonuç FP16'ya kıyasla yaklaşık 2× çıkarım hızı ve %50 daha az GPU belleği; Moonshot ihmal edilebilir kalite kaybı iddia ediyor. INT4 ağırlıkları Hugging Face'te yaklaşık 594GB geliyor.
Dört Varyant ve Her Birinin Ne Zaman Uygun Olduğu
Moonshot, K2.6'yı kimi.com ve API üzerinden erişilebilir dört varyant olarak sunuyor. Aynı model ağırlıklarını paylaşıyorlar ama decoding yapılandırması, araç izinleri ve thinking bütçesinin tahsisi bakımından farklılıklar var.
K2.6 Instant
Akıl yürütme izi olmadan hızlı yanıtlar. Temperature daha düşük çalışıyor, top-p daha sıkı ve model chain-of-thought aşamasını tamamen atlıyor. Pratik kullanım senaryosu hızlı aramalar, kısa kod tamamlamaları ve derinlikten çok gecikmenin önemli olduğu her şey. Otomatik tamamlama veya basit bir Q&A yüzeyi inşa ediyorsan doğru giriş noktası bu.
K2.6 Thinking
Tam akıl yürütme modu. Model chain-of-thought'u araç çağrılarıyla birlikte işliyor, çıktı üretmeden önce akıl yürütme izine bir hesaplama bütçesi tahsis ediyor. K2.6'nın benchmark skorlarını üreten bu varyant — Hugging Face model kartı, tüm K2.6 değerlendirmelerinin thinking modu etkinken yapıldığını not ediyor. Karmaşık debug, mimari kararlar, çok dosyalı kod analizi veya modelin hareket etmeden önce akıl yürütmesini istediğin her şey için kullan.
K2.6 Agent
Tam araç erişimiyle otonom görev yürütme: web araması, kod yorumlayıcısı, dosya işlemleri ve tarayıcı. Hedeflenen kullanım senaryoları araştırma, belge oluşturma (slaytlar, raporlar, tablolar), prompt'tan website oluşturma ve modele görev değil hedef verdiğin çok adımlı iş akışları. Bu "bu soruyu cevapla"dan çok "bu projeyi çalıştır"a daha yakın.
K2.6 Agent Swarm
En operasyonel olarak ayrışık varyant. Agent Swarm, her biri 4.000'e kadar koordineli adım yapabilen 300 paralel subagent'a yatay ölçekleniyor ve tam çalışma 12 saati aşabiliyor. Karmaşık bir prompt paralel, alana özel alt görevlere ayrıştırılıyor — araştırma, analiz, kodlama, tasarım — her biri dinamik olarak örneklenen bir agent tarafından işleniyor, sonuçlar baş orkestratör tarafından entegre ediliyor.
Agent Swarm, Agent'ın genel amaçlı bir yükseltmesi değil. Farklı bir operasyonel model: büyük, ayrıştırılabilir bir hedef verip çalışmasına izin veriyorsun. 300 subagent başlatıp koordine etmenin ek yükü, tek bir agent'ın dakikalar içinde yapabileceği görevler için buna değmiyor. Tek bir agent'ın ardışık saatler alacağı toplu görevler, uzun biçimli çıktı veya büyük ölçekli arama için tasarlanmış.
K2.5'e Kıyasla Gerçekte Ne Değişti

300 subagent, 12 saatlik yürütme, native multimodal
Ocak 2026'da yayımlanan K2.5, Agent Swarm'u kavram olarak tanıttı: paylaşılan bir hedefe doğru koordine olan öz yönlendirmeli paralel agent'lar. K2.6 tavanı önemli ölçüde genişletiyor.
Mimari değişmedi — Hugging Face'deki K2.6 dağıtım rehberi açıkça "Kimi-K2.6, Kimi-K2.5 ile aynı mimariye sahip ve dağıtım yöntemi doğrudan yeniden kullanılabilir" diyor. Fark post-training'de: uzun vadeli kararlılık, talimat takibi ve swarm koordinasyonu için uygulanan daha fazla eğitim hesabı. Moonshot K2.6 için tam olarak ne kadar ek eğitim yapıldığını açıklamadı.
Native video girişi diğer dikkat çekici eklenti. K2.5 görüntüleri işliyordu; K2.6 video ekliyor (mp4, mov, avi, webm ve diğerleri, 2K çözünürlüğe kadar önerilen). Görü kodlayıcı modelin ön eğitimine natifte dahil — sonradan eklenen bir modül değil.
Frontend animasyonu ve WebGL shader oluşturma da Moonshot'ın lansman materyallerinde öne çıkıyor — model metin prompt'larından video hero bölümleri, GLSL/WGSL shader animasyonları ve GSAP tabanlı motion tasarımı üretebiliyor. Bu K2.5'in genel frontend kodlama yeteneğine spesifik bir kapasite eklentisi.
Kimin Dikkat Etmesi Gerekiyor
Senior devler, Tech Lead'ler, uzun vadeli agent çalıştıran ekipler
K2.6 daha iyi bir chatbot olmaya çalışmıyor. Farklılaşması dar ve kasıtlı: halihazırda zaman alan görevlerde AI agent'ları çalıştıran veya planlamayı düşünen geliştirici ve ekipler için bir model — kod migration'ları, büyük refactoring'ler, çok adımlı araştırma, altyapı otomasyonu. İş akışın bir görevi tamamlamak için 50 kez araç çağıran bir agent içeriyorsa K2.6 alakalı. Bir fonksiyonu modele açıklatıyorsan değil.
Open-weight yayımı iki spesifik kitle için önemli. Veri egemenliği gereksinimleri olan ekipler — düzenlenmiş sektörler, güvenlik hassasiyetli codebase'ler — K2.6'yı kendi altyapılarında çalıştırabilir. Yüksek hacimli çıkarım yapan ekipler self-host yapıp sürdürülen iş yükleri için token başına API fiyatlandırmasından kaçınabilir. Diğerleri için platform.moonshot.ai'daki API, operasyonel karmaşıklık olmadan aynı yetenekleri kapsıyor.
Moonshot API'sindeki fiyatlandırma, karşılaştırılabilir görevler için Claude Opus 4.6 ve GPT-5.4'den anlamlı ölçüde düşük. Çalışma başına binlerce araç çağrısı yakan agent iş akışları için bu fark birleşiyor. Kullanım senaryonun kalite takasını kabul edip edemeyeceği gerçek iş yüklerine karşı test gerektirir — benchmark'lara değil.
Bilinen Limitler ve Açık Sorular
Donanım gereksinimleri önemli. K2.6'yı tam kalitede yerel çalıştırmak production için 8× H100 veya H200 GPU gerektiriyor. INT4 varyantı azaltılmış context uzunluğunda 4× H100'de çalışabiliyor. Community deneyleri modelin tüketici donanımında (her biri 512GB RAM'li çift Mac Studios) çalıştığını gösteriyor — yapılandırmaya bağlı saniyede yaklaşık 1-7 token gibi çok düşük bir throughput ile; çoğu gerçek iş akışı için pratik değil. Cloud API'leri çoğu ekip için gerçekçi dağıtım yolu.
Benchmark sayıları lansmanda kendi beyanları. Hugging Face model kartı, kamuya açık skorları olmayan benchmark'ların Moonshot tarafından K2.6 için kullanılan aynı koşullar altında yeniden değerlendirildiğini ve yıldızla işaretlendiğini not ediyor. K2.6'nın benchmark iddialarının bağımsız üçüncü taraf doğrulaması haftalar alacak. Uzun vadeli agent iddiaları (12 saatlik çalışmalar, 4.000 araç çağrısı) ölçekte hızla replikasyonu özellikle zor.
Jeopolitik bağlam. Moonshot AI Çinli bir şirket ve K2.6'nın lansmanı ABD pazarında Çinli AI firmalarına yönelik süregelen inceleme döneminde geliyor. ABD Temsilciler Meclisi, uluslararası alanda faaliyet gösteren Çinli AI şirketlerini etkileyebilecek mevzuatı değerlendiriyor. Uyumluluk gereksinimleri olan ekipler için vendor yargı bölgesi teknik kapasitenin yanında alakalı bir faktör.
Claw Groups önizleme özelliği. Otonom bir çalışmanın belirli alt görevler için insan çalışanları dahil edebildiği insan-makine işbirliğini mümkün kılan "Claw Groups" işlevi, lansmanda genel erişilebilir bir kapasite değil, araştırma önizlemesi olarak listeleniyor.
Sık Sorulan Sorular
Kimi K2.6 ücretsiz mi?

Ağırlıklar Modified MIT Lisansı altında indirmek ve kullanmak için ücretsiz. kimi.com chat arayüzü kullanım limitleriyle ücretsiz (Moonshot Moderato, Allegretto ve Vivace adlı abonelik tier'ları sunuyor). platform.moonshot.ai üzerinden API erişimi token başına ücretli. Open-weight modelin kendisi için koltuk başına ücret yok.
Kimi K2.6'yı yerel olarak nerede çalıştırabilirim?
Ağırlıklar Hugging Face'te (moonshotai/Kimi-K2.6). Üç çıkarım motoru resmi olarak K2.6'yı destekliyor: vLLM, SGLang ve KTransformers (Moonshot'ın K2 mimarisi için inşa ettiği kendi motoru). Model kartındaki dağıtım rehberi kararlı production kullanımı için vLLM 0.19.1'i öneriyor. Pratik kullanım için minimum uygulanabilir donanım azaltılmış context uzunluğunda INT4 quantization ile 4× H100. Mimari K2.5 ile özdeş, yani mevcut K2.5 dağıtım yapılandırmaları doğrudan aktarılıyor — model ağırlıklarını değiştir.
Modified MIT Lisansı ticari kullanım için nasıl çalışıyor?
Lisans, bir değişiklikle standart MIT: K2.6'yı (veya türevini) aylık 100 milyon aktif kullanıcıyı aşan veya aylık 20 milyon USD'den fazla gelir elde eden ticari bir ürün veya hizmette dağıtıyorsan, o ürünün kullanıcı arayüzünde "Kimi K2.6"yı belirgin biçimde göstermelisin. Bu eşiklerin altında lisans standart MIT olarak işlev görüyor — ticari kullanım, değiştirme, yeniden dağıtım, telif hakkı yok. Eşikler potansiyel kullanıcıların küçük bir fraksiyonunu etkiliyor. İyi finanse edilmiş girişimler dahil çoğu ekip her iki limitin de çok altında.
Kimi K2.7 yakında geliyor mu?
K2.7'nin resmi duyurusu yok. K2 serisi hızlı ilerledi — Temmuz 2025 ile Nisan 2026 arasında beş önemli sürüm — ama Moonshot bir yol haritası açıklamadı. Reddit'in r/LocalLLaMA'sında Moonshot'ın geçici olarak Kimi K3 diye anılan bir model üzerinde çalıştığına dair community tartışması var; parametre sayısının 3–4 trilyon aralığında olduğuna dair spekülasyonlar mevcut. Bunlar doğrulanmamış community söylentileri, resmi bilgi değil. Moonshot bir şeyi teyit edene kadar spekülasyon olarak değerlendir.
K2.6, Claude Opus 4.6 ve GPT-5.4 ile genel düzeyde nasıl karşılaştırılıyor?
Agentic ve araç ağırlıklı benchmark'larda (SWE-bench Pro, BrowseComp, araçlarla HLE), K2.6 Moonshot'ın kendi beyan ettiği sayılara göre lansmanında her ikisiyle rekabetçi ya da önde. Salt tek turlu akıl yürütme görevlerinde (araçsız AIME, GPQA Diamond), GPT-5.4 ve Gemini 3.1 Pro şu an önde. Claude Opus 4.7, K2.6 ile aynı haftada yayımlandı ve Opus 4.6'nın üzerinde; doğrudan K2.6 vs. Opus 4.7 karşılaştırmaları K2.6'nın lansman benchmark'larında yok. Pratik çerçeveleme: K2.6, çok adımlı agent görevleri ve maliyete duyarlı iş yükleri için güçlü; tek seferlik karmaşık akıl yürütmede mevcut özel modeller hâlâ önde. Bağımsız benchmark'lar önümüzdeki haftalarda tabloyu netleştirecek.
Net konuşmak gerekirse: K2.6, maliyet kontrolü, veri egemenliği veya her ikisine ihtiyaç duyan uzun vadeli agent çalışması yapan ekipler için yetenekli bir open-weight model. Teknik farklılaşması — 300 agent swarm, 12 saatlik otonom çalışmalar, native multimodal — gerçek ama özelleşmiş. Günlük geliştirme çalışması için basit coding asistanlarının yerini almayacak ve tüketici donanımında ucuza çalışmayacak. Ölçekte agentic coding pipeline'larını çalıştırıyor veya değerlendiriyorsan, test etmeye değer. Değilsen, acelesiz takip edilecek bir model.
İyi kodlamalar.
