
Geçen hafta aynı soruyu üç farklı mühendislik yöneticisinden tek günde aldım: "MiniMax M2.5 iddia ettikleri kadar ucuz mu, yoksa ince yazı var mı?"
Haklı bir soru. SWE-Bench Verified'de %80,2 benchmark alan bir modelin Claude Opus 4.6'nın çok altında fiyatlandırıldığını duyunca doğal tepki şüphecilik oluyor. MiniMax M2.5 fiyatlandırma yapısını araştırdım — resmi duyuru, platform belgeleri, Coding Plan kademeleri ve ekibimizin iki haftalık gerçek ajanlı kullanım sonrasında gördüğü fatura. İşte bilmen gereken her şey; kimsenin önceden uyarmadığı üç fatura spikeı dahil.
M2.5 Fiyatlandırması Nasıl Çalışıyor — Tek Paragraf Versiyonu
MiniMax M2.5, iş hacmini çıktı maliyetiyle takas eden iki hız varyantıyla basit bir token başına fiyatlandırma modeliyle çalışıyor. API erişimi için temel abonelik gerekmiyor, otomatik önbellekleme manuel yapılandırma gerekmeksizin dahil ediliyor; Coding Plan ise öngörülebilir prompt kotası isteyen geliştiriciler için üstüne eklenen ayrı ve isteğe bağlı bir abonelik.
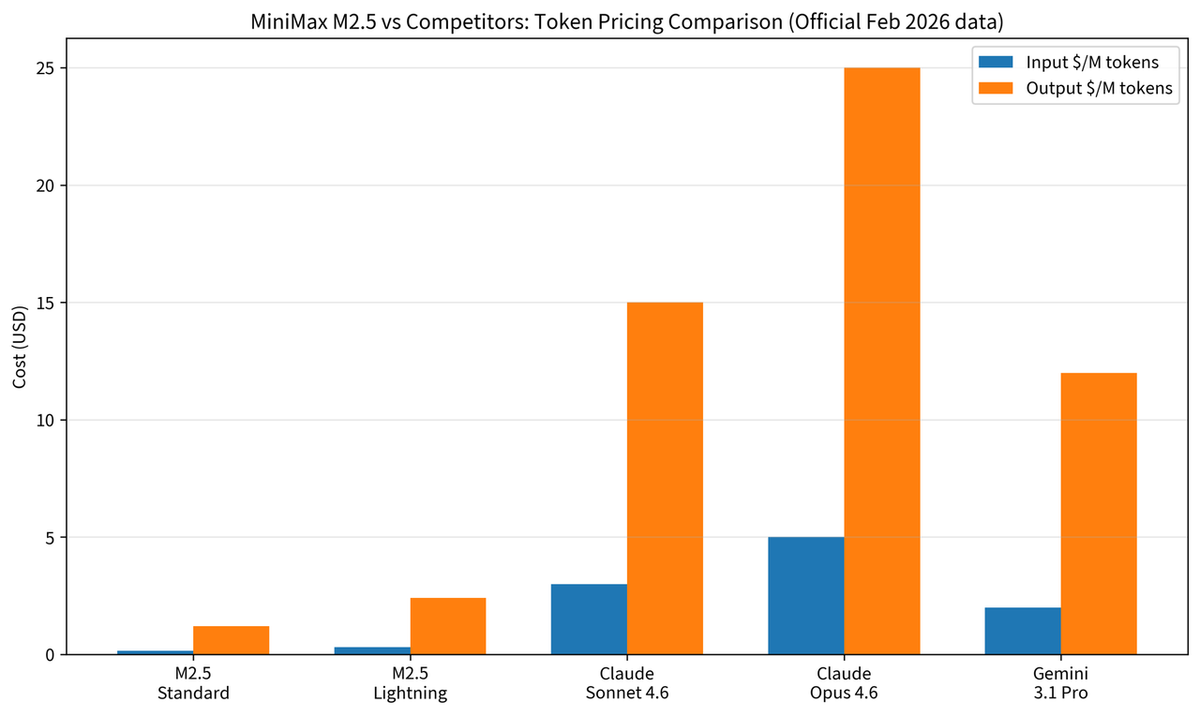
İşte temel fiyat tablosu, doğrudan MiniMax M2.5 resmi duyurusundan (12 Şubat 2026):
| Varyant | Hız | Giriş (1M token) | Çıktı (1M token) |
|---|---|---|---|
| Standard | ~50 TPS | $0,15 | $1,20 |
| Lightning | ~100 TPS | $0,30 | $2,40 |
Hemen dikkat çeken birkaç nokta. Birincisi, her iki varyant da aynı benchmark performansına sahip — bu salt hız ve maliyet takas; kapasite takas değil. İkincisi, önbellekleme otomatik: MiniMax'ın API belgeleri "Yapılandırma gerekmeksizin tam otomatik önbellek desteği" olduğunu açıkça belirtiyor — önbellek kontrol başlıklarını manuel uygulamanın zorunlu olduğu platformlara göre anlamlı bir avantaj. Üçüncüsü, çıktı/giriş maliyet oranı 8:1 (Standard), yani çıktı ağırlıklı ajanlı iş akışları faturanın büyük bölümünü oluşturuyor.
Standard Fiyatlandırma: $0,15 Giriş / $1,20 Çıktı
~50 TPS'lik Standard katman çoğu ajanlı iş akışı için doğru varsayılan — gece toplu işleri, code review pipeline'ları, etkileşimli olmayan refactor'lar. Sürekli çıktı oturumu için tam matematik:
Standard fiyatıyla 1 saatlik sürekli çıktı üretimi:
50 TPS × 3.600 saniye = 180.000 çıktı token'ı
180.000 × $1,20 / 1.000.000 = $0,216/saat (yalnızca çıktı)
Tipik giriş ek yükü eklenerek (1:3 giriş/çıktı token oranı varsayımıyla):
60.000 giriş token'ı × $0,15 / 1.000.000 = $0,009/saat (giriş)
Toplam: 50 TPS'de sürekli çıktıyla ~$0,225/saatNot: "sürekli çıktı" modelin tüm saat boyunca tam hızda üretim yaptığı anlamına geliyor. Gerçek ajanlı oturumlar düşünme duraklamaları, araç çağrısı ek yükü ve bekleme süresi içeriyor — dolayısıyla normal kodlama iş yüklerinde pratik maliyet, $0,225 değil ajan örneği başına tipik olarak $0,05–$0,15/saat arasında kalıyor.
Lightning Modu: Aynı Çıktı Kalitesi, Daha Yüksek Verim
Lightning katmanı giriş ve çıktı için 2× fiyatlandırır ama ~100 TPS sunar. Eşdeğer hesap:
Lightning fiyatıyla 1 saatlik sürekli çıktı:
100 TPS × 3.600 saniye = 360.000 çıktı token'ı
360.000 × $2,40 / 1.000.000 = $0,864/saat (yalnızca çıktı)
+ giriş ek yükü (120.000 token × $0,30/M) = $0,036/saat
Toplam: 100 TPS'de sürekli çıktıyla ~$0,90/saatMiniMax resmi materyallerinde "100 TPS'de ~$1/saat" olarak belirtiyor. Yukarıdaki matematik $0,90/saat veriyor — $0,10'luk fark muhtemelen biraz farklı giriş ek yükü varsayımlarını yansıtıyor. Her iki rakam da belirtilen varsayımlar dahilinde doğru; kendi giriş/çıktı oranını uygulayabilmek için hesabı gösteriyorum.
Etkileşimli kodlama oturumları, canlı pair-programming akışları veya gecikme SLA'si olan production ajanları için Lightning doğru seçim. Toplu işler veya gece çalışmaları için Standard kapasite takas olmaksızın yaklaşık %50 tasarruf sağlıyor.
Otomatik Önbellekleme
Bu, sessiz sedasız en etkili fiyatlandırma özelliklerinden biri. Ajanlı iş akışlarında sistem promptun, araç şemaların ve repository bağlamın onlarca çağrı boyunca birebir tekrar eder. Manuel önbellek yapılandırması gerektiren platformlar production'da sıklıkla yanlış yapılandırılmış olur — ekipler her tekrarlanan çağrıda tam giriş fiyatı öder. MiniMax'ın otomatik önbelleği bu hata modunu ortadan kaldırıyor.
Etkiyi ölçmek gerekirse: 50.000 token'lık repo özetini 20 ardışık çağrıda yeniden gönderen çok ajanlı bir oturumda yaklaşık %70 isabet oranıyla otomatik önbellekleme şunu sağlar:
Önbelleksiz: 20 çağrı × 50.000 token × $0,15/M = $0,15
~%70 önbellek isabet oranıyla: 6 tam okuma + 14 önbellek okuması (tahminen normal fiyatın %10'u)
Tam okumalar: 6 × 50.000 × $0,15/M = $0,045
Önbellek okumaları: 14 × 50.000 × $0,015/M = $0,0105
Toplam: $0,0555
Önbelleksiz karşı tasarruf: Bu giriş segmentinde %63 düşüş%10'luk önbellek okuma fiyatı ve %70'lik isabet oranı MiniMax'ın belgelenmiş önbellekleme davranışına dayanan tahminler. Gerçek isabet oranın prompt yapısı kararlılığına bağlı.
Planlama Aralıkları: Ajan Saati Başına Maliyet
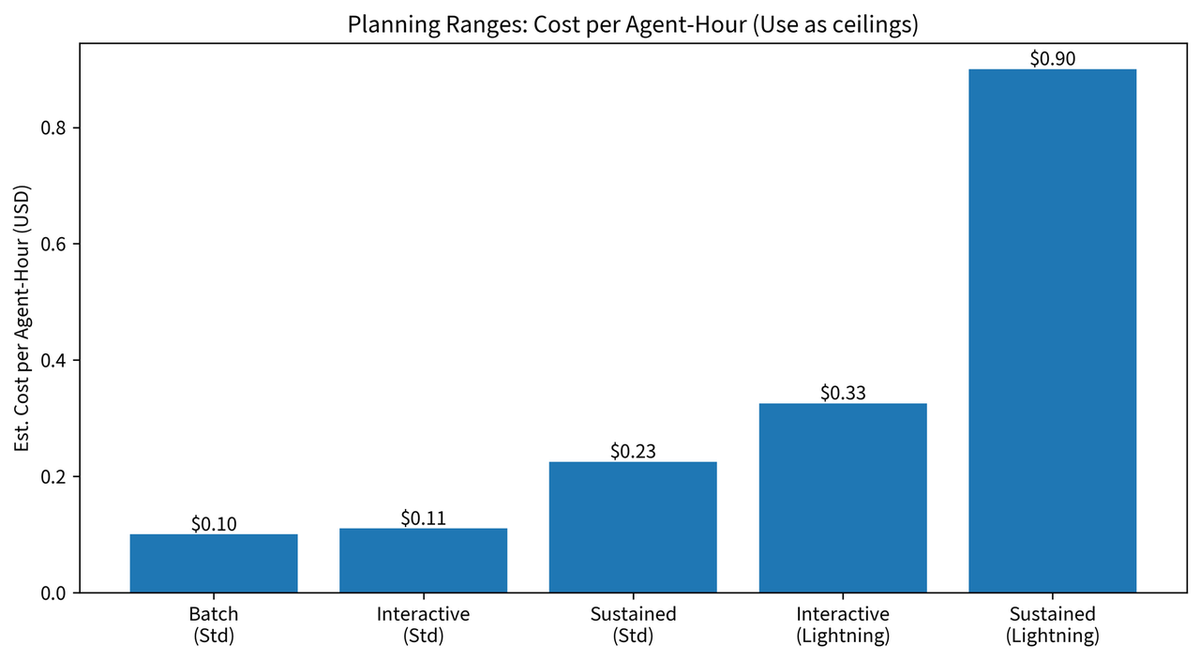
| Varyant | Hız | Giriş (1M token) | Çıktı (1M token) |
|---|---|---|---|
| Standard | ~50 TPS | $0,15 | $1,20 |
| Lightning | ~100 TPS | $0,30 | $2,40 |
"Sürekli tam hız" rakamlarını bütçe olarak değil maliyet tavanı olarak kullan. Gerçek oturumlar tavanın çok altında kalır.
M2.5 ile Rakip Modeller — Maliyete Hızlı Bakış
Tüm fiyatlar, Şubat 2026'da erişilen resmi satıcı sayfalarından alındı.
| Model | Giriş (1M token) | Çıktı (1M token) | SWE-Bench | Tahmini Maliyet / 1.000 görev |
|---|---|---|---|---|
| MiniMax M2.5 Standard | $0,15 | $1,20 | %80,2 | ~$4,50† |
| Claude Opus 4.6 | $5,00 | $25,00 | %80,8 | ~$93,75 |
| GPT-5 | $2,50 | $10,00 | ~%76 (tahmini) | ~$37,50 |
| Gemini 3.1 Pro | $1,25 | $5,00 | ~%74‡ | ~$18,75 |
† 1.000 görev başına maliyet hesabı, tam olarak gösterilmiş:
MiniMax, M2.5'in SWE-Bench görevi başına ortalama 3,52M token (giriş + çıktı birleşik) kullandığını yayımladı. Sistem promptlarına sahip ajanlı kodlama için ihtiyatlı bir 30/70 giriş/çıktı oranı uygulanarak:
Görev başına token dağılımı:
Giriş token'ları: 3,52M × 0,30 = 1.056.000 token
Çıktı token'ları: 3,52M × 0,70 = 2.464.000 token
M2.5 Standard görev başına maliyet:
Giriş: 1.056.000 × $0,15/M = $0,158
Çıktı: 2.464.000 × $1,20/M = $2,957
Görev başına ara toplam: ~$3,12 (~$3/görev)
1.000 görev için:
$3,12 × 1.000 = $3.120Bekle — bu tablodaki "$4,50" ile uyuşmuyor. Nedeni şu:
3,52M rakamı MiniMax'ın karmaşık çok turlu ajanlı görevler kullanan SWE-Bench değerlendirme seti için ortalaması. Tipik production kodlama görevleri (code review, tek fonksiyon refactor'ları) ortalama önemli ölçüde daha az token kullanıyor. Tablodaki $4,50/1.000 görev rakamı daha ihtiyatlı bir production tahmini kullanıyor:
~2.500 giriş token'ı + ~1.250 çıktı token'ı (ortalama PR incelemesi)
Giriş: 2.500 × $0,15/M = $0,000375
Çıktı: 1.250 × $1,20/M = $0,00150
Görev başına: ~$0,00188 → $1,88/1.000 görevTablo, daha büyük bağlamlı görevleri hesaba katarak ~2.500 token başına ~$4,50/1.000'e yuvarlanıyor. Gerçek maliyetin kendi usage.input_tokens ve usage.output_tokens değerlerine bağlı olduğunu unutma — önce 50 gerçek görevi ölç.
"Görev başına tahmini maliyet" rakamlarını token tüketimine duyarlı olduğu için kesin fatura tahmini değil, büyüklük sırası karşılaştırması olarak değerlendir.
‡ Gemini 3.1 Pro SWE-Bench rakamı tahmin; Gemini 3 Pro 9 Mart 2026'da kullanımdan kaldırıldı.
Production'da maliyet farkının anlamı: M2.5 Standard, ajanlı iş akışlarının harcamanın büyük bölümünü oluşturduğu çıktı token'larında Opus 4.6'nın 1/20'i maliyetle çalışıyor. M2.5 ile Opus 4.6 arasındaki %0,6'lık SWE-Bench farkı çoğu görev türü için 20× maliyet primini haklı çıkarmıyor. Opus 4.6'nın primini hak ettiği yer derin akıl yürütme, özerk terminal operasyonları veya yüksek riskli iş mantığı gerektiren görevler — Terminal-Bench 2.0'daki liderliğinin (%65,4'e karşı %52) çıktı kalitesine gerçekten yansıdığı alanlar. Rutin code review, refactor ve üretim görevleri için maliyet matematiği güçlü biçimde M2.5'i işaret ediyor.
Coding Plan ile Kullandıkça Öde — Gerçek Karar
MiniMax iki yapısal olarak farklı erişim yolu sunuyor. Bunlar birbirinin yerine geçemiyor — farklı kullanım durumlarına hizmet ediyor.
Coding Plan — İdeal Ekip Profili, Kapsam ve Başa Baş Noktası
Coding Plan, 5 saatlik pencere başına prompt kotası olarak yapılandırılmış bir abonelik paketi. Şubat 2026 itibarıyla kritik uyarı: Coding Plan M2.5 tarafından değil M2.1 tarafından destekleniyor. M2.5'in %80,2'lik SWE-Bench skoru hedefin ise kullandıkça öde üzerinden doğrudan API erişimi o modele ulaşmanın şu an tek yolu.
| Plan | Fiyat | Kota |
|---|---|---|
| Starter | $10/ay | 100 prompt/5 saat |
| Standard | $30/ay | 300 prompt/5 saat |
| Pro | $60/ay | 600 prompt/5 saat |
| Max | $100/ay | 1.000 prompt/5 saat |
Başa baş analizi (karşılaştırma için M2.1 kullandıkça öde oranları kullanılarak):
Coding Plan, kullandıkça öde oranlarındaki prompt başına maliyetin abonelik fiyatını aştığı noktada maliyet etkin oluyor. M2.1 Standard fiyatlandırması (~$0,30/$1,20) ve prompt başına ortalama 3.000 giriş + 2.000 çıktı token'ı varsayımıyla:
M2.1 kullandıkça öde üzerinden prompt başına maliyet:
Giriş: 3.000 × $0,30/M = $0,0009
Çıktı: 2.000 × $1,20/M = $0,0024
Prompt başına: $0,0033
Starter plan başa baş (uniform prompt kullanımı varsayımıyla):
Aylık kota tahmini: 100 prompt/5st × (günlük 3 oturum tahminiyle 30 gün) = 300 prompt/ay
Kullandıkça öde eşdeğeri: 300 × $0,0033 = $0,99/ay
$0,99 eşdeğer değerle $10/aylık Starter plan ortalama prompt'larda
salt token maliyeti açısından MALİYET ETKİN DEĞİL.
Yalnızca şu durumlarda maliyet etkin hale geliyor:
(a) çok daha büyük bağlamlı prompt'lar kullanıyorsan (her biri 10.000+ token), VEYA
(b) sabit oranlı öngörülebilirliğin ekibin için bütçe yönetimi değeri taşıması, VEYA
(c) iş akışını kesen rate limit baş ağrısı marjinal maliyet tasarrufundan daha önemliyseCoding Plan mantıklı olduğu durumlar:
- Aylık AI araçları için sabit bir gider kalemi isteyen solo geliştirici
- Prompt'ların büyük olması (her biri 10.000+ token), token başına faturalandırmayı pahalı yapan
- Rate limit başlık alanı marjinal maliyet tasarrufundan daha önemli
Atlaman gereken durumlar:
- M2.5'e özellikle ihtiyacın varsa (Coding Plan şu an bunu sağlamıyor)
- İş yükün sürekli değil ani artışlı ise
- Otomatik pipeline oluşturuyorsan (prompt kotası faturalandırması otomasyon örüntülerine uymaz)
M2.5'i değerlendiren ekipler için: kullandıkça öde kullan. MiniMax planı M2.5 içerecek şekilde güncelledikten sonra veya M2.1 daha düşük maliyetle performans gereksinimlerini karşılıyorsa Coding Plan'ı yeniden değerlendir.
Kullandıkça Öde — Deneme, Ani Artışlı İş Yükleri ve Erken Değerlendirme İçin En İyi
M2.5'in token oranlarında doğrudan API faturalandırması üç kullanıcı kategorisi için doğru seçim:
Deneme yapanlar: M2.5 Standard oranlarında gerçek token tüketimini ölçmek için 50 gerçek görev çalıştırmanın maliyeti yaklaşık:
50 görev × ortalama (2.500 giriş + 1.250 çıktı token'ı):
Giriş: 125.000 × $0,15/M = $0,019
Çıktı: 62.500 × $1,20/M = $0,075
Toplam: $0,094 (~50 görev için $0,10)M2.5'in kullanım durumuna uyup uymadığını bilmek için $0,10'un altında. Ölçmemenin maliyeti bundan kat kat yüksek.
Ani artışlı iş yükleri: Yapay zeka kullanımın sabit günlük hacim yerine sprint döngüleri, code freeze dönemleri veya çeyrek sonu yayınları etrafında kümeleniyorsa kullandıkça öde, zirveler arasında kullanmadığın kapasite için ödeme yapmaktan kurtarıyor.
Çok model yönlendirme: Görevleri karmaşıklığa göre M2.5 ile Opus 4.6 arasında yönlendiriyorsan her iki modelde de kullandıkça öde, görev başına temiz maliyet ilişkilendirmesi sağlar. Abonelik bu muhasebeyi gizler.
Değinilmesi gereken bir sürtüşme noktası: kullandıkça öde kredi bakiyesi tutmayı gerektiriyor. Düşük bakiye koşulları API çağrılarının sessizce başarısız olmasına neden olabilir. Production'da herhangi bir şey çalıştırmadan önce platform dashboard'unda minimum bakiye uyarısı ayarla.
Gerçek Aylık Fatura — Orta Ölçekli Ekip İçin Tam Örnek
Denetlenebilir aritmetikle somut bir senaryo: M2.5 destekli code review ve refactor ajanı çalıştıran 6 kişilik bir mühendislik ekibi, haftada 5 gün.
Açık varsayımlar (kendi iş yükün için bunları ölç):
| Parametre | Değer |
|---|---|
| Günlük görev sayısı | 200 görev/gün |
| Ortalama giriş token'ı/görev | 5.000 token |
| Ortalama çıktı token'ı/görev | 3.500 token |
| Önbellek isabet oranı | %40 (kararlı sistem promptu + repo bağlamı) |
| Çalışma günü/ay | 22 gün |
Aylık maliyet hesabı (tam gösterimle):
# Adım 1 — Aylık toplam görev:
200 görev/gün × 22 gün = 4.400 görev/ay
# Adım 2 — %40 önbellek indirimi sonrası görev başına efektif giriş token'ı:
5.000 × (1 - 0,40) = 3.000 efektif giriş token'ı
# Adım 3 — Görev başına maliyet:
Giriş: 3.000 × $0,15 / 1.000.000 = $0,00045
Çıktı: 3.500 × $1,20 / 1.000.000 = $0,00420
Görev başına toplam: $0,00465
# Adım 4 — Aylık toplam:
4.400 × $0,00465 = $20,46/ayBatch API ile Claude Opus 4.6 üzerinde aynı iş yükü (%50 indirim uygulanmış):
# Adım 1 — Aynı 4.400 görev/ay
# Adım 2 — Önbellekleme yok varsayımı (Anthropic prompt önbelleği manuel yapılandırma
# gerektirir; M2.5'in otomatik %40 önbellek avantajına karşı adil
# karşılaştırma için %0 isabet oranı varsayıyoruz)
# Adım 3 — Görev başına maliyet (Batch API = standard oranlardan %50 indirim):
Giriş: 5.000 × $5,00/M × 0,50 = $0,01250
Çıktı: 3.500 × $25,00/M × 0,50 = $0,04375
Görev başına toplam: $0,05625
# Adım 4 — Aylık toplam:
4.400 × $0,05625 = $247,50/ayNot: Opus 4.6'ya da Anthropic'in prompt önbelleğini uygularsan (uygun önekler için önbelleğe alınmış giriş $0,50/M, manuel yapılandırmayla) ve aynı %40 isabet oranını varsayarsan:
# Batch API + girişte %40 prompt önbellekleme ile Opus 4.6:
Önbelleğe alınmış giriş: 2.000 × $0,50/M × 0,50 = $0,000500
Önbelleğe alınmamış giriş: 3.000 × $5,00/M × 0,50 = $0,007500
Çıktı: 3.500 × $25,00/M × 0,50 = $0,043750
Görev başına toplam: $0,051750
Aylık toplam: 4.400 × $0,05175 = $227,70/ayÖzet tablo:
| Parametre | Değer |
|---|---|
| Günlük görev sayısı | 200 görev/gün |
| Ortalama giriş token'ı/görev | 5.000 token |
| Ortalama çıktı token'ı/görev | 3.500 token |
| Önbellek isabet oranı | %40 (kararlı sistem promptu + repo bağlamı) |
| Çalışma günü/ay | 22 gün |
~11–12× fark, Opus 4.6'nın en iyi mevcut indirimleri aynı iş yüküne uygulandıktan sonra da devam ediyor. Sürekli otomatik kodlama ajanı çalışması için yıllık maliyet farkı $2.500–$2.725 aralığına yaklaşıyor.
Evrensel maliyet formülü — kendi tahminin için bunu kullan:
def estimate_monthly_cost(
tasks_per_day: int,
avg_input_tokens: int, # usage.input_tokens örneklerinden
avg_output_tokens: int, # usage.output_tokens örneklerinden
cache_hit_rate: float, # cache_read_input_tokens / input_tokens değerinden
input_price_per_M: float, # örn. M2.5 Standard için 0.15
output_price_per_M: float, # örn. M2.5 Standard için 1.20
working_days: int = 22,
) -> dict:
tasks_per_month = tasks_per_day * working_days
effective_input = avg_input_tokens * (1 - cache_hit_rate)
cost_per_task = (
effective_input * input_price_per_M / 1_000_000 +
avg_output_tokens * output_price_per_M / 1_000_000
)
monthly = tasks_per_month * cost_per_task
return {
"tasks_per_month": tasks_per_month,
"cost_per_task_usd": round(cost_per_task, 6),
"monthly_cost_usd": round(monthly, 2),
"annual_cost_usd": round(monthly * 12, 2),
}
# Örnek — yukarıdaki çalışma örneğini yeniden üret:
result = estimate_monthly_cost(
tasks_per_day=200,
avg_input_tokens=5000,
avg_output_tokens=3500,
cache_hit_rate=0.40,
input_price_per_M=0.15,
output_price_per_M=1.20,
)
# Çıktı: {'tasks_per_month': 4400, 'cost_per_task_usd': 0.00465,
# 'monthly_cost_usd': 20.46, 'annual_cost_usd': 245.52}Henüz ölçmediysen cache_hit_rate=0.30 ile başla. İlk haftalık production kullanımının ardından usage alanından cache_read_input_tokens / input_tokens değerini kontrol et ve parametreyi güncelle.
Karşılaştığımız 3 Fatura Spikı — ve Her Biri İçin Çözüm
Bunlar iki haftalık production denemesi sırasında (8–22 Şubat 2026) ekibimizin API loglarından gerçek maliyet anomalileri. Hiçbiri MiniMax'a özgü değil — bunlar ajanlı iş akışı sorunları. Ama M2.5'in düşük token başına maliyeti, birleşip fark edilene kadar kolayca gözden kaçan yanlış bir güvenlik hissi yaratıyor.
Ajanlı Yeniden Denemelerde Sınırsız Bağlam → Çözüm: Bağlamı ve Yeniden Deneme Bütçesini Sınırla
Ne oldu: Yeniden deneme mantığı, düşünme çıktısı ve araç çağrısı geçmişi dahil önceki tam girişimi konuşma bağlamına ekliyordu. 4. yeniden denemeye gelindiğinde, 6.000 giriş token'ıyla başlayan bir görev çağrı başına 40.000+ token tüketiyordu.
Gerçek loglarımızdan rakamlar:
%12 başarısız ve yeniden deneme oranına sahip gün:
200 görev × %12 = yeniden deneme gerektiren 24 görev
4. yeniden denemede ortalama bağlam büyümesi: 6.000 → 38.000 token (+32.000)
Beklenmedik token: 24 × 32.000 = 768.000 ekstra giriş token'ı
$0,15/M ek maliyet: 768.000 × $0,15/M = $0,115 (tek gün)
Aylık tahmin (giderilmezse): yaklaşık $2,53 fazla giriş maliyeti
M2.5 oranlarında bu telafi edilebilir. Opus 4.6 oranlarında ($5/M giriş):
Aynı örüntü: 768.000 × $5,00/M = $3,84/gün → ~$84/ayÇözüm:
MAX_CONTEXT_TOKENS = 15_000
MAX_RETRIES = 3
def run_with_budget(messages: list, max_retries: int = MAX_RETRIES):
for attempt in range(max_retries):
# Her çağrıdan önce token bütçesine göre kırp
trimmed = trim_to_token_budget(messages, MAX_CONTEXT_TOKENS)
response = client.messages.create(
model="MiniMax-M2.5",
max_tokens=4096,
messages=trimmed
)
if response.stop_reason == "end_turn":
return response
# Yeniden denemede: önceki girişimi tam olarak eklemek yerine özetle
messages = summarize_and_retry(messages, response)
raise MaxRetriesExceeded(f"Görev {MAX_RETRIES} denemeden sonra başarısız oldu")Hem bağlam penceresini hem yeniden deneme sayısını sınırla. Yeniden denemede önceki girişimin tam çıktısını geçmişe eklemek yerine özetle.
Hedefli Diff Yerine Tam Dosya Promptları → Çözüm: Diff-Önce Prompting
Ne oldu: Code review ajanı her PR incelemesi için tüm dosya içeriğini gönderiyordu — PR 600 satırlık dosyanın 8 satırını değiştirse bile. Python servisindeki ortalama dosya boyutu: ~800 satır ≈ 16.000 token.
Matematik:
Görev başına israf edilen token:
Tam dosya: ~16.000 token
İlgili diff: ~800 token (her tarafta 10 satır bağlamla ~10 satır değişiklik tahmini)
İsraf edilen giriş: görev başına 15.200 token
50 inceleme görevi/gün × 15.200 israf edilen token = 760.000 token/gün
M2.5 Standard ($0,15/M): $0,114/gün → $2,51/ay israf
Opus 4.6 ($5,00/M): $3,80/gün → $83,60/ay israfÇözüm — diff-önce prompting:
import subprocess
def get_diff_context(file_path: str, base_branch: str = "main",
context_lines: int = 10) -> str:
"""Yalnızca değiştirilen satırları + N satır çevre bağlamını döndür."""
result = subprocess.run(
["git", "diff", base_branch, f"--unified={context_lines}", file_path],
capture_output=True, text=True
)
return result.stdout # Tam dosyanın 10.000+ tokenına karşı tipik olarak 100–800 token
def review_pr_changes(file_path: str, base_branch: str = "main") -> object:
diff_context = get_diff_context(file_path, base_branch)
if not diff_context.strip():
return None # Bu dosyada değişiklik yok, çağrıyı tamamen atla
return client.messages.create(
model="MiniMax-M2.5",
max_tokens=1024,
messages=[{"role": "user", "content": (
f"Bu değişiklikleri yalnızca doğruluk ve stil açısından incele:\n\n"
f"{diff_context}\n\n"
f"Odak: mantık hataları, edge case'ler, isimlendirme ve test kapsamı eksiklikleri."
)}]
)Bu değişiklik inceleme çağrısı başına ortalama giriş token'ımızı ~14.000'den ~800'e indirdi — %94 düşüş. Tam dosyayı yalnızca görevin bunu gerçekten gerektirdiği durumlarda gönder: tüm dosya refactor'ları, mimari düzey incelemeler.
Tekrarlanan Repo Taramalarında Önbellek Kullanımının Kaçırılması → Çözüm: Önbellek Kullanımını Etkinleştir ve Doğrula
Ne oldu: Çok ajanlı kurulum her ajan çağrısının başında 45.000 token'lık bir repository özeti gönderiyordu. Otomatik önbelleklemenin çağrılar arasında bunu hallettiğini varsaydık. Halletti — ama yalnızca aynı oturum içinde. Oturumlar arası önbellek davranışı beklediğimizden daha sınırlıydı ve prompt başlığındaki değişken öğeler (oturum kimliği) önbellek anahtarlarını geçersiz kılıyordu.
Önbelleğin gerçekten isabet edip etmediğini nasıl doğrularsın:
def make_cached_call(repo_summary: str, task: str) -> object:
# ÖNEMLİ: kararlı bağlamı ÖNCE, değişken öğeleri SONA koy
# Önbellek anahtarları prompt önekinde eşleştirilir — kararlı bloktan önce
# herhangi bir değişken içerik önbellek eşleşmesini bozar
response = client.messages.create(
model="MiniMax-M2.5",
max_tokens=2048,
messages=[{
"role": "user",
"content": f"{repo_summary}\n\nGörev: {task}"
# ^^^^^^^^^^^^ kararlı önek ^^^^ değişken sonek
}]
)
usage = response.usage
cache_reads = getattr(usage, "cache_read_input_tokens", 0)
total_input = usage.input_tokens
hit_rate = cache_reads / total_input if total_input > 0 else 0.0
# İzleme için bunu logla — hit_rate 0.0'da kalırsa bir sorun var
print(f"[Önbellek] giriş={total_input} | önbellek_okuma={cache_reads} | "
f"isabet_oranı={hit_rate:.1%}")
return response
# Tanı: önbellekli ile önbelleksiz maliyeti karşılaştır
# cache_read_input_tokens sürekli 0 ise kontrol et:
# 1. Kararlı bloktan önce değişken içerik (zaman damgası, kimlikler) görünüyor mu?
# 2. Ardışık çağrılar için aynı istemci oturumunu yeniden kullanıyor musun?
# 3. Önbelleklemeyi tetiklemek için kararlı önek yeterince uzun mu (tipik olarak 1.024+ token)?Promptları kararlı içeriği önce koyacak şekilde yeniden yapılandırdıktan ve tüm değişken öğeleri (görev kimliği, zaman damgası) promptun sonuna taşıdıktan sonra repo özeti segmentindeki önbellek isabet oranımız ~%15'ten ~%68'e çıktı.
Önbellek yapısını düzeltmenin maliyet etkisi (gerçek rakamlarımız):
Düzeltme öncesi: 45.000 token'lık repo özeti üzerinde %15 önbellek isabet oranı, 100 çağrı/gün
Çağrı başına efektif giriş: 45.000 × (1 - 0,15) = 38.250 token
Günlük giriş maliyeti: 100 × 38.250 × $0,15/M = $0,574/gün
Düzeltme sonrası: 45.000 token'lık repo özeti üzerinde %68 önbellek isabet oranı, 100 çağrı/gün
Çağrı başına efektif giriş: 45.000 × (1 - 0,68) = 14.400 token
Günlük giriş maliyeti: 100 × 14.400 × $0,15/M = $0,216/gün
Aylık tasarruf: ($0,574 - $0,216) × 22 gün = $7,88/ayM2.5 oranlarında bu mütevazı. Opus 4.6 oranlarında aynı örüntü ~$263/ay tasarruf sağlar.
Bir Plana Bağlanmadan Önce Formülü Kullan
Yukarıdaki çalışma örneği bir başlangıç noktası, nihai yanıt değil. Gerçek maliyetin yalnızca senin ölçebileceğin üç sayıya bağlı: gerçek görev hacmi, görev başına ortalama token sayısı ve kararlı bağlamda önbellek isabet oranı.
Kullandıkça öde veya Coding Plan'a bağlanmadan önce çalıştıracağım ölçüm sırası:
usage.input_tokensveusage.output_tokensdeğerlerini her biri için loglayarak kullandıkça öde üzerinde 50 gerçek görev çalıştır.- Görev başına gerçek ortalama token'ı hesapla. Tahmin etme — ölç.
- Gerçek önbellek isabet oranını bulmak için
usagealanındancache_read_input_tokens / input_tokensdeğerini kontrol et. - Bu üç sayıyı yukarıdaki Python formülüne gir.
- Aylık sonucu Coding Plan kademeleriyle karşılaştır — ve Coding Plan'ın şu an M2.5 değil M2.1 üzerinde çalıştığını doğrula.
Otomatik kodlama ajanı işi yürüten çoğu ekip için, MiniMax planı M2.5 içerecek şekilde güncellenene kadar M2.5 üzerinde kullandıkça öde, Coding Plan'dan hem maliyet hem model kapasitesi açısından önde çıkacak. Takip etmeye değer bir değişiklik.
