
Meta açıklama: Claude Opus 4.7, 16 Nisan 2026'da 4.6 ile aynı fiyata çıktı. SWE-bench Verified 6.8 puan atladı, tokenizer değişti ve "aynı fiyat" ile "aynı maliyet" arasındaki makas ekiplerin geçiş kararını belirliyor — rakamlar ve gerçek production farkları burada.
"Aynı fiyat" yazınca dikkat et.
Claude Opus 4.7, 16 Nisan 2026'da yayımlandı. Fiyat sayfasında 4.6 ile özdeş: milyon token başına $5 giriş, $25 çıkış. Ama tokenizer da değişti. Ve aynı input, 4.7'de %35'e kadar daha fazla token üretiyor.
"Aynı fiyat, farklı maliyet" — ve bu ayrımı ölçmeden geçiş yapmak sürpriz faturayla karşılaşmanın en kısa yolu.
Benchmark'lar gerçekten hareket etti. Behavior değişiklikleri production'da hissediliyor. Ama her değişiklik her iş akışı için olumlu değil. Aşağıda neyin değiştiğini, nerede geriye gittiğini ve ne zaman beklemekte fayda olduğunu yazdım.
Hızlı Karar: Kim Geçmeli, Kim Beklemeli?

Geç, eğer:
Çok dosyalı, karmaşık görevlerde otonom coding agent'ları çalıştırıyorsan — SWE-bench Verified 6.8 puan, CursorBench 12 puan atladı.
Screenshot, diagram veya UI parsing içeren iş akışların varsa — görüntü çözünürlüğü üç katına çıktı, XBOW Visual Acuity %54,5'ten %98,5'e geldi.
Çok adımlı agent döngüsü orkestre ediyorsan — araç hataları Opus 4.6 seviyesinin üçte birine düştü ve yeni xhigh effort seviyesi daha ince kontrol sunuyor.
Terminal/komut satırı agentic çalışma için Opus 4.6'dasın — Terminal-Bench 2.0 %65,4'ten %69,4'e geldi (GPT-5.4 %75,1 ile hâlâ önde).
Bekle, eğer:
Prompt'larını 4.6'nın gevşek talimat yorumuyla ayarladıysan — 4.7 talimatları kelimesi kelimesine takip ediyor; söylenmemiş niyeti modelin çıkarmasına bağlı çalışan prompt'lar farklı çıktı üretiyor.
Gerçek trafiğinde tokenizer etkisini henüz ölçmemişsen — aynı input için %35'e kadar daha fazla token; çok dilli veya yapılandırılmış içerikte bu gerçek bir maliyet artışı.
Agentic web araması birincil kullanım senaryonsa — BrowseComp 4.7'de %83,7'den %79,3'e geriledi; GPT-5.4 Pro %89,3 ile önde.
Uyumluluk onaylı bir 4.6 deployment'ın varsa — 4.7'deki yeni siber güvenlik koruma katmanları beklenmedik redler üretebilir; geçmeden önce doğrula.
Benchmark Karşılaştırma Tablosu
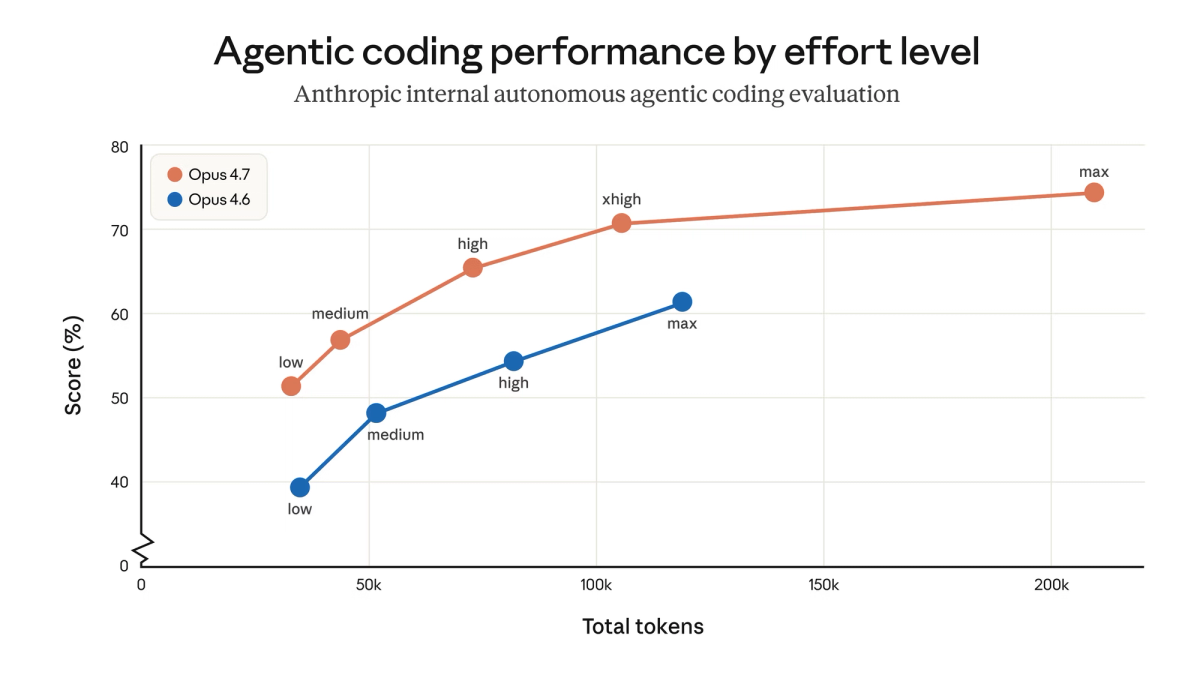
Aksi belirtilmedikçe tüm Anthropic tarafından raporlanan skorlar. Opus 4.6 skorları 5 Şubat 2026 Anthropic sürümünden; Opus 4.7 skorları 16 Nisan 2026 Anthropic sürümünden.
| Benchmark | Opus 4.6 | Opus 4.7 | Δ | GPT-5.4 | Notlar |
|---|---|---|---|---|---|
| SWE-bench Verified | %80,80 | %87,60 | +6,8pp | — | Anthropic tarafından yürütüldü; ezber ekranları uygulandı |
| SWE-bench Pro | %53,40 | %64,30 | +10,9pp | %57,70 | Çok dilli gerçek dünya görevleri; Scale AI benchmark |
| CursorBench | 58% | 70% | +12pp | — | Partner değerlendirmesi; kaynak: Cursor CEO |
| GPQA Diamond | %91,30 | %94,20 | +2,9pp | %94,40 | Pratikte doygunlukta; farklar gürültü içinde |
| Terminal-Bench 2.0 | %65,40 | %69,40 | +4,0pp | %75,10 | 4.7, 4.6'yı geçiyor; GPT-5.4 genel önde |
| BrowseComp | %83,70 | %79,30 | −4,4pp | %89,30 | 4.6'ya göre gerileme; GPT-5.4 ve Gemini 3.1 Pro ikisi de önde |
| XBOW Visual Acuity | %54,50 | %98,50 | +44pp | — | Bilgisayar kullanımı screenshot benchmark; XBOW partner değerlendirmesi |
| MCP-Atlas | %73,90 | %77,30 | +3,4pp | %68,10 | Ölçekli araç kullanımı; Anthropic tarafından yürütüldü |
| Finance Agent v1.1 | %59,70 | %64,40 | +4,7pp | — | Anthropic tarafından yürütüldü |
Partner veri kaynakları hakkında: CursorBench, Rakuten-SWE-Bench ve XBOW Visual Acuity rakamları, Anthropic'in resmi sürüm sayfasında atıfta bulunulan partner değerlendirmeleri. Bağımsız olarak çoğaltılmış Anthropic değerlendirmeleri değil — tescilli test setlerinde yürütülen partner benchmark'ları. Kontrollü karşılaştırmalar değil, production kullanımından güçlü yönlendirici sinyaller olarak değerlendir.
Terminal-Bench hakkında: 4.7, 4.6'ya kıyasla 4,0 puan iyileşti. Bu bir gerileme değil — rekabet açığı GPT-5.4'e karşı, önceki versiyona karşı değil.
Production'da Görünen Behavior Farkları
Kendi kendini doğrulama döngüsü — tamamlandı demeden önce kendi işini kontrol ediyor
Opus 4.7, bir görevi tamamlandı olarak bildirmeden önce proaktif olarak doğrulama adımları yazıyor. Agentic kodlamada bu şu anlama geliyor: model testleri yazıyor, çalıştırıyor ve hataları sonuçları yüzeye çıkarmadan önce dahili olarak düzeltiyor. Vercel'in ekibi "işe başlamadan önce sistem kodu üzerinde kanıtlar yapıyor — önceki Claude modellerinde görmediğimiz yeni bir davranış" olarak aktardı. Bu, orkestratör katmanına ulaşan güvenle yanlış çıktıların sıklığını azaltıyor.
Talimat takibi daha katı — madde listeleri zorunlu gereksinimler olarak değerlendiriliyor
Opus 4.6 talimatları gevşek yorumluyor ve zaman zaman söylenmemiş niyeti çıkarıyordu. Opus 4.7 talimatları tam olarak takip ediyor. Anthropic'in geçiş rehberi bunu açıkça işaretliyor: "Opus 4.7, effort seviyelerine kesinlikle uyar; özellikle düşük seviyede. Düşük ve orta effort'ta model, istenenin ötesine geçmek yerine işini istenenle sınırlandırır."
Pratikte: daha önce modelin kısmi talimatlardan genelleme yapacağına güvenerek çalışan madde listeli prompt'lar artık daha dar çıktı üretebilir. Geçiş yapmadan önce 4.6'nın geniş yorumuna dayanan tüm prompt'ları test et.
Araç hataları üçte birine düştü
Notion AI'ın AI Lideri Sarah Sachs, Anthropic'in resmi sürümünde aktarıldı: "daha az token ve üçte bir araç hatasıyla Opus 4.6'nın %14 üzerinde." Bu, kendi spesifik orkestrasyon pattern'larındaki tek bir partner'ın dahili benchmark'ı — kontrollü bir çapraz model değerlendirmesi değil. Bununla birlikte, birkaç başka partner da benzer güvenilirlik iyileştirmeleri bildirdi: Factory Droids "daha az araç hatası ve doğrulama adımlarında daha güvenilir takip" kaydetti; Genspark, "döngü direncinde" (modelin bir sorgu üzerinde süresiz çalışma oranı) anlamlı iyileşme bildirdi.
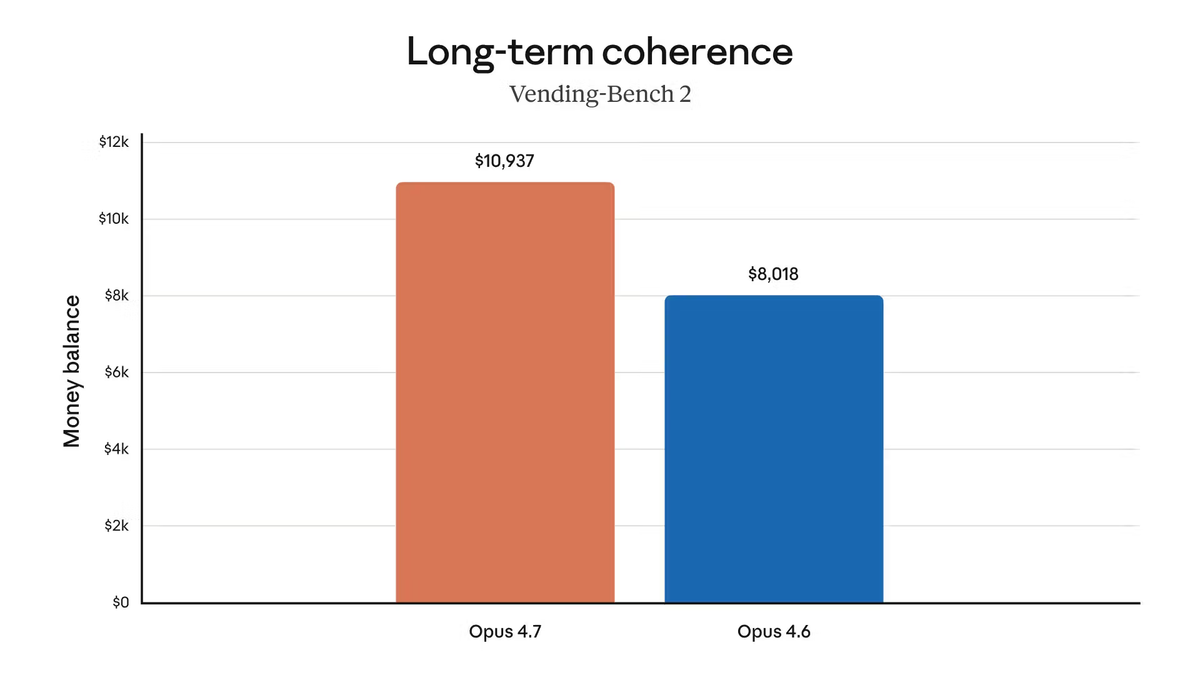
3× daha fazla production görevi çözüldü
Rakuten, Anthropic'in resmi sürümünde aktarıldı: "Rakuten-SWE-Bench'te Claude Opus 4.7, Opus 4.6'ya kıyasla 3 kat daha fazla production görevi çözüyor; Kod Kalitesi ve Test Kalitesinde çift haneli kazanımlarla." Bu, kendi dahili codebase'lerindeki Rakuten'e ait tescilli bir benchmark — standart SWE-bench değil. Büyüklük dikkate değer, ama doğru karşılaştırma Rakuten'in codebase'i değil, kendi codebase'in.
4.6'da Olmayan Yeni Özellikler
xhigh effort seviyesi — daha ince akıl yürütme/gecikme takası
4.6'daki effort seviyeleri: low, medium, high, max. Opus 4.7 high ile max arasına xhigh ekliyor. Claude Code tüm planlarda varsayılan olarak xhigh kullanıyor. Hex'in CTO'su "düşük effort'lu Opus 4.7'nin yaklaşık olarak orta effort'lu Opus 4.6'ya eşdeğer olduğunu" gözlemledi — bu şu anlama geliyor: 4.6'da bir görev için high kullanıyorduysan, 4.7'de karşılaştırılabilir ayar xhigh.
# Claude Code
/effort xhigh
# API
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=64000,
output_config={"effort": "xhigh"},
messages=[{"role": "user", "content": "..."}]
)Görev bütçeleri (public beta) — uzun agentic işler için token harcamasını sınırla
Görev bütçesi, modele tüm agentic döngü için bir token hedefi veriyor — düşünme, araç çağrıları, araç sonuçları ve nihai çıktı dahil. Model çalışan sayıyı görüyor ve bütçe yaklaşırken düzgün biçimde tamamlıyor. 4.6'da mevcut değil. task-budgets-2026-03-13 beta başlığını kullan:
response = client.beta.messages.create(
model="claude-opus-4-7",
max_tokens=128000,
betas=["task-budgets-2026-03-13"],
output_config={
"effort": "high",
"task_budget": {"type": "token_target", "token_target": 50000}
},
messages=[{"role": "user", "content": "..."}]
)Görev bütçeleri tavsiye niteliğinde, kesin sınır değil — model hedefin farkında ama token_targetı aşabilir. Minimum 20K token. Açık uçlu, kalite öncelikli görevler için Anthropic görev bütçesini atlamayı öneriyor.
Claude Code'da /ultrareview — çok turlu code review seansı
Claude Code'da yeni komut, 4.6'da mevcut değil. Mimari, güvenlik, performans ve sürdürülebilirlik incelemesi için tek yapılandırılmış turda özel seans. Anthropic, lansmanda Pro ve Max kullanıcıları için üç ücretsiz ultrareview sunuyor.
Max kullanıcıları için Auto Mode
4.6 yapılandırmalarında daha önce yalnızca Enterprise planlara kısıtlıydı. Artık Max kullanıcılarına açık: agent, uzun görevleri kesintiye uğratmamak için davranışını otomatik ayarlıyor; onay için duraksama yerine küçük belirsizlikleri bağımsız olarak hallediyor.
Gerçek Maliyet Tablosu
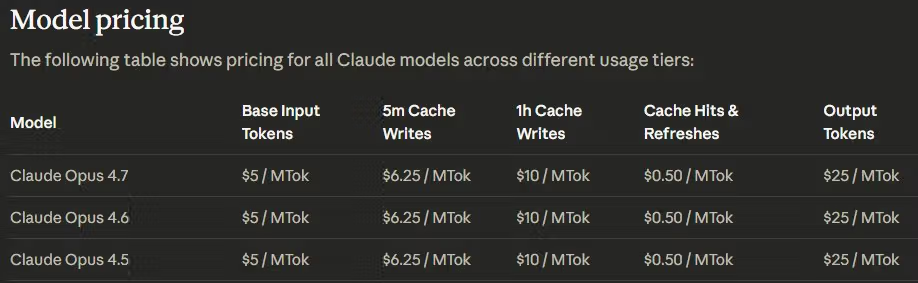
Liste fiyatı değişmedi: milyon token başına $5/$25
Fiyatlandırma Claude API, Amazon Bedrock, Google Cloud Vertex AI ve Microsoft Foundry'de Opus 4.7 ve 4.6'da özdeş. Batch API indirimi (%50) ve prompt caching (%90'a kadar) da değişmedi.
Tokenizer değişikliği: aynı input → %35'e kadar daha fazla token
Anthropic'in geçiş rehberi: "Bu yeni tokenizer, metni işlerken önceki modellere kıyasla yaklaşık 1× ile 1,35× daha fazla token kullanabilir (%35'e kadar daha fazla, içeriğe göre değişir)."
Aralık içerik türleri arasında uniform değil:
| İçerik türü | Yaklaşık çarpan | Pratik sonucu |
|---|---|---|
| İngilizce düzyazı | 1,00–1,05× | Chat iş yükleri için ihmal edilebilir etki |
| Temiz kod (İngilizce tanımlayıcılar) | 1,05–1,10× | Tipik API codebase'lerinde küçük maliyet artışı |
| Teknik/karma içerik | 1,10–1,20× | Config dosyaları, log'lar, karma İngilizce/kod |
| Çok dilli metin (CJK, Arapça, Kiril) | 1,20–1,35× | İngilizce dışı ürünlerde anlamlı artış |
| Yapılandırılmış veri (JSON, XML) | 1,10–1,25× | Şema ayrıntısına ve iç içe geçme derinliğine göre değişir |
Not: Bu aralıklar Anthropic'in belirttiği 1,0–1,35× genel aralıktan ve içerik türü behavior pattern'larından çıkarılmıştır. Belirli içeriğin gerçek çarpanı /v1/messages/count_tokens kullanılarak doğrudan ölçüm gerektirir.
Örnek hesaplama: Aylık 1.000 kodlama görevi
Varsayımlar:
- Görev başına ortalama input: 8.000 token (sistem promptu 2K + kod context 4K + kullanıcı mesajı 2K)
- Görev başına ortalama output: 3.000 token (kod değişiklikleri + açıklama)
- İçerik türü: İngilizce kod + teknik context → tahmini 1,10× tokenizer çarpanı
Opus 4.6 aylık maliyet:
- Input: 1.000 × 8.000 = 8.000.000 token → 8M × $5/M = $40,00
- Output: 1.000 × 3.000 = 3.000.000 token → 3M × $25/M = $75,00
- Toplam: $115,00/ay
Opus 4.7 aylık maliyet (aynı görev hacmi):
- Input: 8.000.000 × 1,10 = 8.800.000 token → 8,8M × $5/M = $44,00
- Output: 3.000.000 token → $75,00
- Toplam: $119,00/ay
- Artış: $4,00 (+%3,5)
1,35× tavanında çok dilli içerik için:
- Input: 8.000.000 × 1,35 = 10.800.000 token → 10,8M × $5/M = $54,00
- Toplam: $129,00/ay vs $115,00 (+$14,00, +%12,2)
Çoğu ekip için gerçek maliyet sürücüsü tokenizer değil — xhigh** effort'un karmaşık görevlerde ürettiği düşünme token'ları.** 4.6'da max çalıştırıyordun ve 4.7'de xhigh'a geçiyorsan, görev başına output token'ları artabilir. Hacimde taahhüt etmeden önce temsili trafikte ölç.
Caching'in enflasyonu nerede dengelediği
Kararlı sistem prompt'ları ve prompt caching aracılığıyla önbelleğe alınan araç tanımları, tokenizer değişikliklerinden bağımsız olarak %90'a kadar maliyet indirimi sağlar. Sistem prompt'un 4.6'da 4.000 token, 4.7'de 4.400 token ise (%10 tokenizer enflasyonu), cache hit maliyeti yine de önbelleksiz orandan %90 daha düşük. Sistem prompt'un isteklerin büyük çoğunluğunda statik olduğu mimarilerde caching, input maliyetlerindeki tokenizer etkisini büyük ölçüde nötralize ediyor.
Geçiş Riskleri
4.6'nın gevşek yorumu için yazılmış prompt'lar farklı çıktı üretebilir
Geçiş öncesi denetlenecek spesifik pattern'lar:
Katı gereksinimler değil, rehberlik olarak kullanılan madde listeleri — 4.7 bunları zorunlu spesifikasyonlar olarak değerlendiriyor.
Kısmi kısıtlamalar sağlayıp modelin boşlukları doldurmasına güvenerek çalışan prompt'lar — 4.7 bu boşlukları 4.6 gibi doldurmayacak.
Modelin proaktif araç çağırmasını bekleyen araç kullanımı prompt'ları — 4.7 varsayılan effort seviyelerinde "Opus 4.6'ya kıyasla araçları daha az sıklıkta kullanıyor, akıl yürütmeyi daha fazla"; araç çağrısı sıklığı düşerse high veya xhigh'a yükselt.
Prefill pattern'ları: asistan mesajı prefilling, Opus 4.6'dan itibaren 400 hatası döndürüyor ve 4.7'de devam ediyor — bunun 4.6 geçişinde zaten ele alındığını doğrula.
Gerçek trafikte token bütçesi yeniden ölçümü gerekli
/v1/messages/count_tokens aynı input için 4.7'de 4.6'dan farklı değerler döndürüyor. Altyapındaki herhangi bir maliyet tahmini, rate limit planlaması veya token tabanlı yönlendirme, gerçek 4.7 trafiğine karşı yeniden kalibre edilmesi gerekiyor. Anthropic'in önerisi: hedef effort seviyende 4.7 üzerinden temsili bir production trafiği örneği çalıştır ve input+output token toplamlarını doğrudan karşılaştır.
Karar Çerçevesi: Trafiği Ne Zaman Böl?
Tam geçişe taahhüt edemeyen ekipler için 4.7'ye trafiğin bir alt kümesini yönlendirmek şu durumlarda mantıklı:
| Durum | Yönlendirme önerisi |
|---|---|
| Otonom coding agent'ları (yeni özellik geliştirme) | %100'ünü 4.7'ye yönlendir; kazanımlar partner değerlendirmelerinde tutarlı |
| Bilgisayar kullanımı / screenshot ağırlıklı iş akışları | %100'ünü 4.7'ye yönlendir; görüntü iyileştirmesi kesin bir kapasite atlaması |
| Agentic web araştırması (BrowseComp ağırlıklı) | 4.6'da kal ya da GPT-5.4'ü test et; 4.7, 4,4 puan geriledi |
| Terminal / shell komut yürütme | A/B testi; 4.7, 4.6'yı 4pp geçiyor ama GPT-5.4'ün 5,7pp gerisinde |
| Çok dilli içerik (CJK, Arapça) | Maliyet izlemeyle A/B testi; tokenizer etkisi burada en yüksek |
| Sıkı biçimlendirmeli production prompt'ları | Önce %10'luk alt kümeyi test et; talimat katılığı değişikliği bunları etkiliyor |
| Toplu işleme (zaman kritik olmayan) | Kalite deltasını taahhüt etmeden ölçmek için Batch API'da tam A/B çalıştır (%50 indirim) |
Sık Sorulan Sorular
4.7, 4.6 ile rate limit paylaşıyor mu?
Rate limitler Anthropic'in API'sinde model bazında. Opus 4.6 ve 4.7'nin ayrı rate limit tahsisleri var. Kapasiteye yakınsan platform.claude.com'da mevcut tier limitlerini kontrol et — 4.7'ye geçiş 4.6'nın rate limit başlığını devralmıyor.
Tokenizer değişikliği kod için mi yoksa doğal dil için mi daha büyük?
Anthropic'in 1,0–1,35× aralığına ve içerik türü pattern'larına dayanarak, İngilizce tanımlayıcılı İngilizce kod alt uçta oturuyor (yaklaşık 1,05–1,10×). İngilizce düzyazı benzer. Çok dilli metin ve yapılandırılmış veri (JSON, XML) üst uca yaklaşıyor. Anthropic'in resmi önerisi doğrudan ölçmek: gerçek input'larında /v1/messages/count_tokens tek güvenilir rakam.
Tam geçiş öncesi 4.7'yi bir alt kümede test etmeli miyim?
Evet, özellikle şunlardan herhangi biri geçerliyse: 4.6'nın gevşek yorumu için ayarlanmış prompt'ların varsa, çok dilli içeriği hacimli işliyorsan, belirli bir araç çağrısı frekansı pattern'ına güveniyorsan veya iş akışların BrowseComp türü görevlerin önemli olduğu önemli bir agentic web araştırması yapıyorsa. Model ID takası önemsiz; prompt ve maliyet etki denetimi gerçek geçiş işinin nerede yattığı. Anthropic'in geçiş rehberi platform.claude.com/docs/en/about-claude/models/migration-guide adresinde spesifik kırıcı değişiklikleri ve önerilen doğrulama adımlarını kapsıyor.
Net konuşmak gerekirse: 4.7 gerçek bir yükseltme — ama her iş akışı için değil ve "aynı fiyat" etiketi tam resmi vermiyor. Otonom coding agent'ları, görüntü ağırlıklı iş akışları ve çok adımlı orkestrasyon için rakamlar tutarlı. Agentic web araması için 4.6'da kal ya da GPT-5.4'ü test et. Her iki durumda da: geçmeden önce tokenizer etkisini kendi trafiğinde ölç, xhigh effort'un token bütçeni nasıl değiştirdiğini kalibre et.
Bir plan seçmeden önce gerçek kullanım maliyetini görmek istiyorsan Verdent'i dene — kredi kartı gerekmeden 100 ücretsiz kredi, Claude Sonnet 4.6, Opus 4.6 ve diğer modeller üzerinde çalışıyor. Ücretsiz başla →
İyi kodlamalar.
