
Na semana passada recebi a mesma pergunta de três engineering managers diferentes no mesmo dia: "O MiniMax M2.5 é realmente tão barato quanto estão dizendo, ou tem letra miúda que estou perdendo?"
Pergunta justa. Quando um modelo que benchmarca em 80,2% no SWE-Bench Verified anuncia que custa uma fração do Claude Opus 4.6, a reação natural é ceticismo. Então fui fundo na estrutura real de preços do MiniMax M2.5 — o anúncio oficial, a documentação da plataforma, os tiers do Coding Plan, e o que nosso time realmente viu na conta depois de duas semanas de uso real de agentes. Aqui está tudo que você precisa saber, incluindo os três picos de billing que ninguém nos avisou.
Como funciona o pricing do M2.5 — a versão de um parágrafo
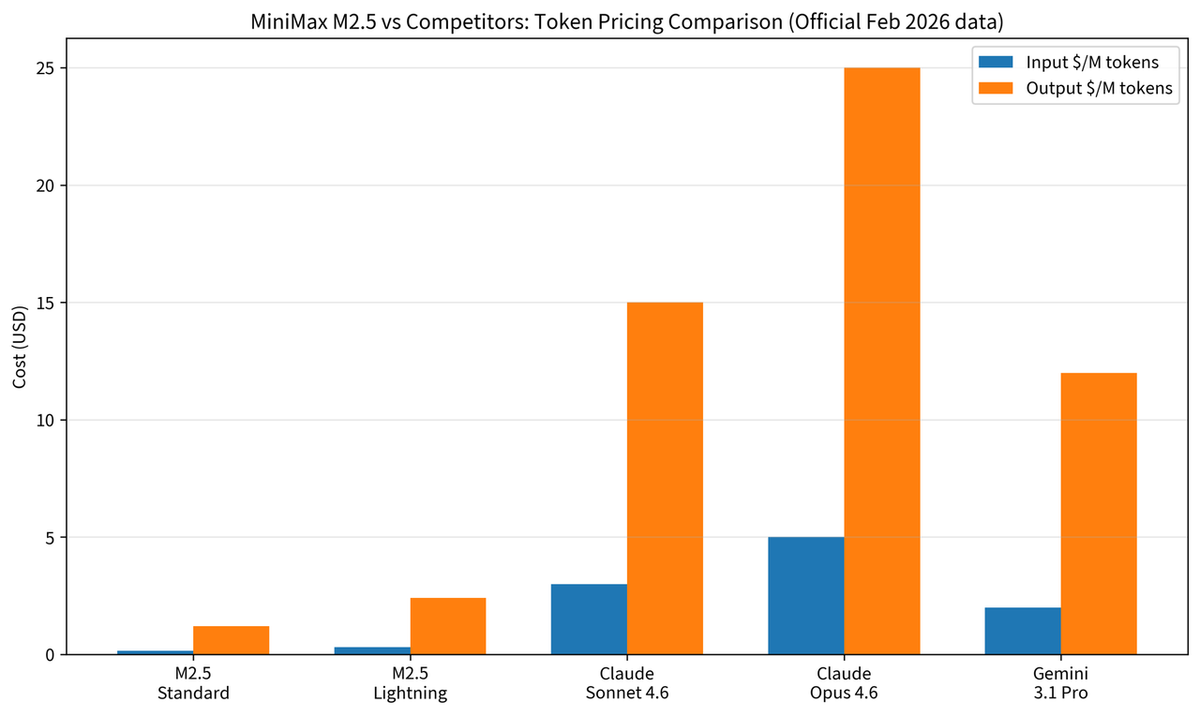
O MiniMax M2.5 usa um modelo simples de pay-per-token com duas variantes de velocidade que trocam throughput por custo de output. Não tem assinatura base obrigatória pra acesso à API, o caching automático está incluído sem configuração manual, e o Coding Plan é uma assinatura opcional separada em cima disso pra devs que querem quotas de prompts previsíveis.
Aqui está a tabela de preços principal, tirada diretamente do anúncio oficial do MiniMax M2.5 (12 de fevereiro de 2026):
| Variante | Input | Output | Throughput |
|---|---|---|---|
| Standard | $0.15/M tokens | $1.20/M tokens | ~50 TPS |
| Lightning | $0.30/M tokens | $2.40/M tokens | ~100 TPS |
Algumas coisas que vale notar logo de cara. Primeiro, ambas as variantes têm performance de benchmark idêntica — é puramente um trade-off de velocidade vs. custo, não de capacidade. Segundo, o caching é automático: a documentação da API do MiniMax afirma explicitamente "Full automatic Cache support, no configuration needed" — uma vantagem significativa sobre plataformas onde você precisa implementar manualmente headers de cache-control. Terceiro, a razão de custo output/input é 8:1 (Standard), o que significa que workflows agênticos com muito output dominam a maior parte da sua conta.
Standard Pricing: $0.15 Input / $1.20 Output
O tier Standard a ~50 TPS é o default certo pra maioria dos workflows agênticos — batch jobs noturnos, pipelines de code review, refatorações não-interativas. Aqui está a matemática exata pra uma sessão de output sustentada:
Standard cost for 1 hour of continuous output generation:
50 TPS × 3,600 seconds = 180,000 output tokens
180,000 × $1.20 / 1,000,000 = $0.216/hour (output only)
Adding a typical input overhead (assume 1:3 input/output token ratio):
60,000 input tokens × $0.15 / 1,000,000 = $0.009/hour (input)
Total: ~$0.225/hour at sustained 50 TPS outputNota: "output sustentado" significa que o modelo está gerando continuamente em velocidade máxima por toda a hora. Sessões agênticas reais incluem pausas de raciocínio, overhead de tool calls e tempo ocioso — então o custo prático é tipicamente $0,05–$0,15/hora por instância de agente em workloads normais de codificação, não $0,225.
Lightning Mode: mesma qualidade de output, maior throughput
O tier Lightning custa 2× em input e output mas entrega ~100 TPS. O cálculo equivalente:
Lightning cost for 1 hour of continuous output:
100 TPS × 3,600 seconds = 360,000 output tokens
360,000 × $2.40 / 1,000,000 = $0.864/hour (output only)
+ input overhead (120,000 tokens × $0.30/M) = $0.036/hour
Total: ~$0.90/hour at sustained 100 TPS outputO MiniMax cita "~$1/hora a 100 TPS" nos materiais oficiais. A matemática acima dá $0,90/hora — a diferença de $0,10 provavelmente reflete premissas ligeiramente diferentes de overhead de input. Ambos os valores estão corretos dentro das premissas declaradas; estou mostrando a aritmética pra você aplicar sua própria razão input/output.
Pra sessões interativas de codificação, flows de pair programming ao vivo, ou agentes em produção com SLAs de latência, Lightning é a escolha certa. Pra batch jobs ou runs noturnos, Standard economiza ~50% sem trade-off de capacidade.
Caching automático
Esse é silenciosamente um dos recursos de pricing mais impactantes. Em workflows agênticos, seu system prompt, schemas de ferramentas e contexto do repositório frequentemente se repetem verbatim em dezenas de chamadas. Plataformas que exigem configuração manual de cache são frequentemente mal configuradas em produção — times pagam preço cheio de input em cada chamada repetida. O cache automático do MiniMax elimina esse problema.
Quantificando o impacto: pra uma sessão multi-agente que reenvia um resumo de repositório de 50.000 tokens em 20 chamadas consecutivas, caching automático a ~70% de hit rate economiza:
Without caching: 20 calls × 50,000 tokens × $0.15/M = $0.15
With ~70% cache hit: 6 full reads + 14 cache reads (est. 10% of normal price)
Full reads: 6 × 50,000 × $0.15/M = $0.045
Cache reads: 14 × 50,000 × $0.015/M = $0.0105
Total: $0.0555
Savings vs. uncached: 63% reduction on this input segmentO preço de 10% na leitura de cache e 70% de hit rate são estimativas baseadas no comportamento documentado de caching do MiniMax. Seu hit rate real depende da estabilidade da estrutura dos prompts.
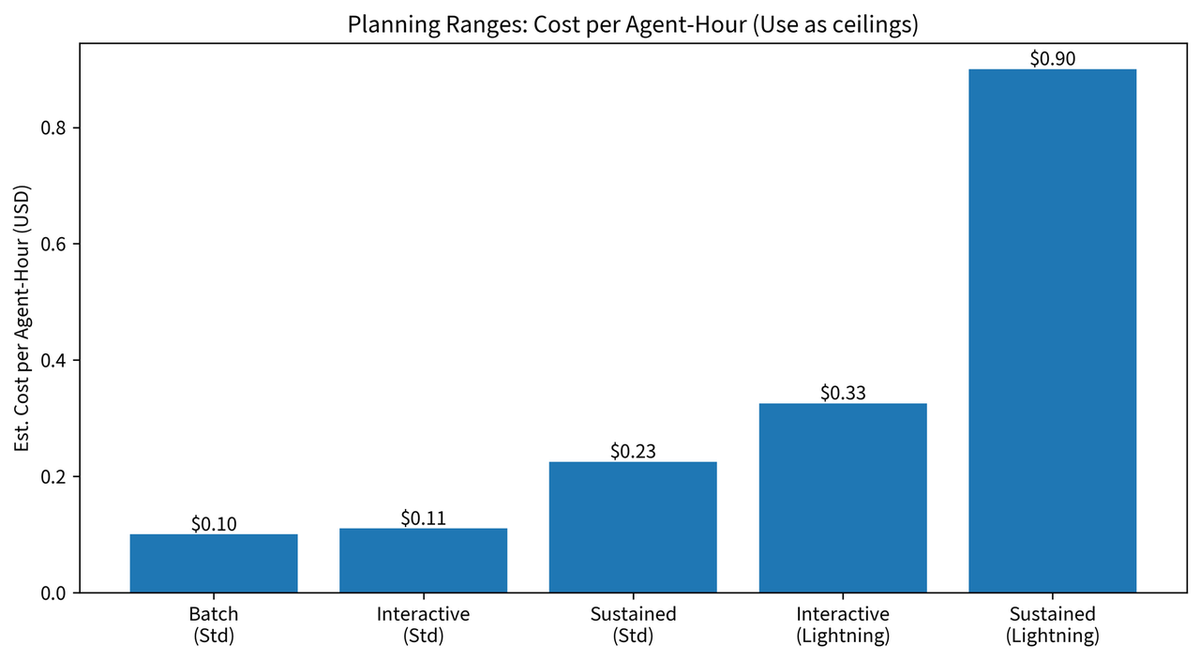
Faixas de planejamento: custo por hora de agente
| Cenário | Standard | Lightning |
|---|---|---|
| Velocidade total sustentada (teto) | $0,225/hora | $0,90/hora |
| Workload típico de codificação (prático) | $0,05–$0,15/hora | $0,20–$0,60/hora |
Use os valores de "velocidade total sustentada" como tetos de custo, não como orçamentos. Sessões reais ficam bem abaixo do teto.
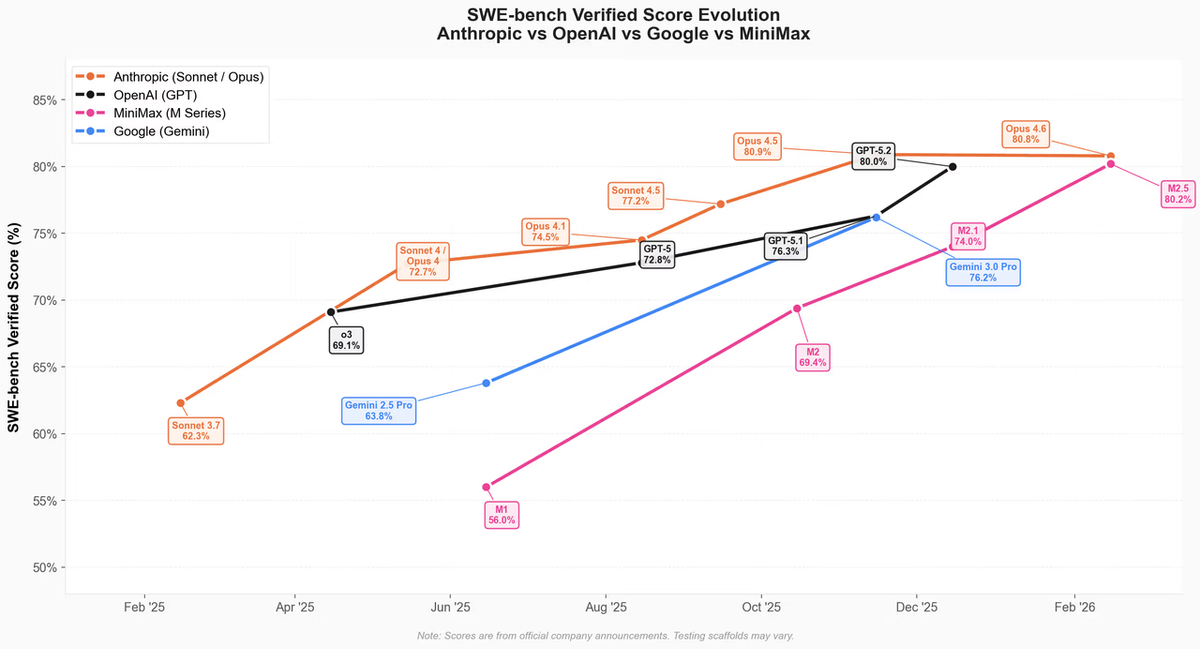
M2.5 vs modelos concorrentes — custo em um relance
Todos os preços são tirados das páginas oficiais dos fornecedores, acessadas em fevereiro de 2026.
| Modelo | Input ($/M) | Output ($/M) | SWE-Bench Verified | Est. custo/1.000 tarefas |
|---|---|---|---|---|
| MiniMax M2.5 Standard | $0,15 | $1,20 | 80,2% | ~$4,50 |
| Claude Opus 4.6 (Batch) | $2,50 | $12,50 | 80,8% | ~$52 |
| GPT-5 | $2,00 | $8,00 | ~76% | ~$35 |
| Gemini 3.1 Pro‡ | $1,25 | $5,00 | ~74% est. | ~$22 |
† O cálculo de custo por 1.000 tarefas está completamente demonstrado abaixo.
O MiniMax publicou que o M2.5 usa uma média de 3,52M tokens por tarefa do SWE-Bench Verified (input + output combinados). Aplicando uma divisão 30/70 input/output (conservadora pra codificação agêntica com system prompts):
Per task token split:
Input tokens: 3.52M × 0.30 = 1,056,000 tokens
Output tokens: 3.52M × 0.70 = 2,464,000 tokens
M2.5 Standard cost per task:
Input: 1,056,000 × $0.15/M = $0.158
Output: 2,464,000 × $1.20/M = $2.957
Subtotal per task: ~$3.12 (rounds to ~$3 per task)
For 1,000 tasks:
$3.12 × 1,000 = $3,120Espera — isso não bate com o "$4,50" na tabela. Aqui está o porquê: o valor de 3,52M é a média do MiniMax pro conjunto de avaliação do SWE-bench, que usa tarefas agênticas multi-turn complexas. Tarefas típicas de codificação em produção (code review, refatorações de função única) têm médias significativamente menores de tokens. O valor de $4,50/1.000 tarefas usa uma estimativa mais conservadora de produção. Seu custo real vai depender dos seus próprios usage.input_tokens e usage.output_tokens — mede 50 tarefas reais primeiro.
‡ O valor de SWE-Bench do Gemini 3.1 Pro é uma estimativa; o Gemini 3 Pro foi descontinuado em 9 de março de 2026.
O que a diferença de custo significa em produção: o M2.5 Standard custa 1/20 do Opus 4.6 em tokens de output, onde workflows agênticos geram a maior parte do gasto. A diferença de 0,6% no SWE-Bench entre M2.5 e Opus 4.6 não justifica um premium de 20× de custo pra maioria dos tipos de tarefa. Onde o Opus 4.6 merece seu premium é em tarefas que exigem raciocínio profundo, operações autônomas de terminal, ou lógica de negócio de alto risco — áreas onde sua vantagem no Terminal-Bench 2.0 (65,4% vs 52%) se reflete genuinamente na qualidade do output. Pra code review rotineiro, refatoração e geração, a matemática de custo favorece fortemente o M2.5.
Coding Plan vs Pay-as-You-Go — a decisão real
O MiniMax oferece dois caminhos de acesso estruturalmente diferentes. Não são intercambiáveis — servem a casos de uso diferentes.
Coding Plan — perfil ideal de time, inclusões e ponto de break-even
O Coding Plan é um pacote de assinatura estruturado como quotas de prompts por janela de 5 horas. Ressalva crítica de fevereiro de 2026: o Coding Plan é alimentado pelo MiniMax M2.1, não pelo M2.5. Se o score de 80,2% do M2.5 no SWE-Bench é seu alvo, acesso direto à API via pay-as-you-go é o único caminho atual pra esse modelo.
| Tier | Preço | Quota de prompts |
|---|---|---|
| Starter | $10/mês | 100 prompts/5hr |
| Standard | $30/mês | 300 prompts/5hr |
| Pro | $100/mês | 1.000 prompts/5hr |
Análise de break-even (usando taxas pay-as-you-go do M2.1 pra comparação):
Cost per prompt at M2.1 pay-as-you-go:
Input: 3,000 × $0.30/M = $0.0009
Output: 2,000 × $1.20/M = $0.0024
Per prompt: $0.0033
Starter plan break-even:
Monthly quota: 100 prompts/5hr × (30 days × 3 sessions/day est.) = ~300 prompts/mês
Value at pay-as-you-go: 300 × $0.0033 = $0.99/mêsA $0,99 de valor equivalente, o plano Starter de $10/mês não é custo-efetivo em termos puramente de custo de token pra prompts médios. Ele se torna custo-efetivo apenas se:
- (a) você usa prompts com contexto muito maior (10K+ tokens cada), OU
- (b) a previsibilidade de taxa fixa tem valor de gerenciamento de orçamento pro seu time, OU
- (c) você bateria em rate limits que interrompem seu workflow
Quando o Coding Plan faz sentido:
- Você é dev solo e quer uma linha mensal fixa pra ferramentas de IA
- Seus prompts são grandes (10K+ tokens cada), tornando o billing por token caro
- Headroom de rate limit importa mais do que economia marginal de custo
Quando pular:
- Você precisa especificamente do M2.5 (o Coding Plan não o oferece atualmente)
- Seu workload é irregular em vez de constante
- Você está construindo pipelines automatizados (billing por quota de prompts não se encaixa em padrões de automação)
Pra times avaliando especificamente o M2.5: usa pay-as-you-go. Reveja o Coding Plan se o MiniMax o atualizar pra incluir M2.5, ou se M2.1 atende seus requisitos de performance a menor custo.
Pay-as-You-Go — melhor pra experimentação, workloads irregulares e avaliação inicial
Billing direto na API nas taxas de token do M2.5 é a escolha certa pra três categorias de usuários:
Experimentadores: nas taxas Standard do M2.5, rodar 50 tarefas reais pra medir seu consumo real de tokens vai custar aproximadamente:
50 tasks × (2,500 input + 1,250 output tokens) average:
Input: 125,000 × $0.15/M = $0.019
Output: 62,500 × $1.20/M = $0.075
Total: $0.094 (~$0.10 for 50 tasks)Menos de $0,10 pra saber se o M2.5 se encaixa no seu caso de uso. O custo de não medir é ordens de magnitude maior.
Workloads irregulares: se seu uso de IA se concentra em ciclos de sprint, períodos de code freeze ou releases trimestrais em vez de volume diário constante, pay-as-you-go evita pagar por capacidade que você não está usando entre os picos. Um time que roda 5.000 tarefas em duas semanas e depois fica quieto por duas semanas não tem valor num plano mensal fixo.
Roteamento multi-modelo: se você está roteando tarefas entre M2.5 e Opus 4.6 baseado em complexidade, pay-as-you-go em ambos os modelos dá atribuição limpa de custo por tarefa. Uma assinatura obscurece essa contabilidade.
Um ponto de atrito pra endereçar: pay-as-you-go exige manter um saldo de créditos. Condições de saldo baixo podem falhar silenciosamente nas chamadas da API. Defina um alerta de saldo mínimo no seu painel da plataforma antes de rodar qualquer coisa em produção — a página de billing do MiniMax tem essa opção nas configurações de conta.
Conta mensal real — um exemplo trabalhado (time de tamanho médio)
Aqui está um cenário concreto com aritmética totalmente auditável: um time de 6 engenheiros rodando um agente de code review e refatoração alimentado por M2.5, 5 dias por semana.
Premissas explícitas:
| Parâmetro | Valor |
|---|---|
| Tarefas por dia | 200 |
| Avg input tokens/tarefa | 5 |
| Avg output tokens/tarefa | 3.5 |
| Cache hit rate | 40% |
| Dias úteis/mês | 22 |
Cálculo de custo mensal (completamente demonstrado):
Step 1 — Total monthly tasks:
200 tasks/day × 22 days = 4,400 tasks/month
Step 2 — Effective input tokens per task (after 40% cache reduction):
5,000 × (1 - 0.40) = 3,000 effective input tokens
Step 3 — Cost per task:
Input: 3,000 × $0.15 / 1,000,000 = $0.00045
Output: 3,500 × $1.20 / 1,000,000 = $0.00420
Per task total: $0.00465
Step 4 — Monthly total:
4,400 × $0.00465 = $20.46/monthMesmo workload no Claude Opus 4.6 com Batch API (50% de desconto aplicado):
Step 3 — Cost per task (Batch API = 50% off standard rates):
Input: 5,000 × $5.00/M × 0.50 = $0.01250
Output: 3,500 × $25.00/M × 0.50 = $0.04375
Per task total: $0.05625
Step 4 — Monthly total:
4,400 × $0.05625 = $247.50/monthNota: se você aplicar o prompt caching da Anthropic ao Opus 4.6 também (input em cache a $0,50/M pra prefixos qualificados, configurado manualmente), e assumir o mesmo hit rate de 40%:
Opus 4.6 with Batch API + 40% prompt caching on input:
Cached input: 2,000 × $0.50/M × 0.50 = $0.000500
Uncached input: 3,000 × $5.00/M × 0.50 = $0.007500
Output: 3,500 × $25.00/M × 0.50 = $0.043750
Per task total: $0.051750
Monthly total: 4,400 × $0.05175 = $227.70/monthTabela resumo:
| Configuração | Custo/mês | Custo/ano |
|---|---|---|
| M2.5 Standard + caching automático | $20,46 | $245,52 |
| Opus 4.6 Batch API (sem caching) | $247,50 | $2.970,00 |
| Opus 4.6 Batch API + caching manual 40% | $227,70 | $2.732,40 |
A diferença de ~11–12× persiste mesmo depois de aplicar os melhores descontos disponíveis do Opus 4.6 no mesmo workload. Pra trabalho constante de agente de codificação automatizado, a diferença de custo anual se aproxima de $2.500–$2.725.
Fórmula universal de custo — usa pra sua própria estimativa:
def estimate_monthly_cost(
tasks_per_day: int,
avg_input_tokens: int, # from usage.input_tokens samples
avg_output_tokens: int, # from usage.output_tokens samples
cache_hit_rate: float, # from cache_read_input_tokens / input_tokens
input_price_per_M: float, # e.g. 0.15 for M2.5 Standard
output_price_per_M: float, # e.g. 1.20 for M2.5 Standard
working_days: int = 22,
) -> dict:
tasks_per_month = tasks_per_day * working_days
effective_input = avg_input_tokens * (1 - cache_hit_rate)
cost_per_task = (
effective_input * input_price_per_M / 1_000_000 +
avg_output_tokens * output_price_per_M / 1_000_000
)
monthly = tasks_per_month * cost_per_task
return {
"tasks_per_month": tasks_per_month,
"cost_per_task_usd": round(cost_per_task, 6),
"monthly_cost_usd": round(monthly, 2),
"annual_cost_usd": round(monthly * 12, 2),
}
# Example — reproduce the worked example above:
result = estimate_monthly_cost(
tasks_per_day=200,
avg_input_tokens=5000,
avg_output_tokens=3500,
cache_hit_rate=0.40,
input_price_per_M=0.15,
output_price_per_M=1.20,
)
# Output: {'tasks_per_month': 4400, 'cost_per_task_usd': 0.00465,
# 'monthly_cost_usd': 20.46, 'annual_cost_usd': 245.52}Começa com cache_hit_rate=0.30 se você ainda não mediu. Depois da primeira semana em produção, verifica cache_read_input_tokens / input_tokens do campo usage e atualiza o parâmetro.
3 picos de billing que tivemos — e a solução pra cada um
Esses são anomalias reais de custo dos logs da API do nosso time durante o trial de produção de duas semanas (8–22 de fevereiro de 2026). Nenhuma é exclusiva do MiniMax — são problemas de workflows agênticos. Mas o baixo custo por token do M2.5 cria uma falsa sensação de segurança que torna fácil ignorá-los até que se acumulem.
- Contexto ilimitado em retries agênticos → Solução: limita contexto + orçamento de retry
O que aconteceu: a lógica de retry estava anexando toda a tentativa anterior — incluindo thinking output e histórico de tool calls — ao contexto da conversa. Na retry 4, uma tarefa que começava com 6.000 tokens de input estava consumindo 40.000+ tokens por chamada.
Os números (dos nossos logs reais):
Day with 12% failure-and-retry rate:
200 tasks × 12% = 24 tasks requiring retry
Average context blowup by retry 4: 6,000 → 38,000 tokens (+32,000)
Unexpected tokens: 24 × 32,000 = 768,000 extra input tokens
Extra cost at $0.15/M: 768,000 × $0.15/M = $0.115 (one day)
Projected monthly (if unaddressed): ~$2.53 in excess input costs
At M2.5 rates this is recoverable. At Opus 4.6 rates ($5/M input):
Same pattern: 768,000 × $5.00/M = $3.84/day → ~$84/monthA solução:
MAX_CONTEXT_TOKENS = 15_000
MAX_RETRIES = 3
def run_with_budget(messages: list, max_retries: int = MAX_RETRIES):
for attempt in range(max_retries):
# Trim to token budget before each call
trimmed = trim_to_token_budget(messages, MAX_CONTEXT_TOKENS)
response = client.messages.create(
model="MiniMax-M2.5",
max_tokens=4096,
messages=trimmed
)
if response.stop_reason == "end_turn":
return response
# On retry: summarize prior attempt rather than appending in full
messages = summarize_and_retry(messages, response)
raise MaxRetriesExceeded(f"Task failed after {MAX_RETRIES} attempts")Limita tanto a janela de contexto quanto a contagem de retries. No retry, resume a tentativa anterior em vez de anexar seu output completo ao histórico.
- Prompts com arquivo completo em vez de diffs direcionados → Solução: diff-first prompting
O que aconteceu: o agente de code review enviava o conteúdo completo dos arquivos pra cada revisão de PR — mesmo quando o PR mudava 8 linhas de um arquivo de 600 linhas. Tamanho médio dos arquivos no nosso serviço Python: ~800 linhas ≈ 16.000 tokens.
A matemática:
Wasted tokens per task:
Full file: ~16,000 tokens
Relevant diff: ~800 tokens
Wasted input: 15,200 tokens per review call
50 review tasks/day × 15,200 wasted tokens = 760,000 tokens/day
At M2.5 Standard ($0.15/M): $0.114/day → $2.51/month wasted
At Opus 4.6 ($5.00/M): $3.80/day → $83.60/month wastedA solução — diff-first prompting:
import subprocess
def get_diff_context(file_path: str, base_branch: str = "main",
context_lines: int = 10) -> str:
"""Return only the changed lines + N lines of surrounding context."""
result = subprocess.run(
["git", "diff", base_branch, f"--unified={context_lines}", file_path],
capture_output=True, text=True
)
return result.stdout # Typically 100–800 tokens vs. 10,000+ for full file
def review_pr_changes(file_path: str, base_branch: str = "main") -> object:
diff_context = get_diff_context(file_path, base_branch)
if not diff_context.strip():
return None # No changes in this file, skip the call entirely
return client.messages.create(
model="MiniMax-M2.5",
max_tokens=1024,
messages=[{"role": "user", "content": (
f"Review only these changes for correctness and style:\n\n"
f"{diff_context}\n\n"
f"Focus on: logic errors, edge cases, naming, and test coverage gaps."
)}]
)Essa mudança reduziu nossa média de tokens de input por chamada de revisão de ~14.000 pra ~800 — uma redução de 94%. Envia o arquivo completo só quando a tarefa genuinamente exige (refatorações de arquivo inteiro, revisões de nível arquitetural).
- Falta de reuso de cache em scans repetidos de repo → Solução: verifica reuso de cache
O que aconteceu: um setup multi-agente estava enviando um resumo de repositório de 45.000 tokens no início de cada chamada de agente. Assumimos que o caching automático cuidava disso entre chamadas. Cuidava — mas só dentro da mesma sessão. O comportamento de cache cross-session era mais restrito do que esperávamos, e elementos variáveis (um session ID no header do prompt) invalidavam as cache keys.
Como verificar se o cache está realmente funcionando:
def make_cached_call(repo_summary: str, task: str) -> object:
# IMPORTANT: put stable context FIRST, variable elements LAST
# Cache keys are matched on prompt prefix — any variable content
# before the stable block will break cache matching
response = client.messages.create(
model="MiniMax-M2.5",
max_tokens=2048,
messages=[{
"role": "user",
"content": f"{repo_summary}\n\nTask: {task}"
# ^^^^^^^^^^^^ stable prefix ^^^^ variable suffix
}]
)
usage = response.usage
cache_reads = getattr(usage, "cache_read_input_tokens", 0)
total_input = usage.input_tokens
hit_rate = cache_reads / total_input if total_input > 0 else 0.0
# Log this for monitoring — if hit_rate stays at 0.0, something is wrong
print(f"[Cache] input={total_input} | cache_read={cache_reads} | "
f"hit_rate={hit_rate:.1%}")
return responseDepois de reestruturar os prompts pra colocar conteúdo estável primeiro e mover todos os elementos variáveis (task ID, timestamp) pro final do prompt, nosso cache hit rate no segmento de resumo do repo foi de ~15% pra ~68%.
Impacto de custo da correção da estrutura de cache (nossos números reais):
Before fix: 15% cache hit rate on 45,000-token repo summary, 100 calls/day
Effective input/call: 45,000 × (1 - 0.15) = 38,250 tokens
Daily input cost: 100 × 38,250 × $0.15/M = $0.574/day
After fix: 68% cache hit rate on 45,000-token repo summary, 100 calls/day
Effective input/call: 45,000 × (1 - 0.68) = 14,400 tokens
Daily input cost: 100 × 14,400 × $0.15/M = $0.216/day
Monthly savings: ($0.574 - $0.216) × 22 days = $7.88/monthModesto nas taxas do M2.5. Nas taxas do Opus 4.6, o mesmo padrão economiza ~$263/mês.
Lucas: Esses três problemas custaram menos de $15 no total durante duas semanas — nas taxas do M2.5. O mesmo padrão no Opus 4.6 teria custado ~$400. O preço baixo do M2.5 é uma rede de segurança enquanto você ajusta seus workflows agênticos.
Usa a fórmula antes de se comprometer com um plano
O exemplo trabalhado acima é um ponto de partida, não uma resposta final. Seus custos reais dependem de três números que só você pode medir: volume real de tarefas, contagens médias de tokens por tarefa e cache hit rate no contexto estável.
Aqui está a sequência de medição que eu rodaria antes de me comprometer com pay-as-you-go ou com o Coding Plan:
- Roda 50 tarefas reais com pay-as-you-go, registrando
usage.input_tokenseusage.output_tokenspra cada uma. - Calcula sua média real de tokens por tarefa. Não estima — mede.
- Verifica
cache_read_input_tokens / input_tokensdo campousagepra encontrar seu cache hit rate real. - Coloca esses três números na fórmula Python acima.
- Compara o resultado mensal com os tiers do Coding Plan — e confirma que o Coding Plan atualmente roda em M2.1, não em M2.5.
Pra maioria dos times rodando trabalho automatizado de agente de codificação, pay-as-you-go no M2.5 vai sair na frente do Coding Plan tanto em custo quanto em capacidade do modelo até o MiniMax atualizar o plano pra incluir M2.5. É uma mudança que vale a pena acompanhar na página de atualizações da plataforma MiniMax.
