
A maioria dos devs que avalia agentes de terminal para código bate na mesma parede: Claude Code é o padrão maduro e bem documentado, mas o custo escala rápido em runs de agente com muito output. DeepSeek-TUI apareceu como a alternativa óbvia assim que o DeepSeek V4 chegou. A comparação parece limpa de longe. Fica complicada quando você realmente vai fundo.
As versões comparadas: DeepSeek-TUI v0.8.8 (maio de 2026, desenvolvimento ativo, não GA) vs Claude Code (release atual de maio de 2026, GA). Ambos avaliados na mesma semana — isso importa porque as duas ferramentas estão mudando rápido.
Um fato que muda a comparação logo de cara: Claude Code consegue rodar DeepSeek V4 como backend, via variáveis de ambiente oficialmente documentadas pela DeepSeek. Não é um workaround de nicho — está documentado no próprio guia de integração de API da DeepSeek para Claude Code. As implicações são reais: você não está forçado a escolher entre o UX do Claude Code e a estrutura de custo da DeepSeek. Mas esse caminho tem suas próprias trocas, cobertas abaixo.
TL;DR — Qual Serve pra Você
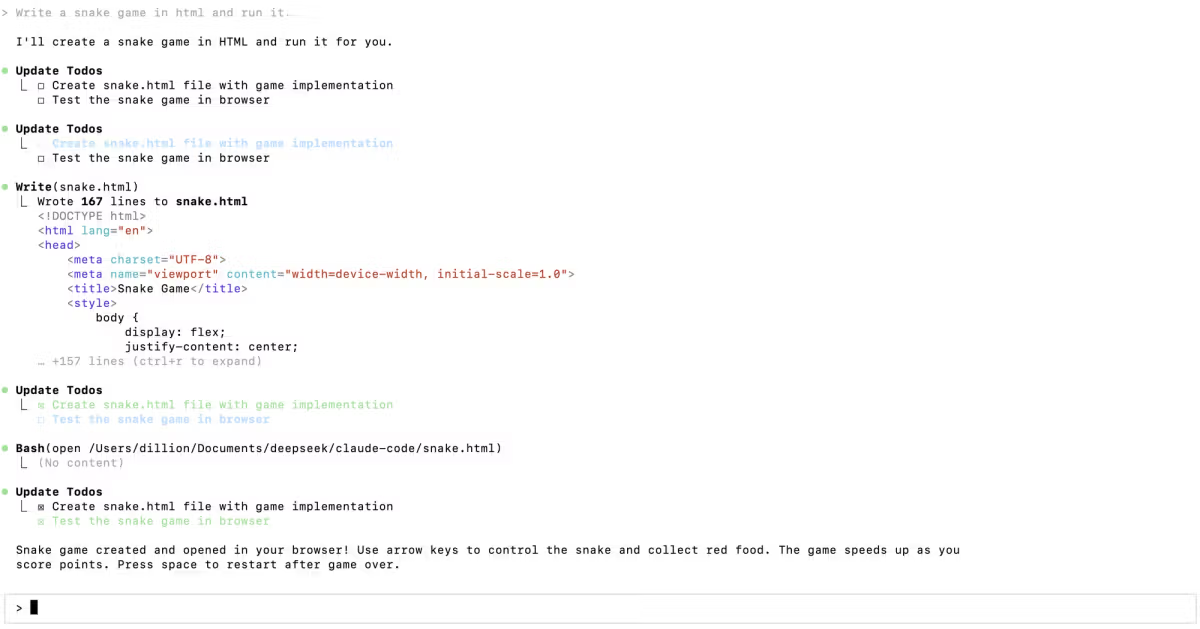
Escolha DeepSeek-TUI se você está comprometido com DeepSeek V4, quer o primitivo RLM de sub-agentes paralelos nativo, se importa com performance Rust-nativa e footprint de memória, e consegue aceitar um projeto mantido pela comunidade em maturidade v0.8.x.
Escolha Claude Code se quer o ecossistema first-party da Anthropic (xhigh effort, /ultrareview, task budgets, Routines, assinatura Max), precisa de responsabilidade enterprise com o fornecedor, ou está usando Claude Sonnet/Opus como modelo principal e não quer construir em torno de um harness específico de modelo.
DeepSeek-TUI e Claude Code em Perspectiva
DeepSeek-TUI é um projeto open-source independente de Hunter Bown (GitHub: Hmbown), construído em Rust com ratatui, distribuído como dois binários obrigatórios (veja github.com/Hmbown/DeepSeek-TUI) (dispatcher deepseek + runtime deepseek-tui). Ele mira especificamente no DeepSeek V4 — a arquitetura da ferramenta, estimador de custos, design de prompts e sistema RLM de sub-agentes paralelos são todos construídos em torno da economia de API da DeepSeek. Licença MIT. v0.8.8 no início de maio de 2026, com releases frequentes.
Claude Code é o agente de terminal first-party da Anthropic, construído em Node.js, distribuído como um único pacote npm. Docs oficiais em code.claude.com. É Claude-model-native: protocolos de tool call, níveis de esforço, /ultrareview, task budgets e Routines são todos features desenhadas pela Anthropic. Requer assinatura Claude ou chave de API. Produto GA com SLA enterprise e suporte.
Tabela de Comparação
| DeepSeek-TUI v0.8.8 | Claude Code (maio 2026) | |
|---|---|---|
| Runtime | Rust, ~12MB RAM em idle | Node.js, footprint base maior |
| Instalação | npm i -g deepseek-tui (baixa binários Rust) | npm install -g @anthropic-ai/claude-code |
| Modelo padrão | deepseek-v4-pro | Claude Sonnet 4.6 / Opus 4.7 |
| Modelos suportados | DeepSeek V4-Pro, V4-Flash; NVIDIA NIM, Fireworks, SGLang (todos DeepSeek) | Família Claude; DeepSeek V4 via env var swap |
| Janela de contexto | 1M tokens (V4-Pro/Flash) | 200K (Sonnet 4.6), 200K (Opus 4.7) |
| Sub-agentes paralelos | RLM: 1–16 filhos V4-Flash, nativo | Task tool: subagentes paralelos, gerenciados pela Claude |
| Sistema de skills | SKILL.md, lê path .claude/skills | Memória de projeto, CLAUDE.md |
| Suporte MCP | Sim, stdio | Sim, stdio |
| Modos de aprovação | Plan (read-only) / Agent (aprovação por tool) / YOLO | Plan mode / auto mode (usuários Max) |
| Modelo de custo | API-metered por token | Assinatura (Pro/Max) ou API-metered |
| Open source | ✅ MIT | ❌ |
| Maturidade | v0.8.x, mantido pela comunidade | GA, mantido pela Anthropic |
| Suporte enterprise | Nenhum | Disponível (planos Teams/Enterprise) |
Diferenças de Arquitetura Que Importam
Par de binários Rust vs runtime em Node
DeepSeek-TUI compila pra binários nativos. O overhead de runtime é mínimo — o projeto reporta cerca de 12MB de RAM em idle, sem processo Node, sem heap V8, e sem interpretador Python em background. Em máquinas de dev com muitos processos concorrentes, isso importa na prática, não só nas planilhas de spec.
Claude Code roda em Node.js, o que significa o garbage collector do V8 e um perfil de memória base maior. Pra maioria dos devs isso é irrelevante — plugins de IDE e language servers deixam essa diferença no chinelo. Pra times rodando agentes em servidores com restrições ou em ambientes CI containerizados, a diferença é real.
Protocolo de tool-call: DeepSeek-nativo vs Anthropic-nativo
O protocolo de tool-call do Claude Code é construído em torno do formato de API da Anthropic — como as definições de tool são estruturadas, como resultados são alimentados de volta, e como loops de agentes multi-turno são gerenciados. DeepSeek-TUI é construído em torno da API da DeepSeek, que expõe um endpoint compatível com Anthropic mas tem seus próprios quirks comportamentais (especialmente em torno de reasoning_content em turns de tool-call, que DeepSeek-TUI lida nativamente).
Quando você roda Claude Code com DeepSeek V4 como backend via substituição de variável de ambiente, você está rodando o loop de tool da Anthropic contra o endpoint Anthropic-compatível da DeepSeek. O mismatch geralmente funciona bem — o suporte de formato Anthropic da DeepSeek é documentado e mantido — mas edge cases existem. O CHANGELOG do DeepSeek-TUI contém fixes específicos pra reasoning_content handling e consistência de transcript de tool-call que Claude Code não precisa implementar porque não roda o modo thinking da DeepSeek nativamente.
Diagnósticos LSP pós-edição no DeepSeek-TUI
DeepSeek-TUI vem com integração LSP: após cada edição de arquivo, ele consulta o language server relevante (rust-analyzer, pyright, typescript-language-server, gopls, clangd) e exibe diagnósticos inline. O agente enxerga erros de tipo, imports faltando e problemas de sintaxe imediatamente após escrever código — antes do humano revisar o diff.
Claude Code não tem integração LSP first-party equivalente. Devs usando Claude Code no VS Code recebem diagnósticos LSP pelo editor, mas o agente em si não recebe feedback diagnóstico estruturado entre edições a não ser que você configure explicitamente um feedback loop na sua configuração de harness.
Estratégia de Modelos — V4 Fechado vs Família Anthropic
O que "harness específico de modelo" realmente troca
A proposta de valor do DeepSeek-TUI depende do DeepSeek V4 ser seu modelo preferido. O estimador de custo é calibrado pra precificação do V4. O sistema RLM faz fan-out especificamente pra V4-Flash. O design de prompt foi revisado levando em conta o comportamento do DeepSeek V4. O streaming do thinking-mode renderiza o reasoning_content do V4 nativamente. Nada disso transfere se você quiser usar Claude Sonnet 4.6 pra uma tarefa, ou GPT-5.5 pra computer use.
A troca é explícita: se seu modelo de preferência mudar — porque um modelo Claude supera o V4 no seu tipo específico de tarefa, porque você precisa de computer use que só o GPT-5.5 fornece, ou porque a Anthropic lança uma capacidade que importa pro seu fluxo de trabalho — DeepSeek-TUI não oferece caminho de migração pra esses modelos. Você trocaria de ferramenta, não só de parâmetro.
Quando o lock-in de modelo é aceitável, quando não é
Lock-in é aceitável quando DeepSeek V4 genuinamente cobre sua carga de trabalho. Pra fluxos de trabalho agentic sensíveis a custo, geração de código em alto volume, e tarefas que não requerem profundidade de raciocínio frontier, a estrutura de preço do V4-Flash combinada com o RLM do DeepSeek-TUI torna o lock-in uma troca razoável.
Lock-in vira problema quando sua carga de trabalho é heterogênea. Se você está fazendo geração de código rotineira (apropriada pro V4-Flash) e decisões arquiteturais difíceis ocasionais (onde a liderança do Opus 4.7 no SWE-Bench Pro importa), você quer uma ferramenta que roteia pra diferentes modelos por tarefa — ou você aceita rodar duas ferramentas diferentes.
Sub-Agentes Paralelos Comparados
RLM do DeepSeek-TUI (rlm_query) — 1–16 filhos flash
RLM é um primitivo first-class no DeepSeek-TUI: o agente principal chama rlm_query com um prompt ou até 16 prompts simultaneamente, cada um iniciando um filho V4-Flash. Os filhos rodam como chamadas de API independentes contra o mesmo engine assíncrono. Resultados retornam ao agente pai, que os sintetiza e continua. O budget paralelo (1–16) é configurável por chamada; filhos podem ser promovidos pra V4-Pro pras subtarefas mais exigentes.
A aritmética de custo é favorável: filhos V4-Flash são baratos o suficiente pra que um fan-out de 16 filhos pra análise em batch compita economicamente com uma única chamada V4-Pro no mesmo problema.
Padrão Task / subagente do Claude Code
Claude Code suporta subagentes paralelos via tool Task, que instancia agentes Claude independentes pra subtarefas. Subagentes podem operar em paralelo, cada um com seu próprio acesso a tools e contexto. A orquestração é gerenciada pelo runtime da Anthropic — você não configura limites de concorrência da forma que faria com RLM; o sistema cuida do scheduling.
A diferença comportamental: os subagentes do Claude Code compartilham o mesmo nível de modelo que o pai por padrão (você pode configurar CLAUDE_CODE_SUBAGENT_MODEL pra usar um modelo mais barato). O RLM do DeepSeek-TUI sempre roteia pra V4-Flash, tornando o split custo-qualidade entre agente principal e filhos um default arquitetural em vez de uma escolha de configuração.
Como cada um lida com isolamento de estado
Os filhos RLM do DeepSeek-TUI são chamadas de API stateless — recebem um prompt, retornam um resultado, e não têm contexto próprio persistente. O isolamento de estado é completo mas leve: filhos não podem observar o trabalho um do outro, não podem ser interrompidos no meio da execução, e não mantêm histórico de conversa.
Os subagentes do Claude Code têm isolamento mais rico: cada um roda como uma sessão de agente independente, pode fazer suas próprias chamadas de tool, e pode receber diretórios de trabalho ou escopos de arquivo específicos. Pra tarefas de decomposição complexas onde as próprias subtarefas requerem raciocínio multi-turno, o modelo de subagente do Claude Code é mais capaz. Pra análise paralela em batch onde você quer respostas independentes rápido, o modelo leve do RLM é adequado.
Skills, MCP e Superfície de Extensão
Descoberta de skills do DeepSeek-TUI também percorre .claude/skills
DeepSeek-TUI descobre skills de um path com prioridade ordenada: .agents/skills → skills → .opencode/skills → .claude/skills → ~/.deepseek/skills. A inclusão de .claude/skills significa que times que já mantêm skills pro Claude Code podem reutilizá-las no DeepSeek-TUI sem reestruturação — no nível de leitura de arquivo. O agente pode selecionar skills automaticamente via load_skill quando descrições de tarefas batem com descrições de skills.
O caveat de compatibilidade: arquivos de skill são documentos SKILL.md com nome, descrição e instruções. O sistema de memória de projeto interno do Claude Code (CLAUDE.md, contexto em nível de projeto) funciona diferente do modelo de ativação de skill do DeepSeek-TUI. O que transfere bem é o próprio conteúdo do SKILL.md; o comportamento de trigger e ativação difere entre as duas ferramentas.
Paridade MCP e limites de confiança
Ambas as ferramentas implementam MCP via transporte stdio conforme a especificação do protocolo MCP. As abordagens de configuração diferem: DeepSeek-TUI usa deepseek-tui mcp init e configuração TOML; Claude Code usa sua própria configuração de servidor MCP. Funcionalmente, qualquer servidor MCP que funciona com um deve funcionar com o outro — o protocolo é padronizado.
O handling de limite de confiança difere. O modelo de confiança do Claude Code pra chamadas de tool é integrado ao seu sistema de portão de aprovação. O modo YOLO do DeepSeek-TUI bypassa aprovações no nível de sessão, com uma verificação de confiança de workspace. Pra ambientes enterprise onde políticas de confiança por tool importam, o controle mais granular do Claude Code é a distinção relevante.
Perfil de Custo
API-metered (DeepSeek-TUI) vs ancorado em assinatura (Claude Code)
DeepSeek-TUI é puramente API-metered: cada token custa o que a DeepSeek cobra por token no momento da chamada. Não há floor de assinatura, sem precificação por seat, e sem compromisso mensal. Pra uso leve ou variável, isso é econômico. Pra uso pesado e sustentado onde você atingiria os tetos do plano de qualquer forma, a matemática muda pra precificação de assinatura.
Claude Code é primariamente ancorado em assinatura pra uso interativo: planos Pro e Max dão acesso dentro dos limites do plano. Claude Code API-metered está disponível pra times que querem pay-as-you-go, mas o uso interativo é otimizado em torno do modelo de assinatura. O nível de esforço padrão xhigh e o modo auto no Max aumentam o consumo de tokens por sessão — relevante pra quem está fazendo budget mensal de Claude Code.
O que muda quando você escolhe um ou outro pra uma carga de trabalho real
A questão prática não é "qual é mais barato" mas "como fica o custo no meu volume específico e mix de tarefas?" Pra loops de agentes com muito output rodando muitas horas por dia, a economia por token do DeepSeek-TUI pode ser substancialmente menor. Pra times com uso previsível que cabe confortavelmente dentro de um tier de assinatura Claude, a simplicidade do modelo de assinatura supera a otimização por token.
Um cenário específico onde a estrutura de custo importa mais: trabalho de desenvolvimento iterativo com altas taxas de retry — tarefas onde o agente tenta uma abordagem, falha e faz loop. Em volumes altos de tokens de output, precificação por token se acumula. A abordagem paralela RLM do DeepSeek-TUI (girar muitos filhos baratos simultaneamente em vez de tentar novamente em série) foi desenhada parcialmente pra endereçar isso, ao front-loading a análise a baixo custo antes de se comprometer com uma abordagem.
Quando Escolher Cada Um — Framework de Decisão
Escolha DeepSeek-TUI se:
- DeepSeek V4 é seu modelo principal ou único e você quer um agente de terminal desenhado especificamente em torno do comportamento da sua API
- Sub-agentes paralelos RLM são uma parte central do seu fluxo de trabalho e você quer que estejam built-in no agente em vez de precisar de infraestrutura de orquestração
- Binário Rust, footprint de runtime mínimo e diagnósticos LSP pós-edição importam pro seu ambiente de deploy
- Você está confortável com um projeto v0.8.x da comunidade e consegue absorver uma breaking change ocasional entre releases
- Open-source sob MIT sem dependência de fornecedor na Anthropic é um requisito explícito
Escolha Claude Code se:
- Você usa Claude Sonnet ou Opus como modelo principal, ou precisa misturar tiers de modelo pra diferentes tipos de tarefa dentro do mesmo fluxo de trabalho
- Features first-party da Anthropic importam: xhigh effort, /ultrareview em merge gates, task budgets pra controle de custo, Routines pra automação agendada
- Procurement enterprise requer um produto GA com um fornecedor nomeado, SLA e caminho de suporte — DeepSeek-TUI é um projeto pessoal, não um produto enterprise
- Você precisa de capacidades de computer use, que são nativas à arquitetura do Claude Code e não documentadas no DeepSeek-TUI
Onde plataformas multi-modelo e de execução paralela preenchem uma lacuna diferente
Ambas as ferramentas são agentes de terminal single-model — são desenhadas em torno de uma família de modelos e um desenvolvedor por vez. Times que precisam rotear diferentes tipos de tarefa pra diferentes modelos, rodar agentes paralelos em múltiplos codebases simultaneamente, ou integrar agentes de código em fluxos de trabalho mais amplos de CI/CD e revisão estão olhando pra uma categoria diferente de produto. Plataformas como Verdent operam nessa lacuna: multi-modelo, integradas ao IDE, com execução paralela first-party que não requer escolher entre o RLM do DeepSeek-TUI e o tool Task do Claude Code.
FAQ
DeepSeek-TUI consegue trabalhar com modelos Claude?
Não. A configuração suporta NVIDIA NIM, Fireworks e SGLang como providers, mas todos eles servem modelos DeepSeek. Não há caminho pra rotear Claude Sonnet ou Opus pelo DeepSeek-TUI.
Claude Code suporta DeepSeek V4 como backend?
Sim — isso é menos óbvio do que deveria ser. A documentação oficial de API da DeepSeek inclui um guia de integração com Claude Code mostrando as variáveis de ambiente exatas a configurar:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_AUTH_TOKEN=<sua Chave de API DeepSeek>
export ANTHROPIC_MODEL=deepseek-v4-pro[1m]
export ANTHROPIC_DEFAULT_OPUS_MODEL=deepseek-v4-pro[1m]
export CLAUDE_CODE_SUBAGENT_MODEL=deepseek-v4-flashClaude Code então envia chamadas de API pro endpoint Anthropic-compatível da DeepSeek. Você mantém o UX do Claude Code, loop de tool e comandos. O que você perde: features nativas Claude (xhigh effort, /ultrareview, task budgets) não funcionam porque dependem do backend da Anthropic. E o RLM do DeepSeek-TUI, streaming de thinking-mode e prompts calibrados pro V4 não estão disponíveis no lado do Claude Code. É um caminho híbrido válido, mas entenda a lacuna de capacidade antes de se comprometer.
Qual tem tool calls mais precisos em cargas de trabalho reais?
Nenhum benchmark de terceiros existe até o momento desta escrita que compare diretamente DeepSeek-TUI e Claude Code em tarefas reais de código sob condições controladas. Relatos da comunidade favorecem Claude Code pra refatores complexos de múltiplos arquivos e tarefas que requerem seguimento de instrução mais sutil; o feedback da comunidade do DeepSeek-TUI destaca a análise paralela RLM como um diferenciador genuíno pra cargas de trabalho em batch. Trate isso como anedotas, não como evidência. Rode ambos nas suas próprias cargas de trabalho representativas antes de decidir.
Existem benchmarks de terceiros comparando-os?
Não no nível de agente de terminal. Benchmarks de modelo subjacente (SWE-Bench Pro, Terminal-Bench 2.0) existem pra Claude Opus 4.7 e têm alguma aplicabilidade, mas testam comportamento de modelo sob harnesses de benchmark, não o loop de tool completo incluindo RLM do DeepSeek-TUI, design de prompt e feedback LSP. Não há eval publicado que rode o mesmo conjunto de tarefas pelas duas ferramentas sob condições idênticas.
Posso usar ambos no mesmo projeto?
Sim. Eles operam no nível do filesystem e escrevem no git — não há conflito de sessão se você não estiver rodando ambos simultaneamente na mesma working tree. Alguns times rodam Claude Code pra sessões interativas com raciocínio pesado e o RLM do DeepSeek-TUI pra tarefas de análise em batch no mesmo repo. A sobreposição de skills (DeepSeek-TUI lê .claude/skills) torna a manutenção compartilhada de skills prática. Manter ambos configurados tem overhead baixo; decidir qual usar pra qual tipo de tarefa é o trabalho de verdade.
