
OpenAI is pushing Codex toward the whole enterprise. If you ship production code, the story that matters isn't the one in the headlines.
OpenAI just announced it's bringing Codex into the ChatGPT app — its agentic coding agent, folded into the product the rest of the company already uses — plus six role-based plugins, in-place editing, and shareable web apps. The rollout is enterprise-first and lands over the coming weeks, not overnight. Big announcement. Here's the question it skipped: what happens when that agent touches your production code?
That's what this is about. Not the user count, not the demos — the part that decides whether you'd let it near main. And the most telling number from the whole event wasn't ChatGPT's reach. It was one most of the coverage buried, and it should change how every engineer reads this move.
I'll get to that number in a second. First, what actually shipped.
What OpenAI actually announced
The launch event, OpenAI's Intelligence at Work, framed it plainly: this was about getting an agent off the developer's desk and into the rest of the company. Worth saying up front — this was an enterprise-focused event. The target is company knowledge workers, not consumers.
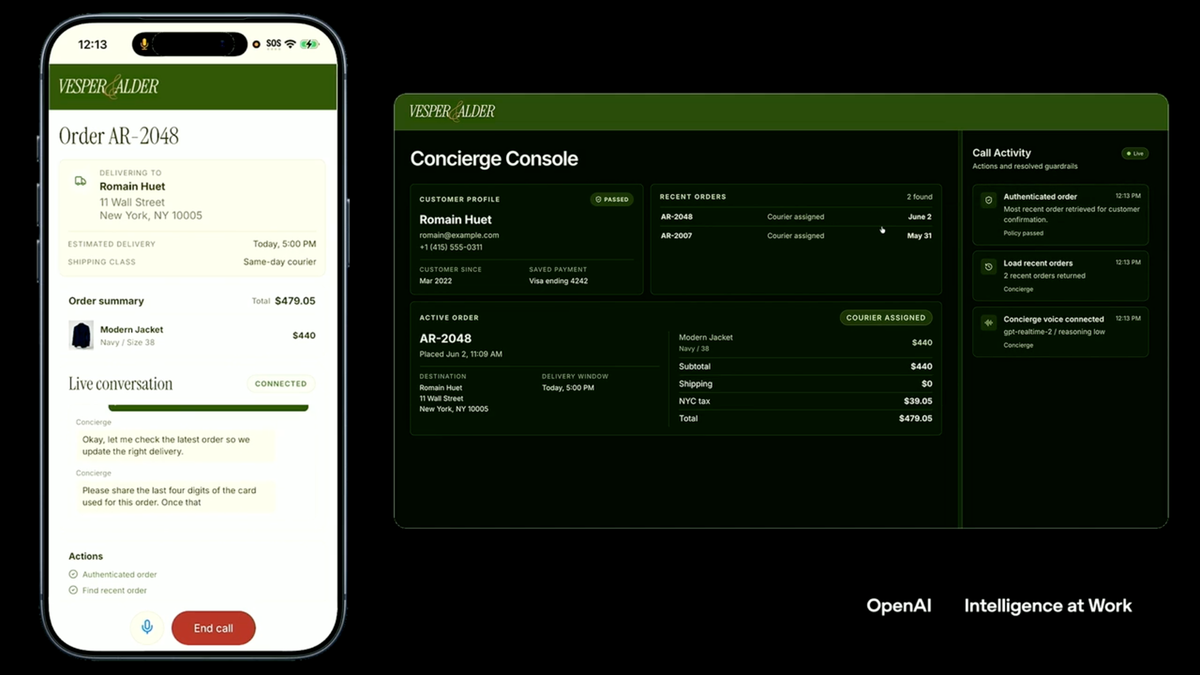
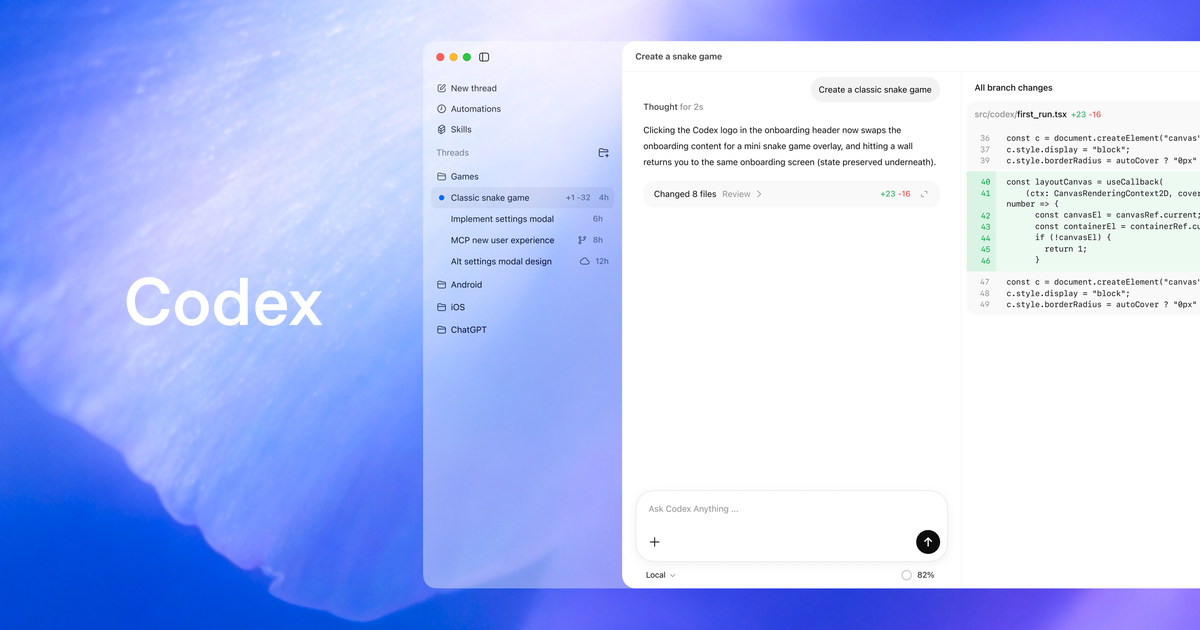
Three things launched, plus one that's still coming. The headline is the part that hasn't happened yet: OpenAI says it plans to move Codex functionality into the ChatGPT app everywhere in the coming weeks, so people won't have to know that "Codex" exists or decide when to switch to it. That's an announced direction, not a done deal — and to be precise, it reads more like Codex capabilities coming into ChatGPT than the two apps merging into one. Alongside it came three updates that are rolling out now: six role-specific plugins, an in-place editing feature called Annotations, and a way to publish shareable web apps called Sites. "Now" comes with asterisks, which I'll flag as we go.
The plugins are the interesting bit. Instead of a generic assistant, OpenAI's Codex for every role and workflow push launched a first batch of six role-specific plugins covering data analysis, creative production, sales, product design, and a couple of finance-flavored roles, each pre-wired with the tools and domain knowledge that job needs. Together those plugins support 62 popular apps and 110 skills — think Salesforce, Snowflake, Figma, Canva — with more roles like legal and strategy consulting on the roadmap. One asterisk: the plugins are rolling out in supported regions in batches, so "launched" doesn't mean every team sees them on day one.
Annotations solves the "almost right" problem. It's an in-place editing tool that lets you select a specific part of the output and tell the agent to change only that, without regenerating the whole file. Select a table, turn it into a chart. Select a paragraph, ask for a source. The rest stays untouched. If you've ever watched an agent rewrite a perfectly good function because you asked it to tweak one line, you understand why this matters.
Sites is the futuristic one. It converts static inputs — a spreadsheet, a doc — into a functional, web-hosted internal app that teammates open through a workspace URL, and unlike a static deck it keeps updating as the underlying data changes. A finance lead turns a spreadsheet into a live scenario planner. A PM turns a plan into a clickable prototype. It's rolling out in preview for Business and Enterprise customers.
Under the hood, the engine doing this is GPT-5.5. The detail engineers should care about: OpenAI says it reaches comparable results on Codex tasks with meaningfully fewer tokens than the previous model, and independent analyses put the saving around 40% on output tokens. That's not a vanity stat. Cheaper intelligence is what makes "an agent for every employee" financially possible in the first place.
So that's the news. Now here's the part that took me a few days to sit with.
The real story: breadth is the strategy, not the feature
Here's the number that reframes the whole announcement. Non-developers — analysts, marketers, operators, researchers — now make up about 20% of Codex's 5 million weekly users, and they're adopting it three times faster than engineers.
Read that again. The fastest-growing group of people using an "AI coding agent" can't code.
That's not a bug in OpenAI's plan — OpenAI's own Codex announcement leans straight into it. Plugins, Annotations, Sites — every one of them is built to take agentic power and hand it to someone who would never open a terminal. The strategy here isn't "make Codex better at engineering." It's "make Codex the default way anyone at a company gets work done," and the distribution muscle behind that — dropping it into ChatGPT instead of a separate app — is genuinely formidable.

I think this is the right move for OpenAI. I also think it quietly creates a fork in the road for the rest of us.
Because the things that make an agent great for a marketer building a dashboard are not the same things that make it trustworthy for a principal engineer refactoring fifty thousand lines of code. Breadth optimizes for "anyone can do anything." Production engineering optimizes for something much less glamorous: this won't break, I can verify it before it ships, and I can run three of these in parallel without them stepping on each other.
Those are different problems. And a tool racing to serve every role in the enterprise is, by definition, not optimizing for the hard edges of your codebase.
What "an agent for every role" still doesn't solve for production code
Let me be concrete, because abstractions are cheap and engineers don't trust them.
Picture the work that actually eats your week. A multi-module refactor where one wrong import cascades into forty files. Three features in flight at once, each touching shared code. A bug that only reproduces under a specific data shape, where the fix has to pass an existing test suite you didn't write and don't fully trust. This is the unglamorous middle of software engineering, and it has nothing to do with whether your agent can also build a mood board.
This "agent for every role" push doesn't address the things that make this work scary:
Parallelism that doesn't collide. Running three tasks at once sounds easy until two agents edit the same file and you spend your afternoon untangling the merge. Real parallel work needs isolation, not just more tabs.
Planning before execution. Most agents are eager to write code. On a complex change, eagerness is the enemy — you want the thing to understand the blast radius and propose a plan before it touches anything, so you can catch a bad assumption while it's still cheap to fix.
Verification you can actually trust. "It compiled" is not "it's correct." The gap between those two is where production incidents live. You want the agent to run the tests, see what failed, and fix it — in a loop — before it ever asks for your approval.
In-place editing and shareable web apps are great features. They just don't touch any of this. They make the agent more accessible. They don't make it more reliable on the stuff that ends up in your main branch.
A working checklist: what serious engineering needs from an agent
After testing a lot of these tools on real projects — not toy repos, actual codebases with history and tech debt — I keep coming back to the same five-point filter. If you're evaluating any agent for production work in 2026, run it through this.
Step 1 — Does it plan before it codes? Hand it a vague task ("add JWT auth, don't break the existing session flow") and watch what it does. If it starts writing immediately, that's a red flag on anything non-trivial. The behavior you want is clarification and a structured plan first. I've learned the hard way that an hour of bad assumptions costs more than a minute of planning. A real plan mode pays for itself the first time it catches a misread requirement.
Step 2 — Can it run tasks in true isolation? Ask it to handle two unrelated changes at the same time. The question is whether each runs in its own sandbox or whether they share a workspace and risk corrupting each other. Git worktree–style isolation is the difference between "parallel" as a marketing word and "parallel" as something you'd actually trust on a Friday.
Step 3 — Does it verify its own output? Look for a generate → test → fix loop, not just generation. The agent should be running the test suite, reading the failures, and iterating before it hands you anything. This is the single biggest predictor of whether the code is production-shaped or demo-shaped. The SWE-bench Verified benchmark exists precisely because "passes the existing tests on a real GitHub issue" is a far better signal than "looks plausible."
Step 4 — Does it preserve context across a long task? Long agentic sessions drift. By turn forty the agent has forgotten the plan it wrote at turn three. You want memory that holds onto the things that matter — the plan, the open files, the unresolved issues — and quietly drops the noise.
Step 5 — Can you roll back without fear? Anything that edits your code needs an undo you trust. Preview the impact, roll back a step, fork a task to try two approaches. Without this, you're brave or you're not using it on anything that matters.
Notice what's not on this list: how many business apps it connects to, whether it can build a slide deck, how many people use it. Those are real selling points for a horizontal productivity tool. They're noise when the deliverable is code that ships.
The fork: broad agents vs. deep agents
There's a whole class of tools optimizing for the opposite of breadth — the specialized, developer-facing coding agents like Claude Code, Cursor, Cline, Aider, and a handful of newer multi-agent platforms. They aren't trying to serve every department in the company. They're trying to be reliable on hard engineering work, and they tend to compete on some version of the checklist above: planning, isolation, verification, rollback. How much of each they actually deliver varies a lot, which is exactly why you have to test rather than trust the marketing.
That's the real fork this launch creates. The frontier labs are racing to make agents broad — capable across a thousand kinds of work, distributed to as many people as possible. A separate set of tools is racing to make agents deep — narrower in scope, but trustworthy on the stuff that ends up in production.
Both directions are legitimate, and neither is obviously winning. They're aimed at different problems. The mistake is assuming the same product has to win both, or treating "more users" and "more reliable on my codebase" as the same axis. They aren't, and a tool can lead on one while being mediocre on the other.
When Codex is the right call
I'd be doing you a disservice if I pretended the answer was always "use the specialized tool." It isn't.
If you live inside the OpenAI ecosystem already, if a lot of your "engineering" is really glue work across business apps, or if the people who need agentic power at your company aren't engineers at all — Codex-in-ChatGPT is going to be hard to beat. The distribution alone is a real advantage: your non-technical teammates get capable agents without installing anything or learning a new app, and that lowers the friction for an entire organization in a way a standalone tool can't match. The plugins are genuinely useful for cross-functional work, and the token economics of GPT-5.5 make heavy use more affordable than you'd expect.
Where a specialized agent earns its place is the narrow, high-stakes slice: complex refactors, parallel feature work on a shared codebase, anything headed for production where verification and isolation aren't nice-to-haves. That's not most of the work happening at most companies. But it may be a lot of your work, if you're still reading this far into an article about agent architecture.
Broad tool for breadth, deep tool for depth. Match the tool to the task, not to the hype cycle.
FAQ
Is OpenAI replacing the standalone Codex app with ChatGPT?
Not exactly. The coverage suggests it's more that Codex functionality is coming into ChatGPT everywhere, rather than the two apps merging into one. The goal seems to be removing the "which app do I open" friction for the many businesses that already know ChatGPT but were unsure when to use Codex.
What are Codex plugins, in plain terms?
They're role-specific bundles that pre-connect an agent to the apps, data, and skills a given job uses. The first six cover data analysis, creative production, sales, product design, and finance-adjacent roles, spanning 62 apps and 110 skills, with legal and consulting roles on the way.
What's the difference between Annotations and just re-prompting?
Annotations let you edit one selected piece of the output in place — a table, a sentence, a section — without the agent regenerating the entire file. It keeps the parts you already approved intact, which matters a lot once outputs get long.
Does GPT-5.5 make Codex cheaper to run?
Effectively, for heavy users. OpenAI says GPT-5.5 hits comparable Codex results with fewer tokens, which is what lets it offer generous usage limits despite being a more capable model. Independent analysis puts the token saving around 40% on output, which offsets a per-token price increase for high-volume work.
Is Codex good enough for production code now?
For many tasks, yes — the underlying models are strong on SWE-bench Verified. The real question isn't the model's raw skill, it's the surrounding workflow: does the tool plan before coding, isolate parallel work, and verify before handing you a diff? That's what separates "good enough for a demo" from "good enough to merge."
Should I switch from Codex to a specialized coding agent?
It depends on the work, not the brand. If most of your tasks are cross-functional or glue work across business apps, Codex-in-ChatGPT is hard to beat. If you spend your time on complex refactors, parallel feature work, or anything headed for production, an agent built around planning and verification may serve that better. Plenty of engineers end up running both and choosing per task.
How to actually evaluate this
Skip the launch hype — including mine. Spend an hour this week running your actual work through whatever agent you're weighing: a real task from your backlog, not a demo. Use the five-point checklist — plan, isolate, verify, remember, roll back. Watch where it gets eager, where parallel tasks collide, where it hands you something that compiles but doesn't pass tests.
That hour will tell you more than any announcement, including this one.
The era of "should you use AI to write code" is over. The only question left is which kind of agent fits which kind of work — and now that OpenAI is pushing agentic coding toward every role in the enterprise, not just engineers, that's the question worth getting right.
