
Five design decisions define Symphony's architecture. Each one makes a specific tradeoff. This article works through all five — not to evaluate whether Symphony is worth adopting, but to give you the technical vocabulary to make that judgment yourself. If you're a Tech Lead evaluating whether to introduce Symphony-style orchestration into your engineering system, the decisions that matter most aren't the benchmarks or the GitHub star count. They're the ones embedded in the spec.
Why the Architecture Matters
Symphony is a spec — implementations differ, but the design choices are shared
Every Symphony implementation, regardless of language, has to answer the same questions: how to isolate agent execution, how to represent orchestration state, where to put agent prompts, and what counts as "done." The SPEC.md answers these questions in language-agnostic terms. The Elixir reference implementation is one answer; community ports in TypeScript, Go, and Python are other answers. The design decisions are shared; the substrate is not.
This matters for architecture analysis because the interesting choices aren't "Elixir vs Go" — they're "why does the spec define per-issue workspace isolation rather than shared workspace with locking?" and "why does WORKFLOW.md version agent prompts with the code branch?" Understanding those decisions tells you more about whether Symphony's model fits your engineering context than any benchmark does.
The Spec, Not the Tool
SPEC.md as the contract

The Symphony repository centers on SPEC.md — a Markdown document using RFC-style MUST/SHOULD/MAY language to define service behavior. It covers:
- The normalized
IssueRecordschema (the canonical data structure passed to every agent) - The
WorkflowDefinitionconfiguration schema (the typed structure behind WORKFLOW.md front matter) - The orchestration loop: polling cadence, concurrency limits, dispatch, retry, reconciliation
- The agent lifecycle: workspace creation, prompt rendering, app-server invocation, turn continuation, stall detection
- Observability requirements: structured logging, operator-visible status
The spec uses precise language because it's meant to be implemented, not just read. A compliant implementation can be built in any language. The spec is the contract between implementations.
Why OpenAI deliberately didn't ship a single canonical product
OpenAI has been explicit that it does not plan to maintain Symphony as a product. From the official Symphony announcement, the framing is "reference implementation designed to be studied, forked, or rebuilt." The framing from Zach Brock: "Instead of code, Symphony is first a Spec.md that you can materialize into any programming language you want by passing it to your coding agent of choice." This is a deliberate choice.
The trade-off: a spec-first release gets language portability and community evolution at the cost of fragmentation and implementation quality variance. Teams adopting Symphony must evaluate each implementation separately — or build their own. The benefit is that no single organization is the keeper of the "right" implementation. The cost is that "use Symphony" doesn't mean "run this binary"; it means "implement this protocol."
Elixir + BEAM as the Substrate
Supervision trees for long-running agent runs
The Elixir reference implementation was chosen for a specific capability: OTP supervision trees. In the OTP model, every significant process runs under a supervisor. If the process crashes, the supervisor restarts it with clean state. This is not exception handling — it's a structural guarantee that process failures are isolated and recoverable.
For Symphony's use case — running dozens of simultaneous agent sessions that may each last minutes to hours — this is not a nice-to-have. A single agent process that runs for 45 minutes and then crashes mid-PR should restart without affecting any other agent's session. The OTP supervision tree provides this guarantee structurally: each AgentRunner process has its own supervisor. One failure doesn't cascade.
Elixir also supports hot code reloading without stopping the runtime — a capability noted in the elixir/README.md as "very useful during development." In Symphony's context, this means WORKFLOW.md configuration changes can be reloaded by a running Symphony daemon without terminating active agent sessions. The SPEC defines this behavior explicitly: "The software MUST attempt to adjust live behavior to the new config" and "Implementations are not REQUIRED to restart in-flight agent sessions automatically when config changes."
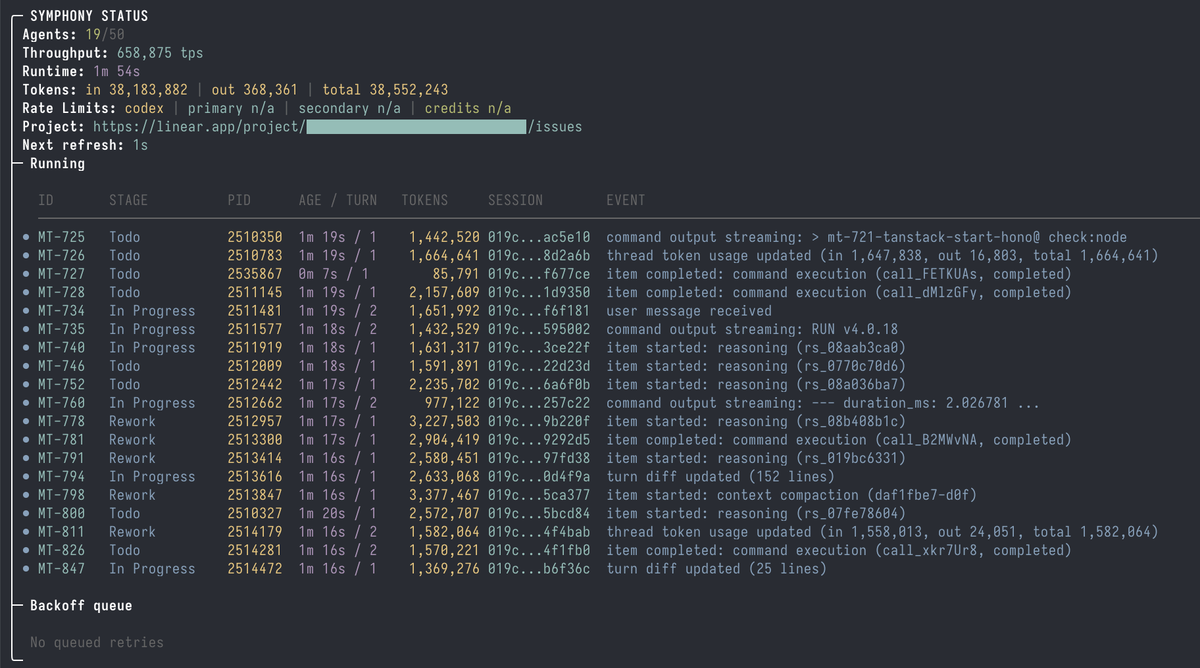
Concurrency model: hundreds of isolated runs without single-failure cascades
The Elixir runtime model maps naturally to Symphony's concurrency requirements. Each issue gets its own Elixir process. Processes are cheap — BEAM handles millions of concurrent processes with isolated heaps. The supervision tree ensures failures in one process don't affect others. The result is a concurrency model that can handle a large board of active issues without requiring shared state management or explicit locking.
Trade-off: stack lock-in for teams not on Elixir
The practical consequence: if you're not an Elixir shop, the reference implementation creates a stack dependency you didn't have before. Adopting the Elixir reference means operating Erlang/OTP in production, managing mise or similar Erlang version tooling, and having someone who can read Elixir when something breaks.
The spec's language-agnostic design is the explicit answer to this problem: build Symphony in your language of choice. But that answer comes with a significant effort cost — implementing a production-grade Symphony from the spec takes weeks, not hours. OpenAI stress-tested the spec in TypeScript, Go, Rust, Java, and Python, but those ports were validation exercises, not production-ready implementations.
Per-Issue Isolated Workspaces
One filesystem workspace per issue identifier
The SPEC defines a Workspace as "filesystem workspace assigned to one issue identifier." Each dispatch creates a fresh directory and runs the after_create hook — typically a git clone of your repository. The agent session for that issue runs exclusively within that directory. The agent's working directory for every turn is the per-issue workspace path.
This is the minimal isolation primitive: filesystem isolation via separate directories. Agents running in parallel cannot read or write each other's workspaces because each one clones the repo independently.
Why isolation is the safety primitive
The design choice to clone per issue rather than share a single checkout is load-bearing. With a shared checkout and branch-per-issue, concurrent agents face concurrent writes to the same filesystem — which requires locking, conflict detection, and merge orchestration at the tool level. Per-issue isolation removes the problem: agents can write freely within their workspace because nothing else is reading it.
The SPEC extends this to workspace lifecycle management: cleanup for terminal issues happens at startup (for issues that finished before a restart) and during reconciliation. Active workspaces persist until the issue reaches a terminal state.
What "isolated" actually buys you and what it doesn't
Filesystem isolation means agents can't observe each other's in-progress changes. What it doesn't provide:
Not network isolation. Agents in separate workspaces run in the same environment and can make outbound network requests to the same services. If Agent A is testing against a shared staging database, Agent B can interfere with A's test results by running concurrent tests.
Not credential isolation. Both agents inherit the same environment variables. A credential scoped to your organization's GitHub rather than a specific repository is accessible to all agents.
Not prompt injection protection. The Linear issue description is rendered into the agent prompt. An issue created with adversarial content can inject instructions into the agent session. The workspace boundary doesn't filter input.
These are not gaps in the implementation — they're gaps in what filesystem isolation can provide. Addressing them requires additional layers the spec defers to implementors.
WORKFLOW.md — Agent Contracts as Code
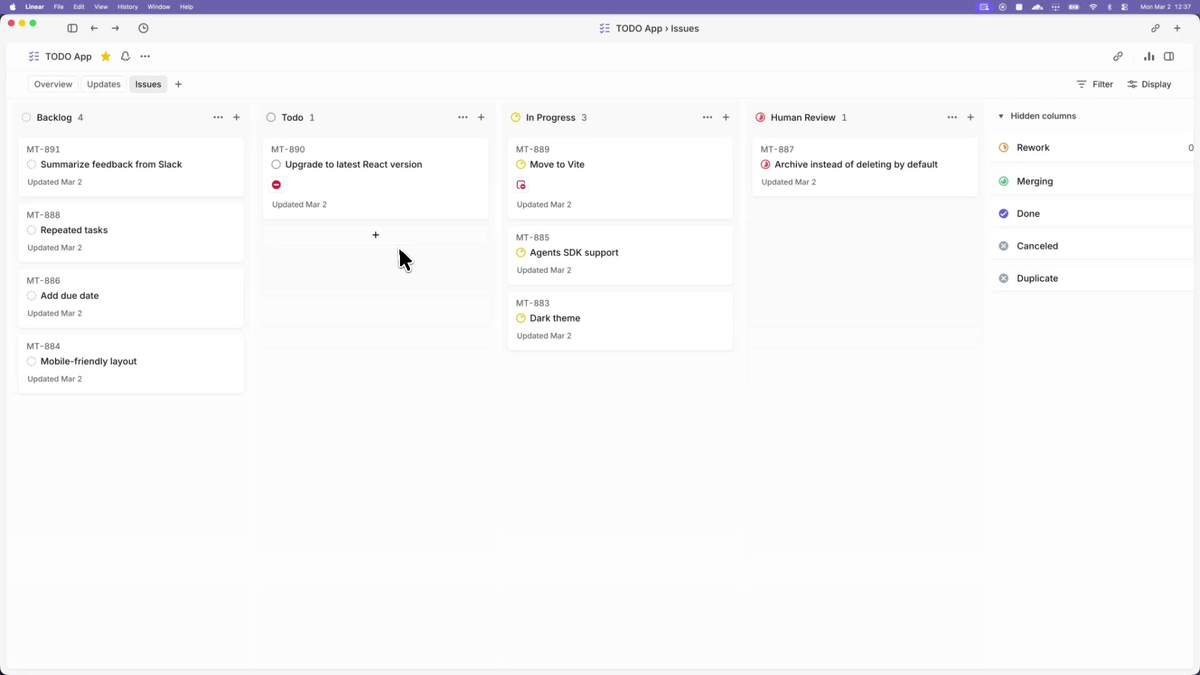
Prompts and runtime settings versioned with the branch they touch
The most architecturally significant decision in Symphony is not the supervision tree or the workspace isolation — it's WORKFLOW.md. Agent prompts live in the repository, versioned with the code. When the agent checks out a branch, it reads WORKFLOW.md from that checkout. An agent working on a branch from three months ago follows the three-month-old agent instructions.
This is the correct design for a code-coupled orchestration system. Instructions that tell agents how to handle the codebase should version with the codebase. A refactor that changes the module boundary conventions should also change the WORKFLOW.md instructions that tell agents which modules to touch for which task types.
Why this is the most important architectural decision in Symphony
The alternative — storing agent instructions in a central config file outside the repo — creates a version skew problem. The agent in the workspace reads its task context, but follows instructions tuned for a different version of the codebase. On long-lived branches or in repos with active development, the mismatch accumulates.
WORKFLOW.md also makes the agent contract auditable. The prompt that will run for a given issue is visible in the repository at the relevant commit. Code review for WORKFLOW.md changes can happen alongside code review for the code changes that motivated them.
What goes wrong if you forget to update WORKFLOW.md alongside refactors
If you rename the module convention that WORKFLOW.md tells agents to follow, agents on new branches will follow the old instructions. They'll create modules in the old pattern, which won't integrate with the new code without correction. The symptom is agent output that passes CI but violates conventions — the kind of error that shows up in code review, not in tests.
The practical mitigation: treat WORKFLOW.md as part of the definition of done for refactors. If the refactor changes how agents should interact with the codebase, the refactor PR should include a WORKFLOW.md update.
The Implementation Run as a State Machine
Linear ticket statuses as the source of truth
Symphony's orchestration state lives in two places: in-memory in the running Symphony process, and in Linear. The SPEC is explicit: "Single authoritative in-memory state owned by the orchestrator." Linear provides the durable source of truth. On restart, Symphony reconciles in-memory state by fetching the current state of active issues from Linear.
This design choice eliminates a database dependency for orchestration state persistence. There is no separate state store — Linear IS the state store. The trade-off: Symphony's state recovery is bounded by Linear API availability. If Linear is unavailable during a Symphony restart, reconciliation waits.
The ticket status model is a state machine: issues flow through active_states (eligible for dispatch) toward terminal_states (["Closed", "Cancelled", "Canceled", "Duplicate", "Done"] by default). Symphony doesn't manage the state transitions directly — agents make those transitions as part of their work, using the tools provided to them.
Polling, claims, retries, reconciliation
The orchestration loop runs on a configurable tick cadence:
- Fetch active candidate issues from Linear
- Check each against concurrency cap and current claims
- Dispatch available slots to new agents
- Reconcile: detect stalled or crashed runs and requeue
Retry backoff is specified in the SPEC: delay = min(10000 × 2^(attempt-1), max_retry_backoff_ms) with a default maximum backoff of 300 seconds. This is not configurable per-issue; it's a single backoff curve across all retries.
Stall detection works via stall_timeout_ms — if a Codex subprocess stops producing output for longer than the configured threshold, Symphony terminates the worker and queues a retry. The agent restarts in the same workspace, with continuation prompt context indicating it's resuming rather than starting fresh.
Proof of Work — How Symphony Closes the Loop
CI passes and walkthroughs as the merge gate
Symphony's "Proof of Work" concept externalizes the merge decision to CI. The agent's job isn't to declare itself done — it's to produce output that passes your CI gates and reaches Human Review state. The human reviewer decides to merge or not.
This is architecturally significant: Symphony doesn't need to know whether the code is correct. It needs to know whether the agent produced a PR. Correctness is your CI's problem. If CI is weak — false greens, unreliable test coverage — Symphony amplifies that weakness by producing more PRs that pass weak gates.
What this assumes about your CI
The proof-of-work model only works if:
- CI fails reliably on regressions — false positives (CI passes on broken code) convert directly to merged bugs
- CI gates are meaningful — style and formatting failures that don't affect behavior add noise to agent output without catching real problems
- CI is fast enough that agents can iterate — if CI takes 45 minutes per run, agents waiting on CI feedback will stall or time out
These aren't Symphony-specific requirements. They're the same requirements for any automated PR workflow. But Symphony's throughput amplification makes them more consequential: weak CI that was manageable at low PR volume becomes a reliability bottleneck at high PR volume.
Trust Posture Is Implementation-Defined
The SPEC is explicit: "Implementations are expected to document their trust and safety posture explicitly. This specification does not require a single approval, sandbox, or operator-confirmation policy."
This is a deliberate design choice. Symphony operates across a wide range of deployment contexts — from solo developers running agents on personal projects to organizations running agents on shared codebases with sensitive integrations. A single mandated trust posture would be either too permissive for some contexts or too restrictive for others.
The consequence: every Symphony implementation must define and document its trust boundary. The reference Elixir implementation defaults to safer Codex settings (sandbox approval required, rule checking enabled). That default is not mandated — it's the reference implementation's choice.
Where each implementation must make its own call
- Approval policy: what Codex operations require confirmation vs auto-approve
- Network egress: whether agent workspaces have unrestricted network access
- Credential scope: how broadly environment credentials are passed to agent sessions
- Input sanitization: whether Linear issue content is sanitized before prompt rendering
- Multi-tenant isolation: whether Symphony can run safely when issue authors are untrusted
The SPEC doesn't answer any of these. It requires implementors to answer them explicitly.
Honest Trade-offs
Linear-shaped issue tracker assumption
The current SPEC version is explicitly written around Linear as the issue tracker. The spec defines an IssueRecord schema and a tracker interface that other systems could implement — but the reference implementation is Linear-specific, and the spec's state machine maps to Linear's status model. Teams on Jira, GitHub Issues, or other trackers face an integration gap. Community ports to GitHub Issues exist; Jira would require building the adapter.
Harness engineering as a hard prerequisite
OpenAI documented this before releasing Symphony: the throughput gains depend on having a "harness-engineered" codebase — hermetic tests, reliable CI, agent-ready issue descriptions. The 500% PR increase figure comes from OpenAI's own codebase, which had undergone months of harness preparation before Symphony was deployed. Teams without that foundation will see Symphony expose their gaps, not overcome them.
Multi-tenancy and untrusted inputs as out of scope
The SPEC's "trusted environments" framing is not hedging — it's scope definition. Symphony's design doesn't include multi-tenant isolation, input sanitization, or prompt injection defenses. Running Symphony on a codebase where external contributors can create issues is outside the documented scope.
"500% PR" as an OpenAI-internal data point, not a benchmark
The figure — "500% increase in landed pull requests on some teams" from the OpenAI announcement — is an internal measurement from OpenAI's own codebase under pre-conditions (harness engineering already done, issue hygiene already in place, motivated internal teams) that don't generalize automatically. It's useful as a signal of what's possible under favorable conditions. It's not a benchmark.
How This Compares to Other Orchestration Approaches
Manual Codex CLI / Claude Code sessions
The baseline Symphony replaces is per-session agent supervision — one engineer running one Codex session, approving each step. Symphony's architectural value over this baseline is dispatch automation (agents pick up issues without human initiation) and crash recovery (stalled agents restart automatically). The cost is setup complexity, harness dependency, and Linear integration overhead.
For small codebases or infrequent agent use, the baseline remains appropriate. The architectural value of Symphony's supervision tree and workspace isolation only pays off when the volume of concurrent agent runs is high enough to justify the infrastructure.
Multi-agent platforms with parallel execution and Git worktree isolation
Symphony's workspace isolation model (per-issue filesystem directory) and platforms like Verdent's parallel worktree execution (per-agent isolated Git branch) represent adjacent architectural choices solving the same problem — preventing concurrent agents from interfering with each other — with different design surfaces. Symphony's model is specification-driven, Linear-integrated, and issue-lifecycle-aware. Multi-agent platforms typically handle the coordination layer as a first-class product feature rather than a user-defined spec. The design lineage is contemporary; the implementation paths diverge on what's product-managed vs. user-configured.
FAQ
Why Elixir, given most teams don't run BEAM?
Elixir's OTP supervision trees and process model map directly to Symphony's requirements: concurrent isolated agent sessions, process-level failure isolation, and live configuration reload without session termination. The spec is language-agnostic precisely because the BEAM primitives aren't universally available — the Elixir implementation demonstrates what's possible with ideal substrate. Teams without Elixir should implement the spec in their stack, accepting that they'll need to replicate these guarantees differently.
Can a non-Elixir implementation be a "real" Symphony?
Yes, by spec definition. The SPEC is the contract; the Elixir code is one implementation. A TypeScript implementation that satisfies the SPEC's MUST requirements is as compliant as the Elixir reference. OpenAI validated this by asking Codex to generate TypeScript, Go, Rust, Java, and Python ports during spec refinement — the spec was explicitly designed to be implementable across languages.
What's the difference between an isolated workspace and a Git worktree?
A Symphony workspace is a fresh git clone per issue — a complete repository copy in a separate directory. A Git worktree is a linked checkout of an existing repository that shares the .git directory. Worktrees are more storage-efficient but share the object store with the main checkout; fresh clones are independent. Symphony uses fresh clones because they're simpler to create, clean up, and reason about — no worktree linkage management, no risk of worktree operations affecting the main checkout. The trade-off is disk space and clone time per dispatch.
Does WORKFLOW.md replace prompt engineering?
No — it structures it. WORKFLOW.md is where your prompt engineering lives, versioned with your code. The agent receives the rendered WORKFLOW.md body as its task prompt. Well-written WORKFLOW.md instructions are the result of good prompt engineering; WORKFLOW.md is the delivery mechanism. The work of figuring out what instructions produce reliable agent behavior is not removed by Symphony — it's formalized and versioned.
Is Symphony OpenAI's bet on autonomous agents over copilots?
The design orientation is clear: Symphony is built around agents that pull work from a tracker rather than receive tasks interactively. Zach Brock's framing — "changing their goal to 'convince a human to merge this code' is the clear next phase of software engineering" — signals the intended direction. Whether that constitutes a bet against copilots or alongside them is framing, not architecture. Symphony is designed for batch autonomous execution. Copilots are designed for interactive assistance. Both have their place in the same engineering workflow.
Related Reading
