
By Hanks, Engineer · June 11, 2026
Claude Fable 5 is capable, slow, expensive, and occasionally on a leash. Here is the only usage pattern that makes the price make sense.
Two days ago Anthropic shipped Claude Fable 5, and I've spent most of the time since then pointing it at real work instead of toy prompts. Short version: it is the most capable coding model I have used, it is slow, it is expensive, and every so often it refuses something and quietly hands the job to a weaker model. My take after two days is narrow. This is a model you bring in for specific hard work, not one you leave running.
How I tested: two days, single operator, on real tasks rather than benchmark prompts — a codebase migration, two multi-file refactors, and a few long-running agent sessions inside VS Code. The impressions below are deliberately scoped to that window; where I lean on numbers I couldn't generate myself, I link the source so you can check it directly.
The shape of the release explains most of the friction, so start there.
Two models, one set of weights
Fable 5 is the first publicly available model in what Anthropic calls the Mythos tier, which sits a step above Opus 4.8. There are really two products here. Fable 5 is the one you and I can call, at the API id claude-fable-5. Mythos 5 is the same underlying model with the safety classifiers stripped off, locked behind the Project Glasswing partner program. Same weights, different leash.

The public version is wrapped this tightly because of the cyber angle. The earlier Mythos Preview from April was held back specifically because it was unusually good at finding software vulnerabilities. Fable is the answer to shipping that capability without shipping an autonomous exploit engine.
The specs that matter: a 1 million token context window, up to 128k tokens of output, a January 2026 knowledge cutoff, and an adaptive thinking mode with effort levels instead of a reasoning toggle. Pricing is $10 per million input tokens and $50 per million output, double Opus 4.8 and the most expensive of the major models right now.
Where the capability actually shows up
Simon Willison called Fable's defining quality "the big model smell," and that is the right phrase. It knows more, it plans further ahead, and it holds a thread across a long session without losing the plot.
The capability is not uniform, and that matters more than the headline. On ordinary chat and one-shot questions, several early testers said it did not feel dramatically different from Opus 4.8. That matches my experience. Where it separates is the hard, multi-step work that usually falls apart after the third or fourth tool call: codebase migrations, multi-file refactors, long-running agent sessions, UI implementation that checks its own work.
I do not care much about the full Stripe headline — the 50-million-line Ruby migration finished in a day. The useful takeaway is smaller and more believable: Fable can hold enough codebase state that a migration stops feeling brittle. That is what Willison saw too, when Fable solved his Datasette Agent feature and then went a level deeper to fix four issues in his LLM library to support it properly. The claim I trust is the modest one: Fable stays coherent deeper into a task than Opus 4.8 does, and that showed up in my own runs.
What the benchmarks prove, and what they don't
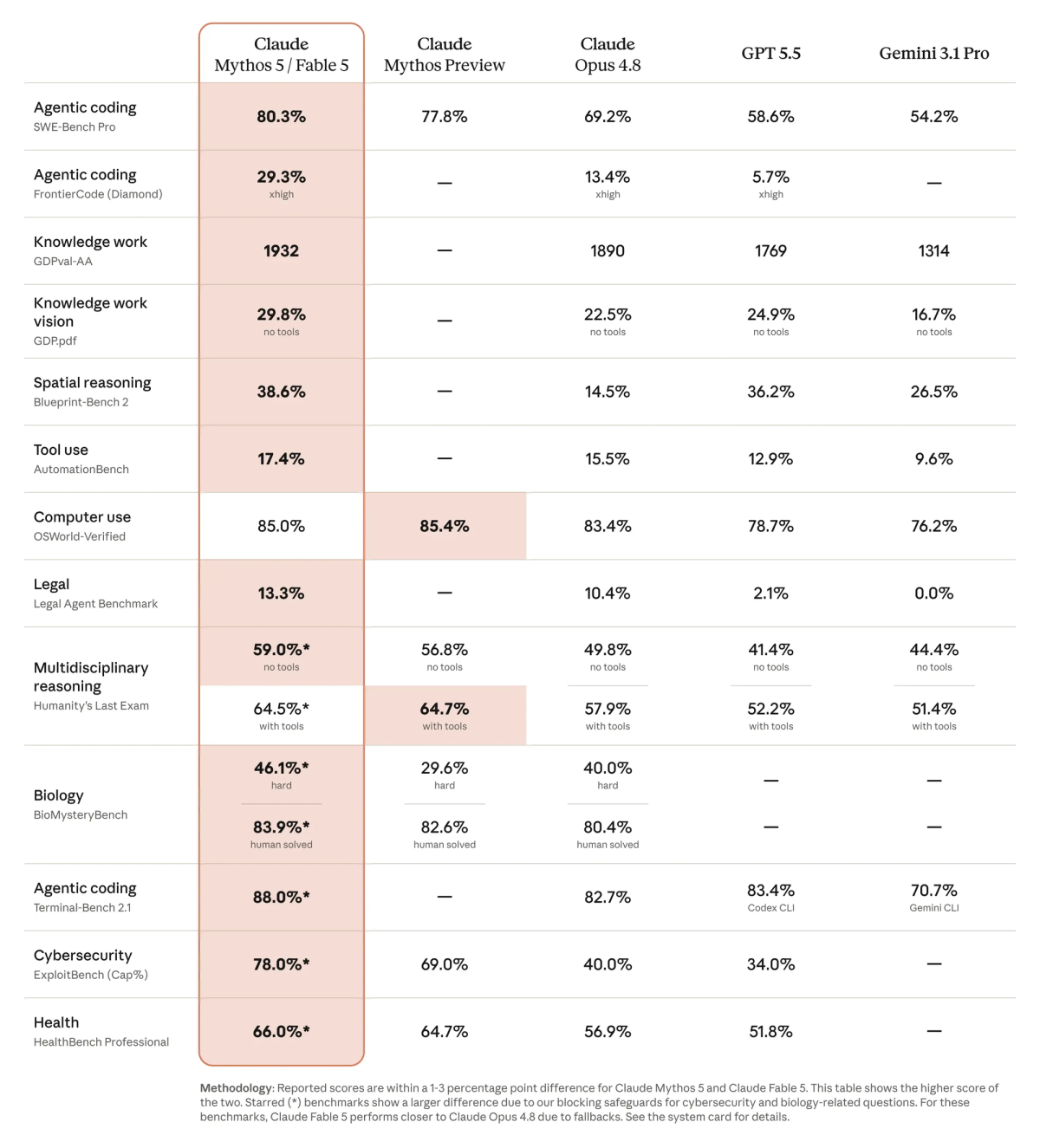
Source: Anthropic's launch comparison table from the official Fable 5 / Mythos 5 announcement (linked under Sources). Asterisked rows reflect Mythos-level capability, not the public Fable API.
The benchmarks prove one useful thing: Fable is built for long-horizon coding. The headline is 80.3% on SWE-Bench Pro against 69.2% for Opus 4.8, with similar gaps on FrontierCode Diamond and Terminal-Bench 2.1.
I would not use the launch table to rank every model, and I would not trust the cyber rows as a guide to the public API. Several of the strongest numbers are starred, meaning they reflect Mythos-level capability. On security and biology tasks the public Fable falls back toward Opus 4.8, so those rows are a ceiling you will not hit. And worth saying plainly: the headline table is Anthropic's own, and at launch most figures came from Anthropic or early-access partners rather than independent labs — reason enough to treat the chart as directional and wait for outside evals before treating it as settled.
The number I'd weight most is CodeRabbit's. On their own code-review benchmark, Fable landed close to Opus 4.8 on finding real issues but worse on precision — 32.8% actionable precision against Opus 4.8's 35.5%, with more comments and more assertive ones. That is the failure mode you do not want in a reviewer, and it points at the rule worth carrying out of all of this. Judge Fable by cost per solved task, not by a leaderboard row. For normal engineering use the signal is simpler than any table: when the task gets longer, Fable separates.
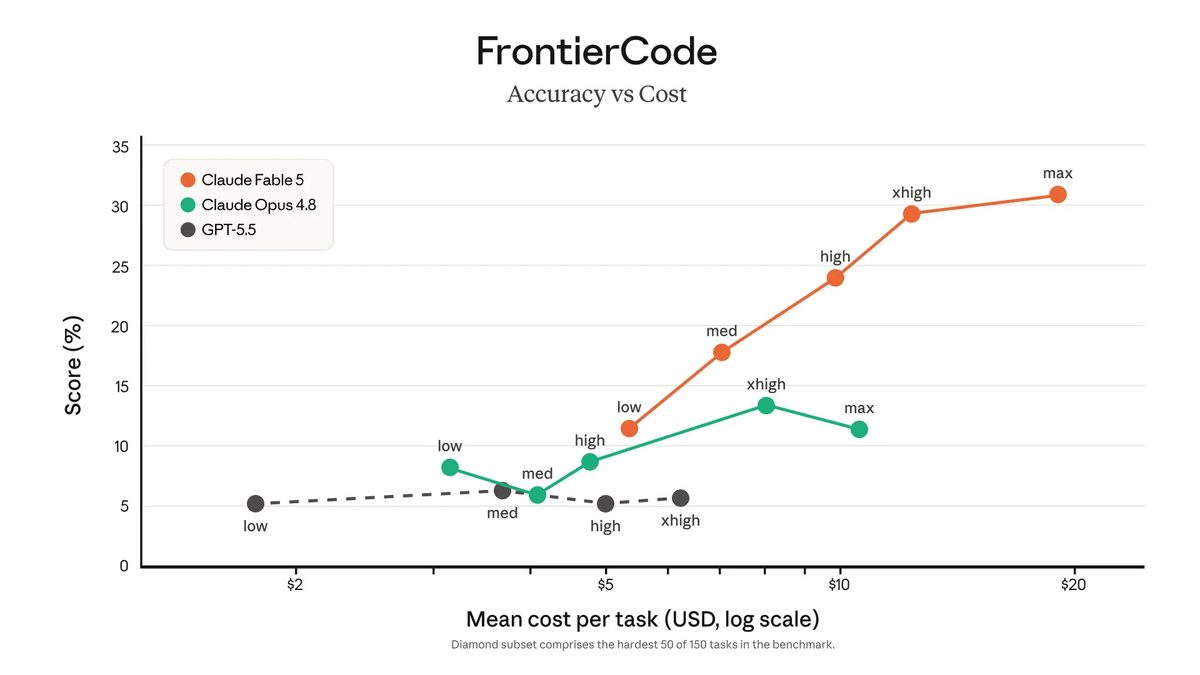
FrontierCode Diamond, xhigh effort: 29.3% for Fable 5 vs 13.4% for Opus 4.8. Figures from Anthropic's launch materials; methodology detailed in the Claude Fable 5 / Mythos 5 system card.
The safety classifiers are the loudest topic for a reason
The classifiers are tuned conservatively and trip often. The API now ships a mechanism to tell you when you have hit one, plus an opt-in option to fall back to Opus 4.8 when a request is rejected.
The complaint I keep seeing, and that I have reproduced, is that this catches legitimate defensive work. Ask about OWASP-class risks and remediation, with nothing resembling an exploit in the prompt, and it still triggers the fallback. If you are building a standard CRUD app you will never feel this. If your work touches security or anything bio-adjacent, it is a real tax.
Auto-fallback is an engineering risk, not a convenience feature. It changes the model in the middle of a workflow, which means your evals, logs, and agent behavior can drift without an obvious cause. Treat a fallback as a production event. Log every one, alert on the rate, and assume your frontier model quietly became Opus 4.8 on exactly the tasks where you wanted the frontier most.
The cost
At $50 per million output tokens, an agent left running on a big task is a fast way to set money on fire. Willison burned $110 of tokens in one normal day on a $100-a-month Max subscription — nearly 90% of it on a single Datasette Agent session. Developers on X are reporting the same in blunter terms: weekly quotas gone in a few multi-hour sessions, north of forty percent of an allowance spent in three sittings.
There is a timing trap too. Fable is free on the Pro, Max, Team, and Enterprise plans only through June 22, after which it moves to usage credits. A lot of the current excitement is coming from people who are not yet seeing the bill. Plan for the bill.
The two-tier split
I think the split is defensible. A model this good at vulnerability discovery probably should ship with gates, and the gap is not cosmetic: behind the gate Mythos scores far higher on offensive-cyber evaluation, while Fable in blocking mode makes effectively zero progress on the same tasks. The awkward part is not the safety call. It is that the gated version shapes who gets to build with the real frontier, and that access sits with a partner list rather than a price.
How I'd put it to work
My rule is simple. Fable plans, cheaper models execute. I use it for architecture, migration strategy, and the final review pass that needs to hold the whole system in its head. I do not leave it running as the default worker model. Sonnet or Opus will carry out a plan Fable laid down at a fraction of the cost, and that one split fixes most of the cost problem while sidestepping the precision wobble on routine work.
Bottom line
The capability is real. The mistake is leaving it on by default. Bring Fable in when the task is expensive enough to justify a senior reviewer, let it set the plan, then hand execution to something cheaper and get out. Two days in, that is the only usage pattern that makes the price make sense.
Related guides
- Claude Opus 4.8 for coding agents — what builders should verify before shipping with the model Fable falls back to.
- Claude Opus 4.7 vs 4.8 — the agentic-reliability and benchmark deltas behind the upgrade.
- Codex vs Claude Code vs Cursor — where each coding agent fits for real engineering work.
- Claude Code vs Cursor for builders — terminal agent vs AI IDE, codebase context, and pricing.
- Why coding agents need a reliable search layer — real-time docs, GitHub context, and agent workflow governance.
