SEAlign, our ICSE 2026 Distinguished Paper, reveals why pairing a capable model with a good agent framework isn't enough, and introduces a training approach that improves a 14B model from 2.8% to 21.8% on SWE-bench Verified.
TL;DR
A strong coding model does not automatically make a strong software engineering agent. In SEAlign: Alignment Training for Software Engineering Agents (ICSE 2026 Distinguished Paper), we show that a 14B model solving competitive programming benchmarks with ease manages only 3.7% on SWE-Bench-Lite and 2.8% on SWE-Bench-Verified when placed inside an agent framework. The root cause is not weak coding ability — it is behavioral misalignment: the model makes poor decisions throughout the engineering process, from misunderstanding instructions to misusing tools to getting stuck in repetitive loops. SEAlign addresses this by post-training the model to make better decisions at critical points in the agent trajectory, improving the same 14B model to 17.7% on SWE-Bench-Lite and 21.8% on SWE-Bench-Verified.
Software Engineering Is More Than Code Generation
Here's a counterintuitive finding: a 14B model that performs well on HumanEval and MBPP — standard code-generation benchmarks — solves only 3.7% of real software engineering tasks on SWE-Bench-Lite.
Why? Because real-world software engineering is fundamentally different from generating a function in isolation. It's long-horizon, context-heavy, and iteratively evolving. Success requires not just writing valid code, but making a chain of correct decisions: understanding the issue, locating the right files in a large repository, choosing the right tools at the right moment, interpreting test feedback correctly, recovering from mistakes, and knowing when to stop.
A model can be excellent at generating code and still fail as an engineering agent. The bottleneck is not raw coding ability — it's whether the model can operate reliably across the full engineering process.
This distinction is at the heart of what we work on at Verdent every day. Our multi-agent architecture is designed around exactly this insight: effective engineering agents need more than strong code generation; they need structured decision-making throughout the plan-code-verify cycle.
What Goes Wrong in Practice
When the 14B model fails inside an agent framework, the failures are behavioral, not generative. Analyzing unsuccessful trajectories reveals three recurring patterns:
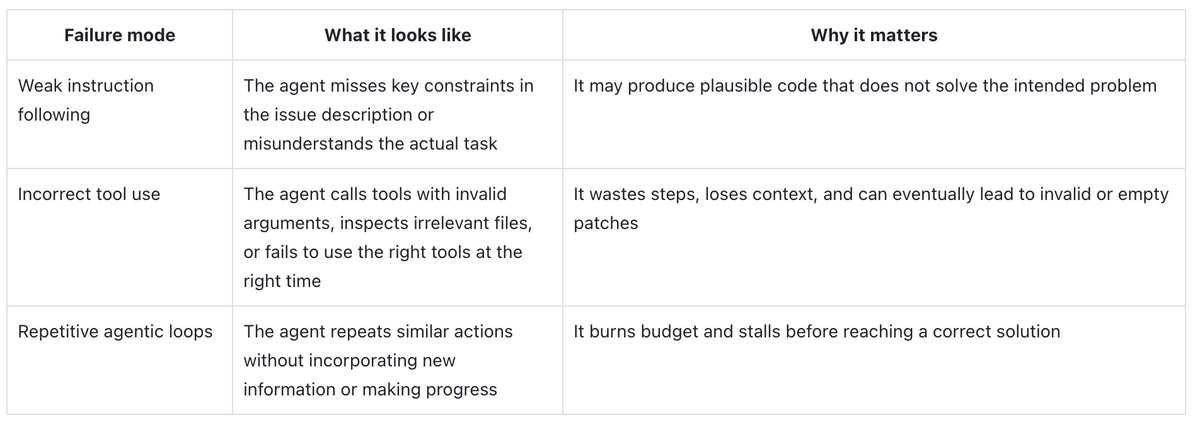
Weak instruction following. The agent misses key constraints in the issue description or misunderstands the actual task. It produces plausible code that doesn't solve the intended problem — like modifying a function signature before fully reading what the user actually asked for.
Incorrect tool use. The agent calls tools with invalid arguments, inspects irrelevant files, or fails to use the right tool at the right moment. These missteps waste context, burn tokens, and can produce empty or invalid patches.
Repetitive loops. The agent repeats similar actions without incorporating new information. It reruns the same failing command without learning from the output, stalling before reaching a solution.
These patterns will feel familiar to anyone who has used coding agents in practice. They are why the quality of an agent's decision trajectory matters just as much as the quality of its final output.
At Verdent, we've observed exactly these failure modes in our own development — which is why features like our Todo list system and code-review subagent were built specifically to keep the agent on track and catch drift before it compounds.
The Problem Is Behavioral Misalignment
These observations point to a deeper issue. Modern software engineering tasks require models to navigate repositories, use tools, interpret intermediate feedback, and adapt plans over time. Yet most coding model training focuses on the final output — the generated code — rather than the quality of decisions made along the way.
A model can be highly capable at code generation while remaining poorly aligned with the decision-making patterns needed in real engineering. The limitation is not one of model scale or coding skill. It is a problem of behavioral alignment.
This is what makes the finding so striking: even when a strong coding model is paired with a strong agent framework, the combined system can still perform poorly on real engineering tasks. A strong model plus a strong framework does not automatically yield a strong software engineering agent.
SEAlign: Aligning Decisions, Not Just Outputs
SEAlign is built on a direct idea: to build better software engineering agents, train models to make better decisions along the trajectory, instead of focusing only on the final solutions.
The intuition is straightforward. Some decisions in an agent trajectory matter much more than others. For example, when attempting to resolve an issue, it is often acceptable—or at least not especially harmful—for an agent to inspect files that are not directly relevant, since this can still contribute to a better understanding of the project. In contrast, actions such as modifying the architecture carry much greater risk and should be treated more carefully. Once a critical decision goes wrong, the entire trajectory can derail, even if the model's coding ability is strong.
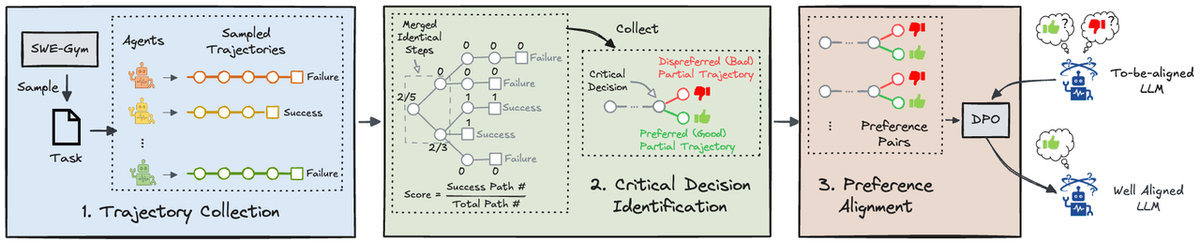
SEAlign trains the model to make better decisions at those critical moment, consisting of three major stages:
- Trajectory collection. The model is placed in a realistic software engineering environment. We record the full sequence of observations, actions, and environment outcomes.
- Critical decision identification. Using Monte Carlo Tree Search, we construct a decision tree over the trajectory and identify key steps where different choices lead to substantially different downstream results.
- Preference alignment. We post-train the model with DPO (Direct Preference Optimization) so that, at critical decision points, it learns to prefer actions leading to successful outcomes over those that don't.
This shifts the training target from code generation in isolation to decision quality under realistic agent execution. SEAlign treats software engineering ability not merely as producing code, but as behaving well throughout a multi-step problem-solving process.
Results
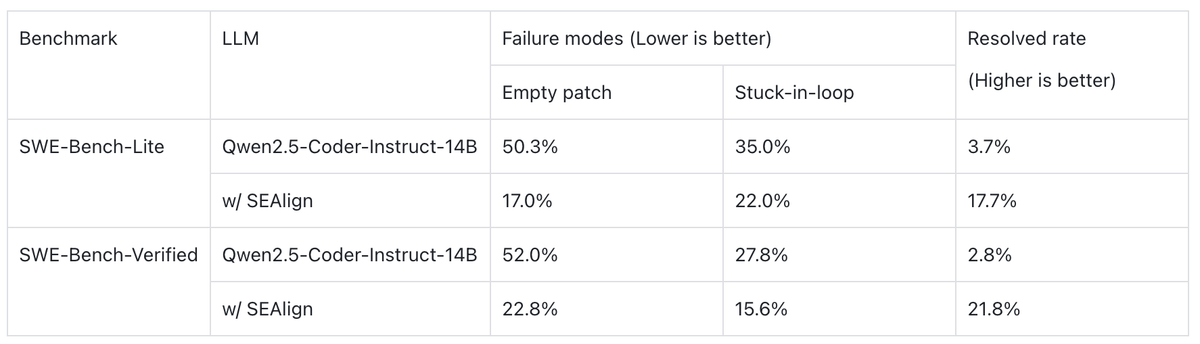
On SWE-Bench-Lite, SEAlign improves Qwen2.5-Coder-Instruct-14B from 3.7% to 17.7%. On SWE-Bench-Verified, from 2.8% to 21.8%.
Beyond headline numbers, the behavioral improvements matter just as much: empty patches caused by invalid tool use drop substantially, and repetitive looping patterns are significantly reduced. This indicates a more reliable agent process — not just a higher benchmark score.
The broader implication: the ceiling of coding agents is not determined solely by model scale or code-generation strength. It is also determined by whether the model is aligned with the decision-making demands of real engineering.
Practical Implications for AI Coding Agents
As the industry moves from code assistants toward autonomous engineering agents, SEAlign suggests several lessons:
Model capability is necessary but not sufficient. A frontier model paired with an agent framework can still fail without proper behavioral alignment. This is why at Verdent, we invest not only in model selection but in the agent architecture that channels model capability into reliable behavior — through structured planning, multi-agent coordination, and built-in verification loops.
Not every decision matters equally. A long-running agent session may involve hundreds of thousands of individual decisions. But only a small fraction truly determines whether the task succeeds or fails. SEAlign's approach — identifying and optimizing these critical decision points — mirrors how Verdent's Todo system structures work: breaking complex tasks into clear stages with explicit checkpoints.
Better outcomes come from securing critical stages, not optimizing everything uniformly. SEAlign improves end-to-end performance by aligning the model's preferences at key decision points. This principle directly informs how we build Verdent: our plan-code-verify cycle, code-review subagent, and automatic testing are all designed to catch failures at the moments that matter most.
Read the Paper
We are honored that SEAlign was recognized as a Distinguished Paper at ICSE 2026. For the full technical details — including the MCTS-based decision identification method and detailed ablation studies — read the paper:
Paper link: https://conf.researchr.org/details/icse-2026/icse-2026-research-track/46/SEAlign-Alignment-Training-for-Software-Engineering-Agent
arXivpreprint: https://arxiv.org/abs/2503.18455
Building on This Research at Verdent
The core insight of SEAlign — that effective engineering agents need behavioral alignment, not just stronger code generation — is a principle we apply daily in building Verdent.
Verdent's multi-agent architecture, structured Todo system, seamless multi-model switching, and dedicated code-review subagent are all designed around the same belief: great engineering agents don't just generate better code — they make better decisions at every stage of the process. From planning to execution to verification, every component of Verdent is built to keep the agent trajectory on track.
If you're interested in experiencing what decision-aligned AI coding looks like in practice, try Verdent — it's the research in action.