
"You've hit your usage limit." You're mid-session, the agent is midway through a refactor, and Cursor stops. The error message offers you three choices: switch to a different model, upgrade your plan, or pay for extra usage. None of those explain what just happened or why.
Cursor's usage model changed fundamentally in June 2025 and has continued evolving. The current structure doesn't match the request-count framing most documentation still uses. Here's what's actually happening when you hit the cap — and what to do about it.
What Cursor Usage Limits Mean
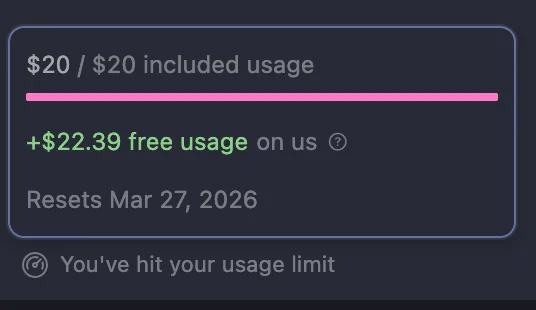
Cursor's Pro plan includes $20 of model usage per month, billed in dollar-equivalent credits tied to actual API token costs. This replaced the old 500 fast requests / unlimited slow requests model in June 2025.
The credits aren't a fixed number of requests — they're a budget. How far $20 goes depends entirely on which model you're using and how much context you're sending:
- Gemini requests: approximately 550 per $20 included
- GPT 4.1 requests: approximately 650 per $20 included
- Claude Sonnet 4: approximately 225 per $20 included
- MAX mode (any model): significantly fewer, as it expands the context window and charges proportionally
When the $20 is spent, Cursor can either stop or continue on-demand at your expense, depending on whether you've set a spend limit in Settings → Billing. Without a configured spend limit in Settings → Billing, overage usage bills automatically in arrears.
The practical implication: "hitting your usage limit" doesn't mean you've made too many requests. It means you've consumed your included dollar amount of compute.
Pro Limits, Rate Limits, and Token Limits
These three terms describe different things, and Cursor has used them inconsistently — which is the root of most user confusion.
Request caps
The old model capped requests. The current model does not cap the number of requests — it caps the dollar value of compute consumed. A single multi-step Agent session that touches 20 files and runs multiple tool calls can consume what used to be 5–10 separate "requests" worth of credits. This is why heavy users hit limits faster than the old documentation suggested they would.
Pro plan in 2026: $20 included usage per month. Reset on your billing date, not calendar month. On-demand usage kicks in automatically when the pool is exhausted — unless you've set a spend limit to prevent that.
Token limits
Tokens are the underlying unit. Every model charges input tokens (what you send — your prompt, context, codebase content) and output tokens (what the model generates) separately. Context length is the main driver of input token cost.
When you add large files to context, open many tabs Cursor is indexing, or use Composer across a large codebase, you're increasing input token consumption per request. A single request with 100K tokens of context costs roughly 4× what a request with 25K tokens costs — same model, same task, different cost.
The Cursor usage limits documentation describes this as: the longer the prompt or context window you send to a model, the more tokens it consumed from your included amount.
"Unlimited" wording and real limits
Cursor's marketing uses "unlimited" in two places that mean different things:
Auto mode is genuinely unlimited on Pro and above. When you use Auto — Cursor's model router that selects based on reliability and cost — usage is billed at flat rates ($1.25/M input, $6/M output) but does not draw from your $20 monthly credit pool. This is the "unlimited usage" that was poorly communicated at launch: it applies only to Auto, not to manually selected models.
Tab completions on Pro are "unlimited" in the sense that they don't count against your $20 credit pool. They're powered by a faster, cheaper model that Cursor absorbs into the subscription. You won't hit a tab completion limit on Pro.
Premium model requests are not unlimited. Manually selecting Claude Sonnet, Claude Opus, GPT-5, or Gemini Pro draws from your $20 pool. When the pool is exhausted, these stop unless you pay for on-demand overage.
The confusion is understandable: Cursor described its June 2025 plan change as moving to "unlimited" usage, but unlimited only applied to Auto mode. Cursor's own June 2025 pricing clarification acknowledged they "were not clear that 'unlimited usage' was only for Auto and not all other models."
What Happens When You Hit the Cap
Error messages
The standard message when your included usage is exhausted:
"You've hit your usage limit."
The prompt typically follows with options:
- Switch to a different model (often Auto or a lighter model that draws differently)
- Upgrade your plan (Pro → Pro+ → Ultra)
- Pay for extra usage on-demand
If you haven't configured a spend limit, Cursor may also offer to continue on-demand and bill the overage at the end of the billing cycle. The on-demand rate mirrors the underlying model API pricing — you're paying Cursor's margin on top of raw model costs.
Slower queues or blocked requests
Rate limits are separate from credit limits. Even on Pro and above, Cursor applies concurrency and throughput limits to prevent any single user from monopolizing model capacity. During peak hours, requests may queue rather than fail. The symptoms are different from hitting the credit cap: requests succeed but slowly, rather than failing with an error.
If you're seeing slow responses without an explicit usage limit error, rate limiting (not credit exhaustion) is more likely the cause. Checking Settings → Usage shows whether your included amount is depleted.
What You Can Do Next
Reduce context
The highest-leverage action before hitting the cap again is reducing context per request. Concrete steps:
Close irrelevant tabs: Cursor indexes open files. More open files = more tokens per context load. Keep only files relevant to the current task open.
Use @-references instead of whole-codebase context: @file and @function target specific code rather than loading everything. This is significantly cheaper than large-context queries.
Summarize prior conversation: Long chat histories compound input token costs on every subsequent message. Starting a new conversation thread resets the accumulated context.
Avoid MAX mode unless necessary: MAX mode expands the context window, which is powerful for complex reasoning across large files — and proportionally more expensive. Use it only when standard context is genuinely insufficient.
Split tasks
Multi-step Agent sessions that span many files in one conversation consume credit faster than targeted, scoped requests. Instead of "refactor the entire auth module," break it into "refactor the login handler" and "refactor the session manager" as separate sessions. Each individual session is cheaper; the total work is the same.
This is especially relevant for solo founders and small teams who have limited monthly credit pools. Task decomposition isn't just good engineering practice — it directly extends how far your included usage goes.
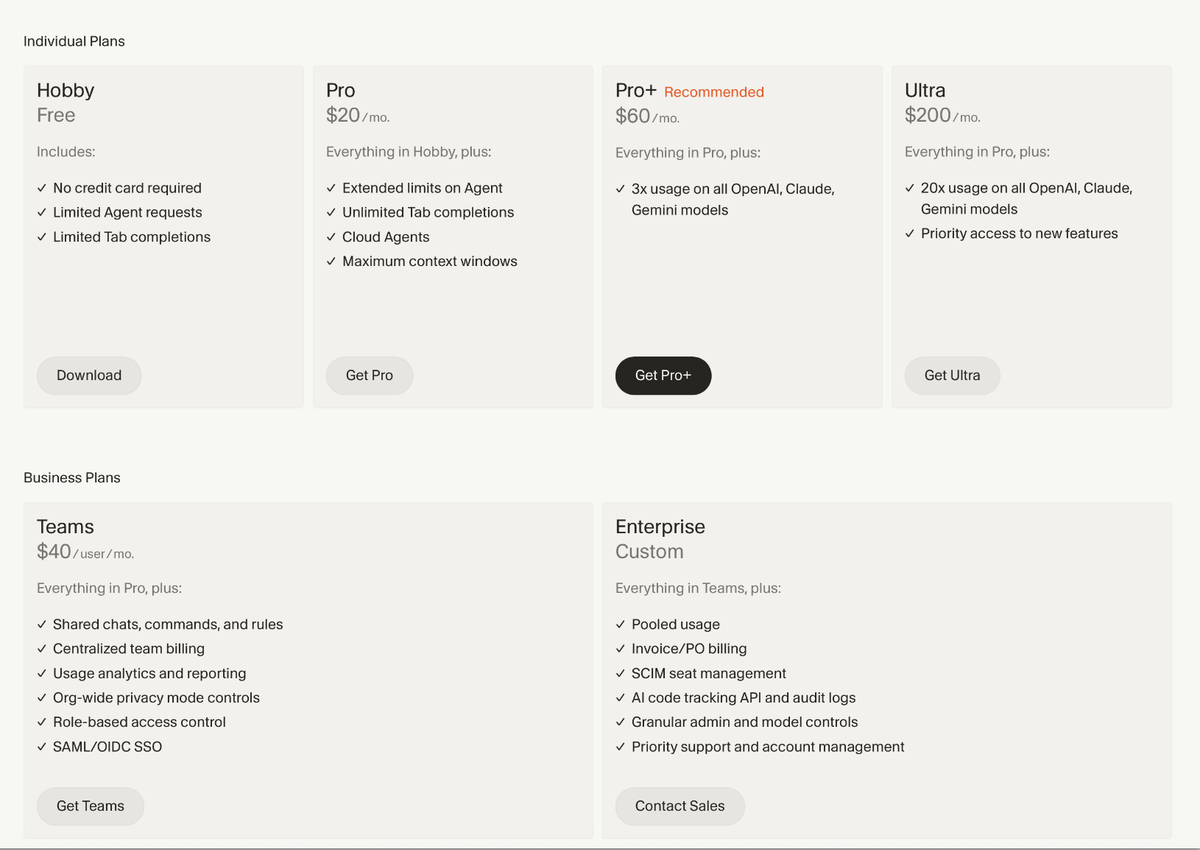
Upgrade or change workflow
Pro+ ($60/month) provides 3× the included credit pool — approximately $60 of model usage — for developers who regularly exhaust Pro within the first two weeks of the month.
Ultra ($200/month) provides 20× the included amount. Heavy users running MAX mode frequently, working with large codebases, or running many Agent sessions per day may find that Ultra is still exhaustible. Cursor's documentation notes that "heavy MAX usage can burn through your included amount in days, even on Ultra."
Auto mode first: For routine work — code completions, simple edits, quick questions — use Auto. It's included without touching your credit pool. Reserve manually selected premium models for tasks where the specific model's characteristics matter.
Bring your own key: Cursor supports connecting your own OpenAI or Anthropic API key. You pay the provider directly at their API rates, which removes Cursor's per-token margin. This can be cheaper than on-demand overage pricing for heavy users, though it requires managing API billing separately.
For workflows that repeatedly exhaust credit limits because of the nature of the tasks — not the amount of work — the question is whether the limiting factor is the credit pool or the single-agent, single-IDE model itself. Multi-agent execution that runs parallel tasks on isolated branches can be more efficient than repeatedly prompting a single agent through sequential steps. Tools like Verdent address this at the orchestration level rather than the per-request level — but that's a workflow architecture change, not a usage limit fix.
FAQ
Why does Cursor say I hit my usage limit?
Your $20 of included model usage (Pro plan) is exhausted for the billing period. This happens faster with manually selected premium models (Claude Sonnet, Opus, GPT-5), larger context windows, MAX mode, and multi-step Agent sessions. Auto mode usage doesn't draw from this pool — if you were using Auto and hit the limit, check whether you had switched to a specific model during the session.
Is Cursor Pro really unlimited?
Auto mode is unlimited on Pro. Tab completions are effectively unlimited on Pro. Manually selected premium model requests are not unlimited — they draw from the $20/month included usage pool. Cursor's June 2025 pricing clarification acknowledged the "unlimited" framing was unclear: unlimited applied only to Auto mode, not to direct model selection. The official pricing page is the authoritative reference for current limits.
How do I reduce Cursor token usage?
Close irrelevant open files (fewer indexed files = less context loaded per request). Use @file and @function references instead of broad codebase context. Start new conversation threads when prior history is long. Avoid MAX mode for tasks that don't require extended context. Use Auto mode for routine work and reserve manual model selection for complex tasks where the specific model matters.
Should I switch tools if I keep hitting Cursor limits?
Hitting limits regularly on Pro means one of three things: your work volume justifies Pro+ or Ultra; your usage patterns are inefficient (context too large, premium models used for routine tasks); or the tasks you're running are structurally better suited to a different tool. If you're exhausting limits because of multi-step, multi-file Agent sessions across a large codebase, consider whether the sequential single-agent model is the right architecture — or whether parallel agent execution with explicit task decomposition fits the work better.
Related Reading
