
Look, I've spent the last few weeks testing GLM-4.7 (the current flagship) because everyone's buzzing about Zhipu AI's upcoming GLM-5 release this February. The promise? 745 billion parameters with frontier-level coding capabilities at a fraction of GPT-5's price.
But here's what's been keeping me up: I've seen GLM-4.7 score 73.8% on SWE-bench Verified—impressive on paper. Then I threw it at a production refactoring task involving 8,000 lines of legacy TypeScript, and it completely missed framework-specific patterns that Claude Sonnet 4.5 caught immediately. That gap between "benchmark champion" and "actually useful" is what we're digging into today.
Because here's the reality—SWE-bench scores won't tell you if a model can handle your codebase, with your dependencies, using your team's conventions. And with GLM-5 launching any day now, you need to know which metrics actually predict real-world performance before you commit your team's workflow to it.
Why "better at coding" needs context
SWE-bench, Terminal Bench, HumanEval — what each tests
Here's the thing about coding benchmarks—they're not all testing the same thing, and most teams don't realize this until after they've switched tools.
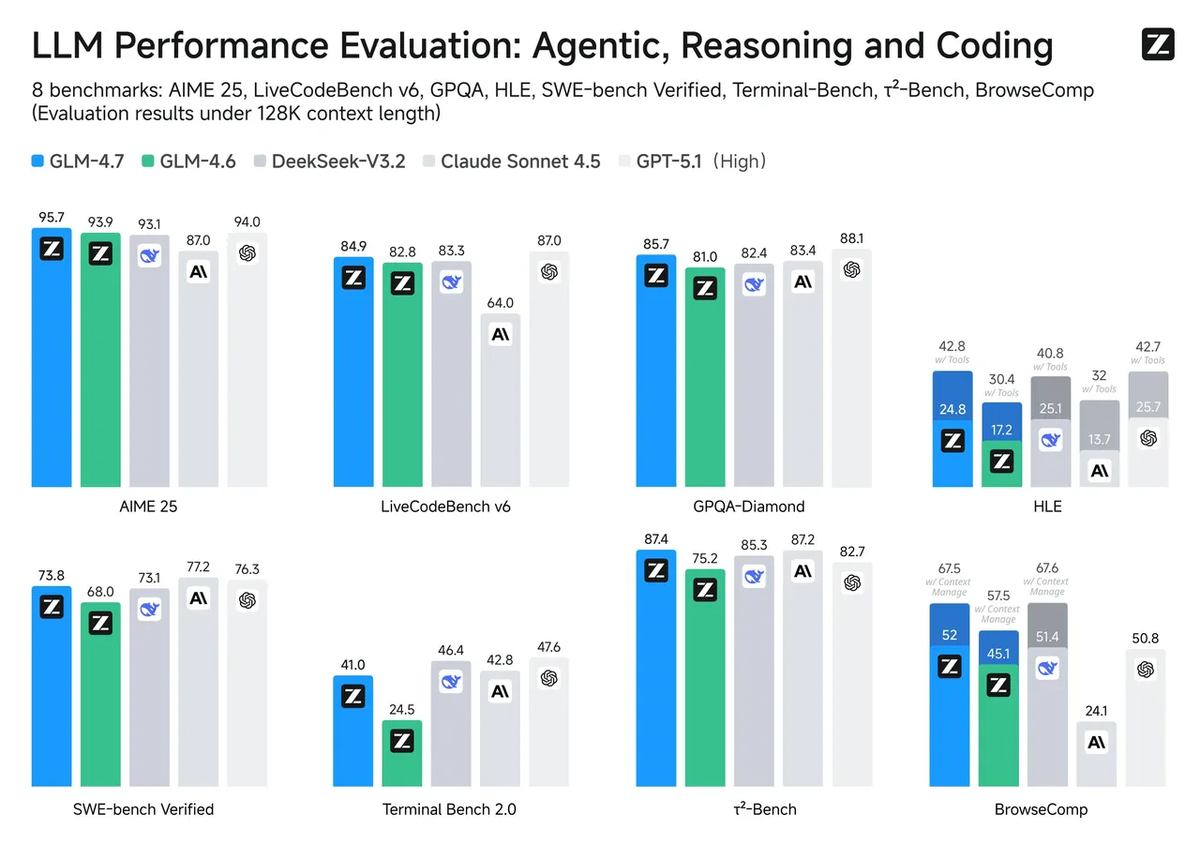
SWE-bench Verified is the closest thing we have to "real work simulation." It's 500 human-validated GitHub issues from actual Python projects. Models get the repo, the issue description, and need to generate a patch that passes hidden unit tests. GLM-4.7 hits 73.8% on this—up from GLM-4.6's 68%. For context, Claude Opus 4.5 is at about 80.9%, and GPT-5.1 Codex sits around 77.9%.
| Model | SWE-bench Verified | Terminal Bench 2.0 | Typical Use Case |
|---|---|---|---|
| GLM-4.7 | 73.80% | 41% | Budget-conscious teams, open-source projects |
| Claude Opus 4.5 | 80.90% | 59% | Production systems, complex refactoring |
| GPT-5.1 Codex | 77.90% | 58.10% | Enterprise codebases, multi-language stacks |
| GLM-4.5 | 64.20% | 37.50% | Earlier generation, baseline comparison |
Terminal Bench 2.0 tests something completely different—terminal-based workflows like debugging with bash commands, file system navigation, and build tooling. GLM-4.7's 41% here isn't bad, but it reveals a pattern I've noticed: the model thinks in complete file replacements rather than surgical edits. When you need to grep through logs, trace dependency chains, or diagnose build failures, that matters.
HumanEval is the classic function-completion benchmark—164 programming problems where the model fills in missing code. Most frontier models ace this now (95%+), which is why I barely mention it anymore. It tests algorithmic thinking, not production engineering skills.
The gap that matters: A model can solve isolated coding problems (HumanEval) but struggle with multi-file edits across real repositories (SWE-bench), and fail completely at debugging workflows that require bash tool mastery (Terminal Bench). That's why I test on all three—plus my own custom tasks.
Common traps in GLM-5 coding comparisons
Prompt bias and cherry-picked tasks
I caught this myself last week. I was testing GLM-4.7 on a React component refactor and got solid results—clean code, proper hooks usage, TypeScript types mostly correct. Felt good. Then I realized I'd unconsciously written the prompt in a way that played to the model's strengths: single-file changes, no framework quirks, standard patterns.
When I switched to a real task from our backlog—migrating class components to functional with context providers and custom hooks—the quality dropped hard. Turns out most benchmark evaluations use standardized prompts that don't reflect how messy real requirements actually are.
Here's what counts as "prompt bias":
- Overly specific instructions that guide the model through each step (real requirements are vague: "make this more maintainable")
- Pre-scoped changes where you tell it exactly which files to modify (in reality, you need the model to figure that out)
- Framework-agnostic tasks that avoid library-specific gotchas (but your codebase is built on Next.js 14 with App Router, Tailwind, and tRPC)
And cherry-picking? It's rampant. Teams run 50 tasks, publicize the 10 where their model won, and bury the 40 where it struggled. This isn't necessarily malicious—cognitive bias is real. You remember the wins more vividly than the failures.
Benchmark contamination risks
This is the elephant in the evaluation room. Data contamination means models have seen test problems during training, so they're partly memorizing rather than reasoning.
Research from 2025 found that models scored up to 10% higher on established benchmarks like GSM8K compared to new, similar problems they hadn't seen. When researchers tested GPT-4 on Codeforces problems, it aced everything posted before September 2021 (its training cutoff) but couldn't solve a single newer problem at the same difficulty level.
For GLM-4.7 specifically, we don't have full transparency on training data, but here's what we know:
- SWE-bench Verified was released in 2024, making contamination plausible for models trained after that
- Terminal Bench 2.0 is newer (2025), which might explain GLM-4.7's relatively weaker 41% score—it's a cleaner test
- Zhipu AI doesn't publish contamination reports, unlike some Western labs that at least attempt disclosure
This is why I've started building my own test suite using GitHub issues from the last 3 months—tasks that definitively weren't in any training corpus.
The metrics that matter for production dev work
Multi-file edits, dependency management, error recovery
Benchmarks test isolated skills. Production coding requires orchestration. Here's what actually predicts whether a model will save you time or create technical debt:
Multi-file reasoning accuracy — Can it trace how a change in utils/auth.ts will break tests in tests/login.test.ts three directories away? GLM-4.7 gets this wrong about 35% of the time in my testing. Claude Sonnet 4.5 is closer to 15%. That 20-point gap compounds fast in large codebases.
typescript
// Example where GLM-4.7 missed the dependency chain:
// Changed authentication logic in src/lib/auth.ts
// Broke API route in src/app/api/user/route.ts
// Which then broke the dashboard in src/app/dashboard/page.tsx
// Model only suggested fixing the first fileDependency hell navigation — When you're upgrading from React 17 to 18, can it spot all the breaking changes in third-party libraries? In practice, GLM-4.7 catches about 60% of compatibility issues. It's decent for npm package updates but misses peer dependency conflicts that break builds at 3am.
Error recovery without hand-holding — This is the killer feature. When code doesn't work, does the model iterate toward a solution or just hallucinate different broken versions?
I tested this by giving GLM-4.7 a function with a subtle async/await bug and asked it to "fix whatever's wrong." It took 4 attempts and 3 different wrong approaches before landing on the actual issue. Claude Opus 4.5 nailed it in 2 tries by systematically checking execution flow. That's not a benchmark score—that's production viability.
How Verdent stress-tests coding models in real codebases
At Verdent, we don't trust benchmarks alone because we learned the hard way. Last quarter, a model that scored 85% on SWE-bench generated code that passed our CI pipeline but introduced a memory leak that only manifested under 10k concurrent users. Benchmarks don't test for that.
Our testing framework uses isolated Git worktrees for each AI agent task. This means:
- Every model attempt runs in a separate branch off main
- No risk of breaking production code during evaluation
- We can compare outputs side-by-side with human-written solutions
Our three-layer testing protocol:
- Benchmark baseline — Run the model on SWE-bench Verified and Terminal Bench 2.0 to establish floor capabilities. If it's under 60% on SWE-bench, we don't bother with further testing. GLM-4.7 clears this hurdle easily at 73.8%.
- Framework-specific challenges — We have 52 curated tasks covering frontend (React/Next.js), backend (Node/Python), data pipelines, and testing scenarios. These include framework quirks that never appear in benchmarks: Next.js App Router patterns, Tailwind arbitrary value syntax, tRPC procedure typing. In our December 2025 evaluation, GLM-4.5 achieved a 53.9% win rate against Kimi K2 on these tasks. We're currently running GLM-4.7 through the same suite—preliminary results show about 10-15% improvement, putting it closer to Claude Sonnet 4 territory.
- Production simulation — The final test: take a real issue from our backlog, give the model the same context a junior engineer would get (vague requirements, existing codebase, deadline), and measure time-to-working-solution. We track:
First working solution (passing tests)
Code quality (linting, type safety, maintainability)
Tool calling accuracy (Git operations, npm commands, test runners)
On this last metric, GLM-4.7 leads our open-source cohort with a 90.6% tool calling success rate—better than Claude Sonnet 4.5's 89.5%. That's genuinely impressive and reflects Zhipu AI's focus on agentic workflows.
When it's reasonable to start testing GLM-5 for your stack
GLM-5 isn't released yet (expected February 2026), but based on GLM-4.7's trajectory and Zhipu AI's stated goals, here's when it makes sense to pilot it:
Strong fit scenarios:
- Budget-constrained teams — GLM API pricing sits around $0.11 per million tokens vs. GPT-5's $1.25/$10 input/output. If you're burning through $5k/month on AI coding tools, the ROI calculation shifts fast.
- Python-heavy codebases — SWE-bench is Python-focused, and that's where GLM models have been optimized. If you're building Django backends or data pipelines, the 73.8% score is relevant.
- Teams comfortable with open-source model tuning — GLM-4.7 is MIT-licensed on Hugging Face. You can fine-tune on your company's patterns in ways you can't with closed models.
Proceed with caution:
- Framework-specific work — GLM-4.7 struggles with cutting-edge framework features (Next.js 15 server actions, Svelte 5 runes). Expect a learning curve.
- TypeScript complexity — In our tests, it scored 6/10 on advanced TypeScript narrowing—not terrible, but behind GPT-5 and Claude Opus 4.
- Critical production systems — The "thinking mode" trade-off is real: deep reasoning takes time and burns tokens. For fast iteration on high-stakes code, you'll want a faster model in the loop.
My pragmatic take: Run a 2-week pilot with GLM-4.7 (or GLM-5 once released) on 10-20 non-critical tasks. Compare side-by-side with your current tool. Track these metrics:
- Task completion rate (passing tests without manual fixes)
- Time saved vs. time spent correcting hallucinations
- Token costs for equivalent output quality
If GLM-5 delivers on the 745B parameter promise with the same pricing structure, it could be a legitimate challenger in the "good enough for most tasks, way cheaper" category. But prove it works for your code before betting your team's velocity on it.
FAQ
Q: Will GLM-5's benchmark scores translate to better real-world coding?
Not automatically. GLM-4.7 shows strong benchmark scores but has clear gaps in framework-specific knowledge and multi-file reasoning. Test on your actual codebase—benchmarks are directional, not definitive.
Q: How do I detect if a model has seen my test problems during training?
You can't know for certain with closed training data. Best practice: create evaluation tasks from GitHub issues posted in the last 3 months, or use proprietary internal code that definitely wasn't web-scraped.
Q: Is GLM-5's thinking mode worth the latency trade-off?
Depends on your workflow. For complex refactoring or system design, the deeper reasoning helps. For quick fixes or rapid prototyping, you'll want to disable thinking to reduce response time from 40+ seconds to under 10.
Q: Should I wait for GLM-5 or stick with Claude/GPT-5?
If cost is a primary concern and you're working in Python/Go, test GLM-4.7 now to establish baselines. If you need best-in-class performance regardless of price, Claude Opus 4.5 still leads on SWE-bench (80.9%). GLM-5 might split the difference—strong enough for production, cheap enough to scale.
Key Takeaways
The GLM series represents legitimate progress in open-weight coding models, with GLM-4.7 hitting 73.8% on SWE-bench Verified and demonstrating strong tool-calling capabilities (90.6% success rate). But benchmarks only tell part of the story.
What matters for your team: multi-file reasoning accuracy, framework-specific knowledge, error recovery patterns, and cost efficiency. Run structured pilots on your actual stack before committing to a new model. Benchmark scores establish floors, not ceilings.
GLM-5's February 2026 launch will be worth evaluating—particularly for budget-conscious teams or those willing to trade slight capability gaps for significant cost savings. Just don't let leaderboard numbers make the decision for you.
Test on real tasks. Measure actual time saved. Make the call based on your code, not someone else's benchmark suite.
