


다시 찾는 코딩의 즐거움 오직 창작에만 집중
새로운 방식의 소프트웨어 개발을 위한 AI 네이티브 파트너.
기간 한정 무료 체험판

Mac용 다운로드 Apple Silicon

깔끔하게 · 빠르게 · 제대로
원하는 내용을 설명하기만 하세요. Verdent가 작업을 처리하고 진행 상황을 공유하며 신뢰할 수 있는 결과를 제공합니다.

AI와의 빠르고 집중된 협업. 불필요한 요소 없이, 방해 없이. 채팅 중심 설계.

고급 에이전트
복잡한 코딩 작업에서도 강력하고 검증된 성능을 제공합니다.

주요 모델 액세스
Verdent 안에서 오늘날 최고의 AI 모델을 선택하세요.

함께 생각하기
모든 작업이 명확한 아이디어로 시작되는 것은 아닙니다. Verdent가 실제로 사용할 수 있는 아이디어로 만들어 드립니다.
아이디어가 아직 모호할 때, Verdent는 적극적으로 질문하여 명확한 작업으로 정리하도록 도와줍니다.

병렬 작업을 위해 설계됨
작업은 보통 한 번에 하나씩 오지 않습니다. Verdent는 모든 것을 병렬로 진행해, 따라잡느라 허둥댈 필요가 없습니다.

아이디어가 떠오르면 여러 작업을 간단히 생성하여 코드가 실행되는 동안에도 생각을 계속 이어가세요.

단순한 코딩 그 이상
전문 분야가 아니더라도 문서화, 데이터 분석, 프로토타입 등 다양한 작업을 처리합니다.
필요한 정보를 수집하고 흩어진 아이디어를 상세한 문서로 변환합니다.

데이터 분석
대규모 데이터셋을 실용적인 인사이트로 쉽게 전환하세요.

프로토타입
아이디어를 발표 가능한 인터랙티브 데모로 빠르게 전환하세요.

신뢰받는
인사이트 및 업데이트

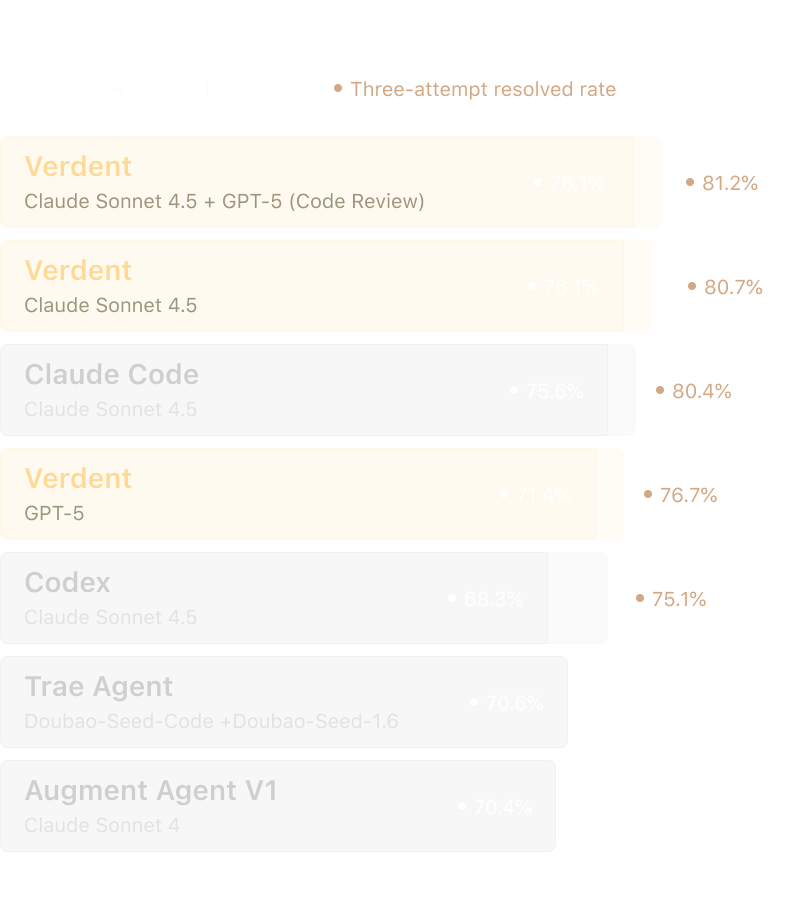
SWE-bench Verified Report
Leading the field with 76.1% single-attempt resolved rate on SWE-bench Verified.

What impact will AI have on the software industry?
Transforming software engineering: from code assistance to AI-native infrastructure.

How do we see the four levels of AI SWE?
Turning AI coding from helper to powerhouse across the entire software lifecycle.
'%3e%3cpath%20d='M140%2070C140%20124.674%20124.674%20140%2070%20140C15.3256%20140%200%20124.674%200%2070C0%2015.3256%2015.3256%200%2070%200C124.674%200%20140%2015.3256%20140%2070Z'%20fill='url(%23paint0_linear_3002_4525)'/%3e%3cpath%20d='M70%200.875C97.3225%200.875%20114.49%204.72198%20124.884%2015.1162C135.278%2025.5104%20139.125%2042.6775%20139.125%2070C139.125%2097.3225%20135.278%20114.49%20124.884%20124.884C114.49%20135.278%2097.3225%20139.125%2070%20139.125C42.6775%20139.125%2025.5104%20135.278%2015.1162%20124.884C4.72198%20114.49%200.875%2097.3225%200.875%2070C0.875%2042.6775%204.72198%2025.5104%2015.1162%2015.1162C25.5104%204.72198%2042.6775%200.875%2070%200.875Z'%20stroke='url(%23paint1_linear_3002_4525)'%20stroke-opacity='0.29'%20stroke-width='1.75'/%3e%3c/g%3e%3cpath%20d='M75.9061%2047.4796C75.9061%2055.3371%2072.9112%2062.4885%2068.0096%2067.8384L67.9996%2067.8485C67.6395%2068.2035%2067.2874%2068.5687%2066.9433%2068.9419L66.9333%2068.952C62.0337%2074.3019%2059.0387%2081.4533%2059.0387%2089.3108C59.0387%2091.8425%2059.3488%2094.3016%2059.935%2096.6498C51.5344%2093.2526%2045.0263%2086.1052%2042.4495%2077.2613C41.6672%2074.5742%2041.2471%2071.7298%2041.2471%2068.7865C41.2471%2061.2559%2043.9979%2054.3728%2048.5394%2049.1056C48.6054%2049.0289%2048.6734%2048.9522%2048.7395%2048.8756L67.7895%2026.8848C70.9646%2030.2759%2073.3653%2034.4114%2074.7017%2039.0048C74.7137%2039.0391%2074.7217%2039.0734%2074.7318%2039.1057C75.496%2041.7645%2075.9061%2044.5726%2075.9061%2047.4796Z'%20fill='%230DC380'/%3e%3cpath%20d='M64.0811%2092.5271C64.0811%2084.6696%2067.076%2077.5182%2071.9776%2072.1683L71.9876%2072.1582C72.3477%2071.8032%2072.6998%2071.438%2073.0439%2071.0648L73.0539%2071.0547C77.9535%2065.7048%2080.9484%2058.5534%2080.9484%2050.6959C80.9484%2048.1642%2080.6383%2045.7051%2080.0521%2043.3569C88.4528%2046.7541%2094.9609%2053.9015%2097.5377%2062.7454C98.32%2065.4325%2098.7401%2068.2769%2098.7401%2071.2202C98.7401%2078.7508%2095.9892%2085.6339%2091.4478%2090.9011C91.3818%2090.9778%2091.3137%2091.0545%2091.2477%2091.1311L72.1976%20113.122C69.0226%20109.731%2066.6219%20105.595%2065.2854%20101.002C65.2734%20100.968%2065.2654%20100.933%2065.2554%20100.901C64.4912%2098.2422%2064.0811%2095.4341%2064.0811%2092.5271Z'%20fill='%230DC380'/%3e%3cdefs%3e%3cfilter%20id='filter0_n_3002_4525'%20x='0'%20y='0'%20width='140'%20height='140'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='BackgroundImageFix'%20result='shape'/%3e%3cfeTurbulence%20type='fractalNoise'%20baseFrequency='1.1428571939468384%201.1428571939468384'%20stitchTiles='stitch'%20numOctaves='3'%20result='noise'%20seed='5981'%20/%3e%3cfeColorMatrix%20in='noise'%20type='luminanceToAlpha'%20result='alphaNoise'%20/%3e%3cfeComponentTransfer%20in='alphaNoise'%20result='coloredNoise1'%3e%3cfeFuncA%20type='discrete'%20tableValues='1%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%201%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20'/%3e%3c/feComponentTransfer%3e%3cfeComposite%20operator='in'%20in2='shape'%20in='coloredNoise1'%20result='noise1Clipped'%20/%3e%3cfeFlood%20flood-color='rgba(0,%200,%200,%200.25)'%20result='color1Flood'%20/%3e%3cfeComposite%20operator='in'%20in2='noise1Clipped'%20in='color1Flood'%20result='color1'%20/%3e%3cfeMerge%20result='effect1_noise_3002_4525'%3e%3cfeMergeNode%20in='shape'%20/%3e%3cfeMergeNode%20in='color1'%20/%3e%3c/feMerge%3e%3c/filter%3e%3clinearGradient%20id='paint0_linear_3002_4525'%20x1='70'%20y1='0'%20x2='70'%20y2='140'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23363636'/%3e%3cstop%20offset='1'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_3002_4525'%20x1='70'%20y1='0'%20x2='70'%20y2='140'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='white'/%3e%3cstop%20offset='1'%20stop-color='%23999999'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
오직 창작에만 집중
나머지는 Verdent가 해결
나머지는 Verdent가 해결
기간 한정 무료 체험판
Mac용 다운로드 Apple Silicon
 Desktop Verdent for
Desktop Verdent for  VS Code
VS Code '/%3e%3crect%20x='3.77149'%20y='9.5144'%20width='13.7143'%20height='13.7143'%20fill='black'/%3e%3cpath%20d='M5.59961%2020.0286L11.5425%2020.0286L11.5425%2021.4L5.59961%2021.4L5.59961%2020.0286Z'%20fill='white'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_3002_4544'%20x1='22.5131'%20y1='4.02857'%20x2='1.48449'%20y2='25.2857'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23E600FA'/%3e%3cstop%20offset='0.597087'%20stop-color='%23FF121D'/%3e%3cstop%20offset='1'%20stop-color='%23FF8C19'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e) JetBrains
JetBrains
전문 개발자들의 선택