
For most agentic coding work, GPT-5.3-Codex outperforms GPT-5. OpenAI says so directly in the official Codex models documentation: "use GPT-5-codex for coding-focused work in Codex, or Codex-like environments; use GPT-5 for general, non-coding tasks." That's the decision in one sentence. But the gap isn't uniform — there are specific task types where GPT-5's general reasoning depth is actually the better fit, and understanding where those are prevents you from over-indexing on a model name.
Quick Positioning
GPT-5 as general-purpose work model
GPT-5 is OpenAI's base frontier model, optimized for broad reasoning, writing, analysis, and mixed professional workflows. Its training wasn't constrained to software engineering tasks — it's designed to work well across domains, which makes it the right model when your task spans coding and non-coding reasoning in the same session.
In Codex surfaces, OpenAI made the routing explicit: GPT-5 is listed as "For general, non-coding tasks" in the model selector. It's not the wrong tool for a coding question, but it's not tuned for the patterns that recur in agentic coding loops: multi-step tool orchestration, long test-fix cycles, navigating large unfamiliar codebases, and recovering from tool failures.
GPT-5.3-Codex as coding-tuned model
GPT-5.3-Codex is a variant of GPT-5 that was additionally trained on agentic coding tasks — PR creation, code review, debugging sessions, frontend work, and Q&A about real codebases. It combines the reasoning depth of GPT-5 with the task-specific pattern recognition built from Codex-specific training data.
OpenAI released it on February 5, 2026, calling it "the most capable agentic coding model to date" at launch and noting it was "instrumental in creating itself" — the Codex team used early versions to debug its own training pipeline, manage deployments, and diagnose evaluation results. That's a meaningful signal about where the model performs: the messy, iterative work of real software engineering, not clean benchmark prompts.
Version History: From GPT-5.1 Codex to GPT-5.3 Codex
What changed across versions
Understanding the version history clarifies why searches for older Codex versions still matter — each version addressed specific limitations:
GPT-5-Codex (original, mid-2025): first Codex-specific variant, coding-optimized but limited to single context window, no Windows support, basic tool use.
GPT-5.1-Codex (late 2025): incremental improvement. The significant addition came with GPT-5.1-Codex-Max — first model natively trained for compaction (operating coherently across multiple context windows), first with Windows environment support, built for multi-hour agentic tasks.
GPT-5.2-Codex (January 2026): improved context compaction, stronger large-scale refactors and migrations, better Windows support, first Codex model with serious cybersecurity capability concerns requiring dedicated safety measures. Still the recommended model for API-key authentication as of May 2026.
GPT-5.3-Codex (February 2026): first unified model combining Codex training data with GPT-5's full reasoning and general knowledge stack. 25% faster than GPT-5.2-Codex. Supports four reasoning effort levels: low, medium, high, xhigh. The coding capability from this model was carried forward into GPT-5.4 as the coding substrate for that general-purpose model.
Why older version queries still matter
GPT-5.2-Codex isn't legacy for API workflows — it's the current recommendation when you can't use GPT-5.5 (which requires ChatGPT sign-in). Tutorials and configuration examples using gpt-5.1-codex or gpt-5.2-codex are often still correct, depending on your authentication path.
Comparison Table
| Dimension | GPT-5.3-Codex | GPT-5 |
|---|---|---|
| Primary tuning | Agentic coding tasks | General-purpose |
| Context window | 200K tokens | 200K tokens |
| Reasoning effort | low / medium / high / xhigh | Standard |
| Tool use in agent loops | Optimized | Competent |
| Long test-fix cycles | Strong | Adequate |
| Code review and refactors | Strong | Adequate |
| Architecture decisions (ambiguous requirements) | Good | Good to stronger |
| Non-coding sessions (writing, analysis) | Adequate | Stronger |
| API availability | Yes | Yes |
| Codex CLI default | Selectable | Not default |
| Pricing tier | Codex-specific (verify current rates) | GPT-5 rates |
Agent loops
GPT-5.3-Codex was specifically trained on the loop patterns that define agentic coding: propose a change, run tests, interpret failure output, revise, repeat. The model was used by OpenAI's own Codex team during its training to debug test results and diagnose evaluation failures — real agent loop work, not just completion-style tasks.
GPT-5 handles agent loops but without the same pattern-trained fluency. In practice, the difference shows up in how the model interprets ambiguous tool output (GPT-5.3-Codex tends to make better inferences about what failed and why) and how many iterations it takes to reach passing tests (typically fewer with the coding-tuned model on software engineering tasks).
Tool use
Both models support OpenAI's full tool use API surface. The functional difference is in how well the model recovers from tool failures. When a shell command returns an unexpected error, a file read returns an unexpected format, or a test runner produces a truncated output, GPT-5.3-Codex's coding-specific training means it has seen more of these failure patterns during training.
GPT-5.3-Codex also supports the xhigh reasoning effort level, which doesn't exist on base GPT-5. For debugging sessions where you want maximum deliberation before each tool call — especially for hard-to-reproduce failures — xhigh effort gives you a configuration lever that GPT-5 doesn't expose.
Code review and refactors
Code review involves reading unfamiliar code, identifying issues, and explaining them clearly. Large refactors involve changing code while maintaining invariants across many files. Both benefit from coding-specific training.
GPT-5.3-Codex is meaningfully better at large-scale refactors: tracking which modules have been updated, which still need changes, and what invariants need to be maintained across the update. For code review specifically, the difference is smaller — GPT-5's strong reading comprehension covers most code review scenarios well.
Availability and pricing
Both models are available in the API. GPT-5.3-Codex pricing is on OpenAI's API pricing page and is model-specific. GPT-5.3-Codex is available in Codex CLI, IDE extension, and Codex app. GPT-5 is available via the Responses and Chat Completions APIs but isn't the default in Codex surfaces.
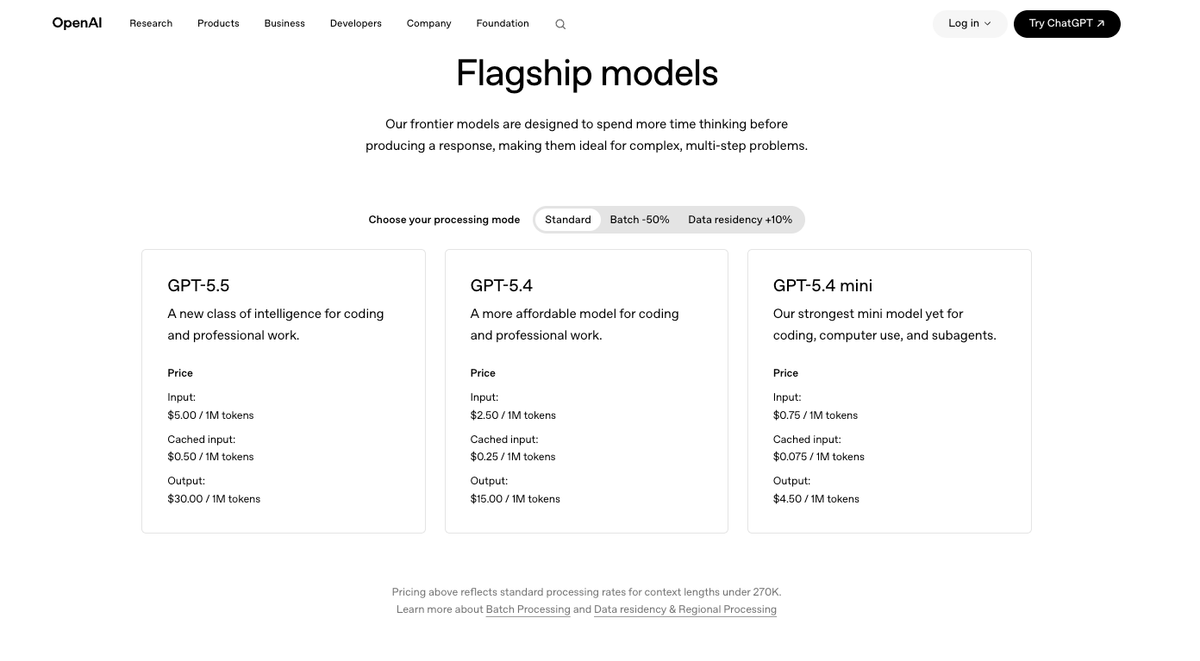
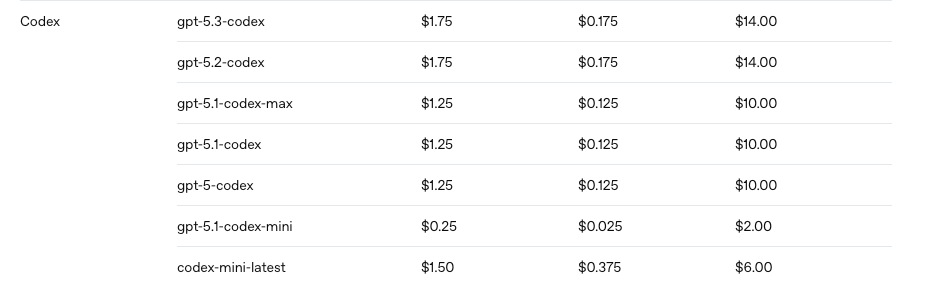
For subscription-based access: Codex CLI defaults to GPT-5.5 (where available) or GPT-5.4 — both of which have GPT-5.3-Codex's coding capability built in. If you're using Codex CLI with ChatGPT sign-in, you may not need to explicitly select GPT-5.3-Codex at all.
Where GPT-5.3-Codex Wins
Long agentic coding sessions. Tasks that involve 50+ tool calls across test-fix cycles, where the model needs to track evolving state across a session, are where the coding-specific training pays off most consistently. GPT-5.3-Codex is more likely to stay on task, correctly interpret intermediate failures, and propose targeted fixes rather than broad rewrites.
Large codebases without documentation. When the agent needs to understand how an undocumented module works by reading the code itself, GPT-5.3-Codex's pattern recognition for code structure tends to produce more accurate conclusions faster.
Test-driven development loops. Writing a test first, then implementing to pass it, then refactoring — this is a pattern GPT-5.3-Codex was explicitly trained on. The model understands the structure of the loop and handles the "test passes but is wrong" scenario more reliably than a general-purpose model.
Windows environment compatibility. GPT-5.3-Codex carries the Windows support improvements from GPT-5.1-Codex-Max and GPT-5.2-Codex. Teams working in native Windows environments will see better tool call behavior and command interpretation than with a model without this training.
Where GPT-5 Wins
Mixed sessions crossing coding and non-coding work. If your session involves reading research papers to inform an implementation, writing architectural proposals for a non-technical audience, or analyzing business requirements before writing code, GPT-5's general capability distribution is more even. GPT-5.3-Codex won't fail at these tasks, but you're paying for coding specialization you're not using.
Ambiguous architectural decisions. When the task is "what's the right approach here?" rather than "implement this approach," GPT-5's broader training on engineering and product reasoning sometimes produces more nuanced tradeoff analysis. GPT-5.3-Codex's bias toward code execution can sometimes translate into proposing an implementation before fully exploring the design space.
Sessions where coding is a minor component. If you're using the model for code generation as part of a larger workflow that involves substantial text analysis, data interpretation, or writing, GPT-5 handles the full session more consistently without the model's attention being biased toward coding patterns.
Decision Framework
Use GPT-5.3-Codex when:
- The primary task is agentic coding: multi-step implementation, debugging, test-fix cycles
- You're working in Codex CLI or IDE extension and want a coding-optimized model
- The session will involve many tool calls and you want the model to recover well from failures
- You need
xhighreasoning effort for hard debugging problems - You're using API-key auth and want the best current API-available coding model (alongside GPT-5.2-Codex)
Use GPT-5 when:
- The session mixes substantial non-coding reasoning with code tasks
- You're evaluating architectural or design decisions before implementation
- The coding component is incidental rather than the primary work
- You're using GPT-5.4 or GPT-5.5 anyway — both already include GPT-5.3-Codex's coding capabilities in a general-purpose package
Consider GPT-5.4 or GPT-5.5 instead of either:
- GPT-5.4 incorporated GPT-5.3-Codex's coding capability with stronger general-purpose reasoning — it's often the right "both" answer
- GPT-5.5 is the current default in Codex when available via ChatGPT sign-in, and is stronger on both coding and reasoning than GPT-5.3-Codex
FAQ
Should I use GPT-5.3-Codex or GPT-5 for coding agents?
GPT-5.3-Codex for most agentic coding workflows. OpenAI's own routing documentation directs coding-focused Codex work to the Codex-variant models. The exception is sessions that blend significant non-coding reasoning with coding tasks — there, GPT-5 or GPT-5.4 (which combines both capabilities) may serve you better.
Is GPT-5.3-Codex worth the extra cost for agent loops?
For high-volume agent loops where task completion rate matters, yes. Fewer failed runs and fewer retry cycles translate directly to lower effective cost per completed task, even if the per-token rate is higher. For low-volume or exploratory work, the cost difference may not be justified. Benchmark on your actual task type rather than the per-token rate.
Can I switch between GPT-5 and GPT-5.3-Codex mid-task?
In Codex CLI, use /model during an active thread to change the model. Be aware that switching mid-task means the new model doesn't have the same pattern recognition for the session's history — it's reading the same transcript but through a differently-tuned lens. For complex ongoing tasks, it's better to finish the task with the current model than switch mid-stream.
Which model is better for code review and refactoring?
GPT-5.3-Codex for large-scale refactors involving many files and invariant tracking. For standard code review of individual PRs, the gap is smaller — GPT-5's reading comprehension handles most code review scenarios well. If your code review workflow involves identifying subtle logic errors in complex concurrent or async code, GPT-5.3-Codex's coding-specific training gives it an edge.
Related Reading
