
Look, I've been tracking China's AI model releases for months now, and GLM-5 is different. Not because of the marketing hype—there's plenty of that going around—but because of what Zhipu AI just pulled off with their hardware stack.
Last month I watched DeepSeek shake up the entire industry with cost-effective reasoning. Now Zhipu AI (Z.ai) is about to drop GLM-5 any day before the Lunar New Year, and if the trajectory from GLM-4.7's performance holds up, this could be the first truly competitive open-weight frontier model that doesn't rely on NVIDIA chips. That matters way more than the parameter count.
Here's what caught my attention: they trained their latest GLM-Image model end-to-end on Huawei's Ascend Atlas 800T A2 servers, proving the entire pipeline works. Now they're scaling that to a 100,000-chip cluster for GLM-5. The timing—February 10-15, 2026—puts them in direct competition with ByteDance's Doubao 2.0, Alibaba's Qwen 3.5, and every other lab racing to launch before the holiday.
This guide cuts through the noise. I'll show you what's confirmed versus what's still speculation, how GLM-5 actually stacks up against GPT-5 and Claude 4.5 on real coding tasks, and—most importantly—what you need to verify in your own environment before betting your production workload on it.

GLM-5 in context — Zhipu AI's fifth-generation model
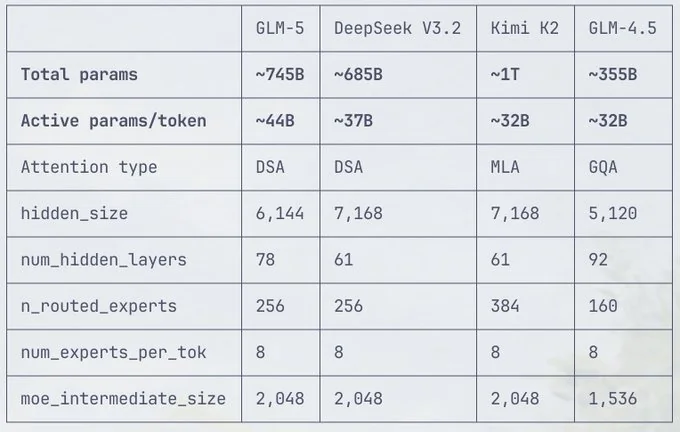
745B total params, 44B active (MoE architecture)
GLM-5 uses a Mixture of Experts (MoE) architecture with approximately 745 billion total parameters and 44 billion active parameters per inference. This isn't just big for the sake of being big—the MoE design means only a subset of the model activates for each request, keeping inference costs manageable while maintaining frontier-level capabilities.

Here's what we know for certain based on Zhipu AI's official announcements:
| Specification | GLM-5 | GLM-4.7 (Predecessor) |
|---|---|---|
| Total Parameters | ~745B | 358B |
| Active Parameters | 44B | 32B |
| Architecture | MoE | MoE |
| Context Window | Expected 200K+ | 200K |
| Training Hardware | Huawei Ascend (100K chips) | Mixed infrastructure |
| Release Window | Feb 10-15, 2026 | Dec 22, 2025 |
The jump from 358B to 745B total parameters represents more than just scale—it's about expanding the model's capacity for specialized knowledge while keeping activation costs reasonable. Think of it like having a massive expert panel where you only consult the relevant specialists for each question, rather than polling everyone every time.
Target strengths: coding, reasoning, agentic workflows
Based on GLM-4.7's documented performance and Zhipu AI's stated development priorities, GLM-5 targets three core areas:
Coding capabilityGLM-4.7 already achieved 73.8% on SWE-bench Verified and 66.7% on SWE-bench Multilingual, putting it in competition with Claude Sonnet 4.5 (77.2%) and ahead of many proprietary models. GLM-5 should improve on this foundation, especially for multilingual codebases and terminal-based workflows.
Here's a simple verification test you can run once the API is available:
# Test GLM-5's code generation with a real-world refactoring task
import requests
def test_glm5_refactoring():
prompt = """
Refactor this Python function to use async/await and add proper error handling:
def fetch_user_data(user_ids):
results = []
for uid in user_ids:
response = requests.get(f"https://api.example.com/users/{uid}")
results.append(response.json())
return results
"""
response = requests.post(
"https://api.z.ai/v1/chat/completions",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "glm-5",
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.7
}
)
return response.json()["choices"][0]["message"]["content"]- Advanced reasoning The predecessor GLM-4.7 scored 42.8% on the HLE (Humanity's Last Exam) benchmark, showing solid mathematical reasoning. For GLM-5, expect improvements in multi-step problem decomposition and long-context reasoning tasks.
- Agentic workflows This is where things get interesting. GLM-4.7 introduced "Preserved Thinking" mode—the model retains reasoning blocks across multi-turn conversations instead of re-deriving from scratch. This reduces information loss in long-horizon tasks, which is critical for autonomous coding agents like Verdent or Claude Code.
The model supports three thinking modes:
| Mode | Use Case | Latency | Cost |
|---|---|---|---|
| Interleaved Thinking | Complex tasks requiring step-by-step reasoning | Higher | Higher |
| Preserved Thinking | Multi-turn agent workflows | Medium | Medium |
| Turn-level Thinking | Granular control—enable/disable per request | Variable | Variable |
For agent-heavy workflows, preserved thinking is a game-changer. Instead of burning tokens re-explaining context every turn, the model carries forward its reasoning state. If GLM-5 improves this mechanism, it could be competitive with Claude 4.5's agentic capabilities.
What's confirmed vs what's marketing
Benchmark claims vs real-task performance
Let's be honest—benchmark scores and real-world performance aren't always aligned. I've seen models ace SWE-bench but struggle with basic refactoring tasks in production codebases.
Here's what's actually confirmed for the GLM series as of February 2026:
Confirmed strengths (based on GLM-4.7 data):
- SWE-bench Verified: 73.8% resolution rate—this is a real measure of fixing GitHub issues
- Terminal Bench 2.0: 41% accuracy for CLI automation tasks
- LiveCodeBench: Competitive with Claude Sonnet 4.5 on algorithmic coding
- τ²-Bench: 84.9 score on interactive tool use, surpassing Claude Sonnet 4.5
What we're waiting to verify for GLM-5:
- Whether the 745B parameter scaling actually improves coding quality or just adds computational overhead
- How well it handles extremely long contexts (200K+ tokens) without degradation
- Real-world latency on Huawei Ascend hardware versus NVIDIA-based deployments
- Cost per token compared to GLM-4.7's already competitive pricing
The performance gap between benchmarks and production is real. For instance, GLM-4.7 shows varying tool usage patterns compared to Claude and GPT-5—Claude uses more search tools, while GLM leans on bash commands. This affects reliability in different workflow types.
Open-weight signals and MIT license expectations
This is where GLM-5 could actually disrupt the market. Zhipu AI has a strong track record of open-sourcing models:
- GLM-4.7: Publicly available on Hugging Face and ModelScope
- GLM-Image: Released with full weights under permissive licensing
- GLM-4.5: Open-weight model competitive with closed-source alternatives
The expectation is that GLM-5 will follow the same pattern—likely released under MIT license within Q1 2026, making it one of the most powerful open-weight models available. Compare this to GPT-5 (closed-source) or Claude 4.5 (closed-source), and you see the strategic advantage for enterprises that want model ownership.
However, there's nuance here. "Open-weight" doesn't always mean "production-ready out of the box." You'll still need:
- Proper fine-tuning for your domain
- Inference infrastructure (or API credits)
- Safety guardrails and content filtering
- Regular retraining as the model drifts
The MIT license matters more for companies that want to:
- Deploy on-premises without vendor lock-in
- Fine-tune on proprietary data without sharing it
- Build commercial products without licensing fees
- Maintain control over model governance and updates
If you're evaluating GLM-5 for enterprise deployment, verify the exact license terms when weights are released—not all "open" licenses are created equal.
Developer verification checklist before adoption
How Verdent validates coding models at task level
At Verdent, we don't trust marketing benchmarks. We run every new coding model through a standardized gauntlet of real-world tasks before even considering integration. Here's the exact process you should follow for GLM-5:
Task 1: Multi-file refactoringCan the model understand dependencies across 5+ files and make coordinated changes without breaking imports?
# Example test case
"""
Given a Python project with:
- models.py (database models)
- services.py (business logic)
- api.py (REST endpoints)
- utils.py (helper functions)
- tests/ directory
Task: Refactor the User model to split email validation
into a separate EmailValidator class, update all imports,
and ensure tests still pass.
Success criteria:
- No broken imports
- All existing tests pass
- New validator is properly tested
- Code follows project style guide
"""Task 2: Terminal workflow executionThis tests the model's ability to work in CLI environments—critical for Verdent's agent workflows. GLM-4.7 scored 41% on Terminal Bench 2.0, but production needs are higher.
Task 3: Long-context code reviewLoad a 50K-token codebase context and ask for architectural recommendations. Does the model actually reference specific files, or does it give generic advice?
Task 4: Multilingual debuggingTest on Go, Rust, TypeScript, and Python simultaneously. GLM-4.7 showed 66.7% accuracy on SWE-bench Multilingual—verify GLM-5 improves this.
Task 5: Agent stabilityRun a 10-turn conversation where the model needs to:
- Create a feature branch
- Implement changes across multiple files
- Run tests and fix failures
- Create a PR with proper description
This stresses the "Preserved Thinking" mechanism and reveals whether the model loses context mid-workflow.
Critical questions to answer through testing
Before you integrate GLM-5 into production, get clear answers to these:
What's the actual cost per resolved coding task?
Don't just look at token pricing. Measure:
- Average tokens per successful task completion
- Re-generation rate when output doesn't work
- Debugging overhead when code has subtle bugs
Expected GLM-5 pricing: ~$0.11-$0.35 per million input tokens (based on GLM-4.x rates), which is significantly cheaper than GPT-5's $1.25 per million tokens.
How does latency compare on your target hardware?
If you're planning to self-host on Huawei Ascend hardware (the only confirmed training stack for GLM-5), measure:
- Time-to-first-token
- Tokens per second during generation
- Memory requirements for 44B active parameters
What's the quality ceiling for your specific use case?
Run blind A/B tests against your current solution (Claude, GPT-5, or whatever you're using). For Verdent's use case:
| Task Type | Claude 4.5 Sonnet | GLM-4.7 | Expected GLM-5 |
|---|---|---|---|
| Full-stack feature implementation | Excellent | Good | TBD |
| Multi-repo coordination | Excellent | Fair | TBD |
| Terminal automation | Good | Fair | TBD |
| Long-context architecture review | Excellent | Good | TBD |
Does the open-weight model actually save you money?
Self-hosting isn't free. Factor in:
- Infrastructure costs (GPUs/Ascend chips)
- DevOps maintenance
- Model updates and retraining
- Safety testing and validation
Sometimes API access is cheaper than self-hosting, especially at lower volumes.
GLM-5 in the competitive landscape (GPT-5, Claude 4.5, DeepSeek)
The February 2026 AI model landscape is crowded. Here's how GLM-5 fits in based on what we know about its architecture and GLM-4.7's performance:
| Model | Total Params | Active Params | SWE-bench Verified | Cost (per 1M tokens) | Open-Weight |
|---|---|---|---|---|---|
| GLM-5 | 745B | 44B | TBD (expect 75-80%) | ~$0.20-0.40 | Expected |
| GPT-5.2 | Unknown | Unknown | 75.40% | $1.25 input / $10 output | No |
| Claude 4.5 Sonnet | Unknown | Unknown | 77.20% | $3 input / $15 output | No |
| DeepSeek V3.2 | 671B | ~37B | ~70% | $0.27 input / $1.10 output | Yes |
| Gemini 3 Pro | Unknown | Unknown | 76.20% | $1.25 input / $10 output | No |
Where GLM-5 likely wins:
- Cost efficiency — If pricing follows GLM-4.x patterns, it'll be 3-10x cheaper than GPT-5/Claude
- Open-weight flexibility — Deploy on-prem, fine-tune without restrictions
- Hardware independence — Proven training on non-NVIDIA stack matters for supply chain resilience
Where it likely struggles:
- Agentic reliability — DeepSeek V3.2 shows weaknesses in multi-tool workflows and long agent loops. If GLM-5 has similar architecture constraints, expect the same issues.
- Vision capabilities — GLM-Image exists, but integration quality versus GPT-5.1's 84.2% MMMU score is unclear
- English language quality — Chinese-first training may show subtle degradation in English tasks
The real competitive differentiator: Huawei Ascend training
This is the part everyone's missing. GLM-5 is being trained on a 100,000-chip Huawei Ascend cluster, making it the first frontier model to achieve full hardware independence from US semiconductor supply chains.
For enterprise buyers, this means:
- Geopolitical risk mitigation — No export control vulnerabilities
- Cost arbitrage — Ascend infrastructure is cheaper than NVIDIA equivalents
- Strategic optionality — Proof that frontier AI doesn't require US hardware
But there's a catch: Huawei's Ascend 910C chips deliver ~80% of NVIDIA H100 performance at FP16 precision. So GLM-5's training likely took longer or required more chips than an equivalent NVIDIA-based run. That doesn't matter for the end product, but it does mean Zhipu AI's training costs were probably higher—which could affect long-term competitiveness if they can't achieve hardware cost parity.
Direct comparison: GLM-5 vs Claude 4.5 Sonnet for coding
Based on GLM-4.7 data and Claude 4.5's published benchmarks:
- SWE-bench: Claude leads (77.2% vs GLM-4.7's 73.8%), but the gap is narrow
- Terminal automation: Claude dominates (60%+ vs GLM-4.7's 41%)
- UI generation: GLM-4.7 improved "Vibe Coding" with cleaner front-end output—competitive advantage for web developers
- Cost: GLM-5 will likely be 8-15x cheaper than Claude for equivalent tasks
For Verdent's use case (multi-agent parallel coding), Claude 4.5 Sonnet remains the gold standard for reliability, but GLM-5 could be viable for cost-sensitive workloads where occasional retries are acceptable.
Direct comparison: GLM-5 vs DeepSeek V3.2
Both models compete in the "open-weight, cost-efficient frontier" category:
- Reasoning: DeepSeek V3.2 excels at math and isolated coding tasks
- Agentic workflows: Both show weaknesses compared to Claude—DeepSeek stumbled on execution, speed, and reliability in full-stack builds
- Pricing: Likely comparable—both targeting $0.20-0.40 per million tokens
- Hardware: DeepSeek trains on both NVIDIA and domestic Chinese chips; GLM-5 is Huawei-exclusive
The choice between them comes down to ecosystem fit. If you're already invested in Zhipu AI's tooling (like GLM Coding Plan integration with Claude Code), GLM-5 is the natural upgrade. If you need rock-bottom pricing and don't care about vendor lock-in, DeepSeek might edge ahead.
FAQ — release date, API access, pricing, context window
When is GLM-5 releasing?
Expected between February 10-15, 2026, just before the Lunar New Year holiday. API access and open-weight release are anticipated in Q1 2026.
How much will GLM-5 cost?
Based on GLM-4.5 pricing (~$0.35 input / $1.55 output per million tokens), expect GLM-5 to be in the $0.20-0.50 range. This is 5-10x cheaper than GPT-5 or Claude 4.5.
What's the context window?
Not officially confirmed, but GLM-4.7 supports 200K tokens with 128K output capacity. GLM-5 will likely match or exceed this.
Will it be open-source?
Zhipu AI has a strong track record of releasing open-weight models under MIT license. GLM-5 is expected to follow this pattern based on the company's public commitment to open sourcing models.
Can I use it with Claude Code or Verdent?
GLM-4.7 already integrates with Claude Code, Kilo Code, Roo Code, and Cline. GLM-5 should work with these same platforms via API compatibility.
What programming languages does it support?
All major languages—JavaScript/TypeScript, Python, Go, Java, Rust, C++. GLM-4.7 showed particularly strong multilingual performance with 66.7% on SWE-bench Multilingual.
Is the Huawei Ascend training a limitation?
Not for end users. The model will be deployable on any hardware via API or self-hosted on standard GPU infrastructure. The Ascend training just proves supply chain independence.
How does it compare to GPT-5 for reasoning?
We won't know until GLM-5 releases, but GLM-4.7 scored 42.8% on HLE (Humanity's Last Exam), which is competitive but below GPT-5.2's 100% accuracy on AIME 2025 mathematics. Expect GLM-5 to close this gap but not fully match GPT-5's reasoning ceiling.
Can I fine-tune it on my own data?
If released as open-weight under MIT license (expected), yes—full fine-tuning rights with no restrictions.
What safety guardrails does it have?
Not yet disclosed. Zhipu AI hasn't published detailed safety documentation comparable to Anthropic's Constitutional AI. Verify safety alignment for your use case before production deployment.
Bottom line
GLM-5 represents a significant milestone—not just for Zhipu AI, but for the broader AI ecosystem. If it delivers on the promise of frontier-level coding and reasoning at 5-10x lower cost while maintaining open-weight accessibility, it'll force every enterprise to reconsider their model strategy.
But here's what I'm actually waiting to verify before recommending it for Verdent's production stack:
- Real SWE-bench Verified score — Does it hit 75%+ or plateau at GLM-4.7's 73.8%?
- Terminal automation reliability — Can it close the gap with Claude 4.5 on multi-step CLI workflows?
- Agentic stability over 20+ turn conversations — Does Preserved Thinking actually prevent context drift?
- Self-hosting economics — Is running it on Ascend hardware cheaper than API access at scale?
The February 10-15 release window is days away. I'll be running these exact tests the moment API access goes live. If you're evaluating GLM-5 for your team, focus on task-level performance in your specific domain, not benchmark scores.
The open-weight release changes everything. Even if GLM-5 doesn't outperform Claude or GPT-5 on every benchmark, the ability to own the model, fine-tune without limits, and deploy without vendor dependencies makes it viable for enterprises that value sovereignty over peak performance.
Watch this space—I'll update with real-world test results once the model drops.
