
Bu karşılaştırma haftalar önce şekillenmeye başlamıştı.
12 Şubat 2026'da — MiniMax'ın Hong Kong IPO'sundan bir ay sonra — M2.5 geldi. Slack'im anında doldu, beş farklı mühendisten aynı mesaj: "Bu sayılara baktın mı?"
Baktırdıran şey şu: MiniMax M2.5, SWE-bench Verified'da %80,2 alıyor. Claude Opus 4.6, bir hafta önce 5 Şubat'ta çıkmıştı — %80,8. Aralarında 0,6 puanlık fark. Bir taraf milyon token başına $0,15, diğer taraf $5,00.
Teoride değil, pratikte: her ikisini de 7 gün boyunca gerçek production senaryolarında çalıştırdım. Aşağıda bulduklarım var — yalnızca benchmark sayıları değil.
Bu Karşılaştırma Gerçekte Ne İçin?
Hangi model "daha iyi" sorusu yanlış soru. Doğru soru şu: stack'inde hangi görevi hangi modele yönlendirmelisin ve ne kadara mal olur?
Bu karşılaştırma akademik değil. Spesifik bir karar problemi üzerine kurulu: AI destekli bir geliştirme iş akışı kuruyorsun veya çalıştırıyorsun, her iki modele erişimin var ve bir yönlendirme stratejisine ihtiyacın var.
Karşılaştırdığımız modeller:
MiniMax M2.5 — 12 Şubat 2026. 230B parametre, forward pass başına yalnızca 10B'ı aktive eden Mixture-of-Experts mimarisi. 200.000+ gerçek dünya RL ortamında eğitildi, Hugging Face'te open-source.
Claude Opus 4.6 — 5 Şubat 2026. Adaptive Thinking, 1M token context penceresi (beta) ve Terminal-Bench 2.0'da sektör lideri performans. Anthropic'in en yetenekli modeli.
Her ikisi de production'a hazır. Her ikisi de gerçekten iyi. Ama birbirinin yerine geçmiyor.
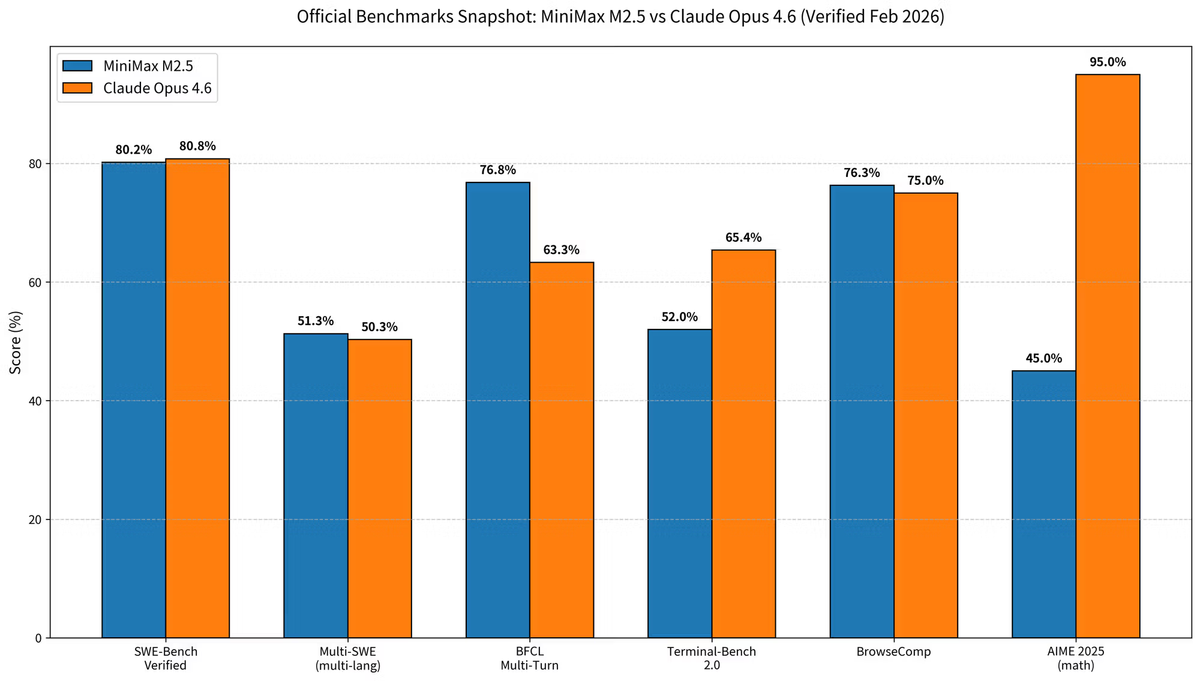
Benchmark Özeti (Şubat 2026 doğrulaması)
Tüm rakamlar resmi model sürümlerinden ve Şubat 2026 itibarıyla doğrulanmış üçüncü taraf değerlendirmelerinden alındı.
| Benchmark | MiniMax M2.5 | Claude Opus 4.6 | Üstün |
|---|---|---|---|
| SWE-bench Verified | %80,20 | %80,80 | Opus 4.6 (+0,6%) |
| Multi-SWE-Bench (çok dilli) | %51,30 | %50,30 | M2.5 (+1%) |
| BFCL Multi-Turn (araç çağrısı) | %76,80 | %63,30 | M2.5 (+13,5%) |
| Terminal-Bench 2.0 | 52% | %65,40 | Opus 4.6 (+13,4%) |
| BrowseComp | %76,30 | ~%75 | Neredeyse beraberlik |
| AIME 2025 (matematik akıl yürütme) | 45% | %95+ | Opus 4.6 (belirgin) |
| HumanEval (Python) | — | 95% | Opus 4.6 |
Kaynaklar: MiniMax resmi duyurusu, Anthropic resmi sayfası, SWE-bench Results Viewer, Artificial Analysis.
SWE-bench'teki %0,6 Fark Production'da Ne Anlama Geliyor?
Başlık narratifini frenlemem gerekiyor. SWE-bench Verified, Python repo'larındaki gerçek GitHub issue'larının otonom çözümünü test ediyor — coding agent'ları için elimizdeki en iyi tek benchmark. Ve evet, %80,2 vs %80,8 istatistiksel olarak yakın.
Ama hangi model hangi görev türünde daha iyi, bu fark devasa. Pratikte gözlemlediğim farklar %0,6'nın ima ettiğinden çok daha büyüktü:
Multi-SWE-Bench, çok dosyalı çok dilli projeleri test ediyor — M2.5 burada önde: %51,3 vs %50,3. Go, Rust, TypeScript ve Java işi için daha alakalı benchmark bu.
BFCL Multi-Turn gerçekten dikkat çeken buydu. M2.5'in uzun süreli çok turlu araç çağrısında 13,5 puanlık üstünlüğü, uzun agentic döngülerde context'i çok daha az kaybettiği anlamına geliyor. 40+ araç çağrısı çalıştıran bir Verdent multi-agent iş akışında bu fark devasa.
Terminal-Bench 2.0 ters hikayeyi anlatıyor. Opus 4.6'nın %65,4 vs M2.5'in %52'si, otonom terminal operasyonlarında, çok adımlı debug'da ve OS seviyesi görevlerde gerçek bir uçurumu yansıtıyor. Agent'ının dosya sisteminde gezinmesi, test suite'lerini iteratif çalıştırması veya shell seviyesinde debug yapması gerekiyorsa Opus 4.6 primini hak ediyor.
Kısacası: SWE-bench'teki %0,6, ikiye ayrılmış bir performans profilini gizliyor. M2.5, araç çağrısı döngülerinde hâkim; Opus 4.6, terminal ve akıl yürütme ağırlıklı görevlerde hâkim.
Görev Bazlı Test Sonuçlarım
7 gün boyunca her iki modeli gerçek görevlerden geçirdim — oyuncak problemler değil, gerçek proje türlerinden temsili çalışmalar: çok servisli bir API refactoring, bir iş mantığı doğrulama suite'i, Rust'ta bazı niche dil çalışması ve bir TypeScript bileşen kütüphanesi migration'ı.
M2.5 Kazandı — Çok Dosyalı Refactoring, Uzun Araç Çağrısı Döngüleri
Görev: 14 dosyalı bir Express.js API'yi callback'ten async/await'e taşıma, tam test suite güncellemeleriyle
M2.5'in native "spec yazma davranışı" — koda dokunmadan önce mimariyi planlaması — burada gerçek fark yarattı. Tek bir satır yazmadan önce dosya bağımlılıklarını, paylaşılan callback pattern'larını ve test etki yüzeyini kapsayan yapılandırılmış bir migration planı üretti. Nihai çıktı, Opus 4.6'nın eşdeğer girişimine kıyasla yaklaşık %20 daha az manuel inceleme gerektirdi.
BFCL multi-turn avantajı araç çağrısı döngüsünde net biçimde göründü. M2.5, 47 ardışık araç çağrısı boyunca doğru context'i korudu. Opus 4.6, çağrı 28 civarında context kayması gösterdi ve tekrar rayına girmesi için manuel bir enjeksiyon gerekti.
# Örnek: Verdent Agent Mode'da M2.5 paralel araç çağrısı pattern'ı
# M2.5 bu üç araç çağrısını context kaybı olmadan paralel başarıyla çalıştırdı:
# 1. src/routes/users.js oku → callback zincirlerini analiz et
# 2. src/middleware/auth.js oku → callback bağımlılıklarını tespit et
# 3. tests/users.test.js oku → test kapsamını callback'lerle eşleştir
# Gereken toplam tur: 6
# Opus 4.6 eşdeğeri: 9 tur (5. turda context kayması)Testimizdeki diğer M2.5 kazanımları:
- Çok dilli refactoring'ler (aynı seansta TypeScript + Go)
- Uzun Verdent Agent seansları (30+ araç çağrısı)
- Karmaşık lifetime'larla Rust trait implementasyonları (çok dilli eğitim avantajı)
- Code review görevlerinin maliyet optimize edilmiş toplu işlemesi
Opus 4.6 Kazandı — Zorlu İş Mantığı, Niche Dil Edge Case'leri
Görev: 6 yargı bölgesinde düzenleyici uyumluluk kurallarıyla çok para birimli yuvarlama motoru implementasyonu
Tam olarak Opus 4.6'nın akıl yürütme ve planlama hassasiyetindeki farkın ortaya çıktığı görev türü bu. İş mantığı, farklı yargı bölgelerinin birbiriyle çeliştiği üç yerde belirsizdi. Opus 4.6, ilerlemeden önce üç çakışmanın tamamını proaktif olarak işaretleyip açıklama talep etti. M2.5 ikisinde varsayım yaptı — biri doğruydu, biri değildi.
Düzenleyici mantığa, finansal hesaplamalara ya da derin alan akıl yürütmesine dokunan görevler için Opus 4.6'nın Adaptive Thinking ve yüksek AIME skorları gerçek production değeri temsil ediyor.
Testimizdeki diğer Opus 4.6 kazanımları:
- Shell seviyesi operasyonlar gerektiren otonom debug seansları (Terminal-Bench farkı gerçek)
- Python'un typing modülü, C++ template metaprogramming'deki belirsiz dil edge case'leri
- Tam tutarlılıkla 200K+ token context gerektiren görevler
- İlk prensiplerden akıl yürütmenin önemli olduğu yeni mimari tasarım
Maliyet Gerçeği — Aylık Fatura Gerçekte Nasıl Görünüyor?
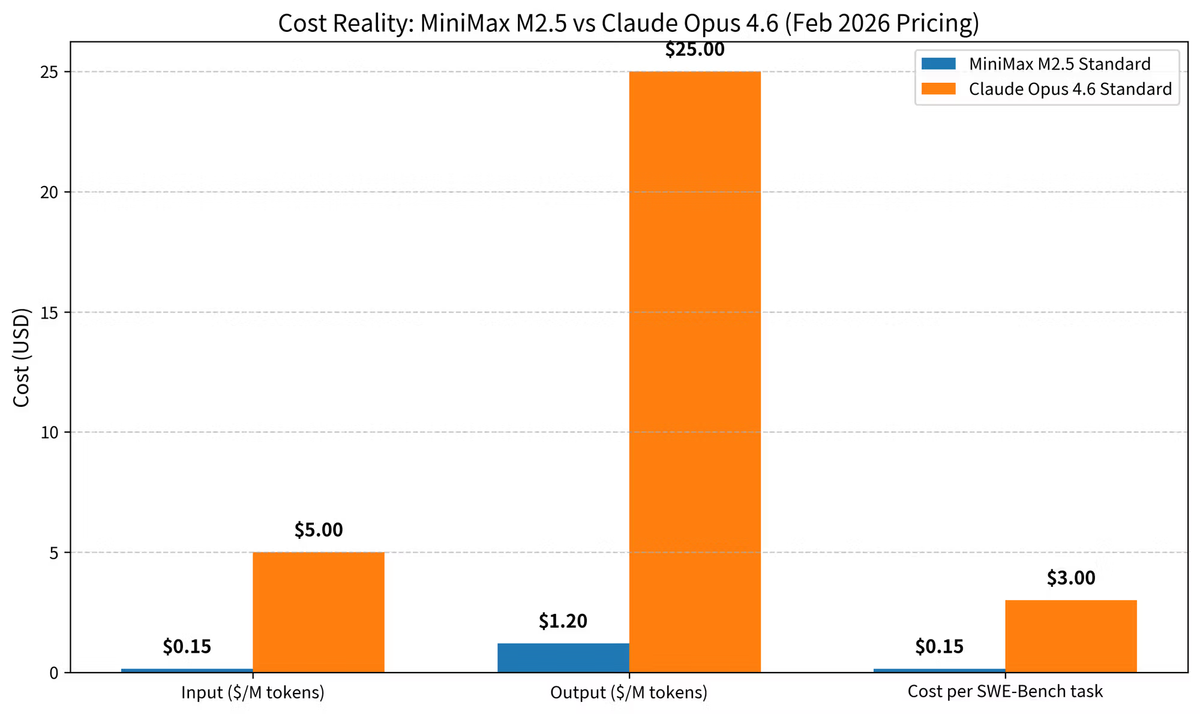
Rakamlar hakkında doğrudan konuşayım, çünkü karar genellikle burada bitiyor.
| MiniMax M2.5 Standard | MiniMax M2.5 Lightning | Claude Opus 4.6 Standard | |
|---|---|---|---|
| Giriş (1M token başına) | $0,15 | $0,30 | $5,00 |
| Çıkış (1M token başına) | $1,20 | $2,40 | $25,00 |
| Hız | 50 TPS | 100 TPS | ~40 TPS (tahmini) |
| SWE-bench görevi başına maliyet (ort.) | ~$0,15 | ~$0,30 | ~$3,00 |
Fiyatlandırma: MiniMax resmi duyurusu ve Anthropic'in API fiyatlandırma sayfası, Şubat 2026.
Ölçekte coding agent'ları çalıştıran ekipler için önemli olan matematik şu:
Senaryo: Günde 100 code review görevi, toplam ~1M output token
- M2.5 Standard: ~$1,20/gün → $36/ay
- Opus 4.6 Standard: ~$25,00/gün → $750/ay
Output token'larında 20 kat maliyet farkı. Günlük agent çalıştıran orta ölçekli bir mühendislik ekibi için görevlerin %70'ini bile M2.5'e yönlendirmek, çoğu görev türünde neredeyse eşdeğer çıktı kalitesiyle anlamlı tasarruf üretiyor.
Opus 4.6'nın bilmekte fayda olan iki maliyet kolu: Batch API %50 indirim sunuyor, prompt caching ise input'u milyon token başına $0,50'ye düşürüyor (%90 tasarruf). Tekrarlanan sistem prompt'ları veya belge ağırlıklı iş akışları çalıştırıyorsan her ikisini de uygula. Ama caching ile bile M2.5, output ağırlıklı agentic iş yüklerinde anlamlı ölçüde daha ucuz kalıyor.
Karar Matrisi ve Verdent'in Production'da Nasıl Yönlendirdiği
Bir haftalık gerçek dünya testinin ardından gerçekten implement edeceğim yönlendirme çerçevesi şu. Verdent'te modeller arasında görev türüne, risk seviyesine ve maliyet toleransına göre yönlendiriyoruz — tek bir "en iyi model" varsayımıyla değil.
| Görev Türü | Önerilen Model | Neden |
|---|---|---|
| Çok dosyalı refactoring (3+ dosya) | M2.5 | Spec yazma davranışı, Multi-SWE-Bench üstünlüğü, düşük maliyet |
| Uzun agentic döngüler (25+ araç çağrısı) | M2.5 | BFCL multi-turn üstünlüğü (%76,8 vs %63,3) |
| Çok dilli projeler (Go/Rust/Java) | M2.5 | 10+ dilde eğitildi, Multi-SWE-Bench #1 |
| Yüksek hacimli toplu code review | M2.5 | Maliyet verimliliği; 20 kat ucuz output |
| Otonom terminal/shell görevleri | Opus 4.6 | Terminal-Bench 2.0: %65,4 vs %52 |
| Karmaşık iş mantığı / uyumluluk | Opus 4.6 | Akıl yürütme derinliği, Adaptive Thinking |
| 200K+ context gerektiren büyük codebase | Opus 4.6 | 1M token penceresi + tutarlılık |
| Yeni mimari tasarım | Opus 4.6 | İlk prensip akıl yürütme avantajı |
| Hızlı Python scripting / prototip | Her ikisi | HumanEval'de performans paritesi |
| Yüksek riskli, düşük hacimli production kodu | Opus 4.6 | Akıl yürütme farkı için primin değeri var |
Yönlendirme mantığı düz Türkçeyle:
M2.5'i iteratif, araç ağırlıklı, çok dosyalı kodlama çalışması için varsayılan agent modeliniz yap. Görev derin akıl yürütme gerektirdiğinde, otonom terminal navigasyonu içerdiğinde veya bir hatanın önemli downstream sonuçları olduğunda Opus 4.6'ya yönlendir.
Bu kalıcı bir hiyerarşi değil — maliyet-risk takası. SWE-bench'teki %0,6 fark hangi modelin "daha iyi" olduğunu tanımlamıyor. Her ikisinin de yeterince yakın olduğunu söylüyor; yani yönlendirmeyi model prestiji değil, görev türü ve maliyet yönlendirmeli.
Verdent'in implementasyonuna kısa bir not: Verdent'in multi-agent mimarisinde Plan Mode agent'ı görev sınıflandırmasına göre yönlendirmeye karar veriyor. Git Worktree izolasyonu, her agent'ın — M2.5 veya Opus 4.6 çalıştırıyor olsun — sandbox'lı bir ortamda çalışması anlamına geliyor; yani yönlendirme kararları kod çakışması yaratmıyor. Benzer bir şey implement ediyorsan, model seçiminden daha önemli olan izolasyon katmanı.
Sık Sorulan Sorular
MiniMax M2.5 gerçekten open-source mu?
Evet — MiniMax ağırlıkları herkese açık yayımladı. MiniMax M2.5 model kartı ve ağırlıkları Hugging Face'te self-hosting için vLLM ve SGLang desteğiyle mevcut. 230B toplam parametre ile self-hosting ciddi donanım gerektiriyor — MoE'nin 10B aktif parametre ayak izine rağmen.
Sıfırdan bir proje için hangi modeli kullanmalıyım?
0-to-1 sistem tasarımı için Opus 4.6'ya yönelirdim. Akıl yürütme derinliği ve Adaptive Thinking, mimari henüz tanımlanmamışken üstünlük sağlıyor. Tanımlı bir codebase ile 1-to-N özellik geliştirmeye geçince M2.5 rekabetçi hale geliyor, hatta daha iyi.
BFCL multi-turn farkı benim için önemli mi?
Seansta ~20'den fazla ardışık araç çağrısı çalıştırıyorsan önemli. Bu eşiğin altında her iki model de context'i iyi tutuyor. Üzerinde — özellikle çok dosyaya yayılan refactoring'lerde — M2.5'in Berkeley Function Calling Leaderboard multi-turn benchmark'ında %76,8 vs %63,3'ü daha az context kayması hatasına dönüşüyor.
Alternatif olarak Claude Sonnet 4.6 ne olacak?
Değinmek gerek. Sonnet 4.6, SWE-bench Verified'da %79,6 alıyor — milyon token başına $3/$15. M2.5'in fiyatına daha yakın ve neredeyse Opus 4.6'nın benchmark skoru. Anthropic-native stack'ler için Sonnet 4.6 pragmatik orta yol.
M2.5'in %37 daha hızlı görev tamamlaması maliyeti gerçekte nasıl etkiliyor?
M2.5 aynı zamanda görev başına hafif daha az token tüketiyor (SWE-bench'te ortalama 3,52M vs M2.1'in 3,72M'i), yani maliyet avantajı birleşiyor — token başına daha az ödüyorsun ve görev başına daha az token kullanıyorsun. Sürekli operasyonda MiniMax, M2.5 Lightning'i 100 TPS'de saatte $1 olarak fiyatlandırıyor. Model fiyatlandırmasını düşünmenin alışılmadık bir yolu, ama uzun süren agent seansları için kullanışlı.
Net konuşmak gerekirse: model tartışmasını bırak, görev yönlendirmesini yap.
MiniMax M2.5 vs Claude Opus 4.6 kararı ikili değil. Bir yönlendirme problemi: M2.5 ölçekte iteratif, çok dosyalı, araç ağırlıklı çalışma için; Opus 4.6 ise maliyetin anlamlı hassasiyet satın aldığı akıl yürütme yoğun, terminal ağırlıklı veya yüksek riskli görevler için.
Kodlama görevlerini görev türüne, risk seviyesine ve maliyete göre yönlendirmek için yukarıdaki karar matrisini kullan. Verdent tarzı multi-agent stack çalıştırıyorsan yönlendirmeyi plan katmanında implement et — bireysel agent'lar herkese uyan tek bir model varsayımı devralmayacak. Bu tek mimari karar, herhangi bir model seçiminden çok daha fazlasını ekibinin çıktı kalitesi ve altyapı maliyetleri için yapacak.
Verdent'i dene — kredi kartı gerekmeden 100 ücretsiz kredi. Claude Sonnet 4.6, Opus 4.6, MiniMax M2.7, GPT-5.4, GLM-5 ve diğerleri üzerinde çalışıyor; gerçek iş yükleriyle model routing'i plan katmanından test edebilirsin. Ücretsiz başla →
İyi kodlamalar.
