
Here's something that genuinely surprised me when I first ran M2.5 through a real agentic pipeline: it didn't drop the context. That sounds like a low bar — and it is — but it's the bar that most models quietly fail at after 20+ sequential tool calls in a complex refactor session.
I've been building MiniMax M2.5 agentic coding workflows for the past two weeks, covering multi-file refactors, chained tool-calling loops, and CI-gated patch validation. This guide covers the three workflows that are now running in production, the exact prompt skeletons and GitHub Actions config I use, and the three failure modes that hit us before we got the guardrails right. No fluff — just the patterns that actually held up.
Why M2.5 Is Genuinely Good at Agentic Work
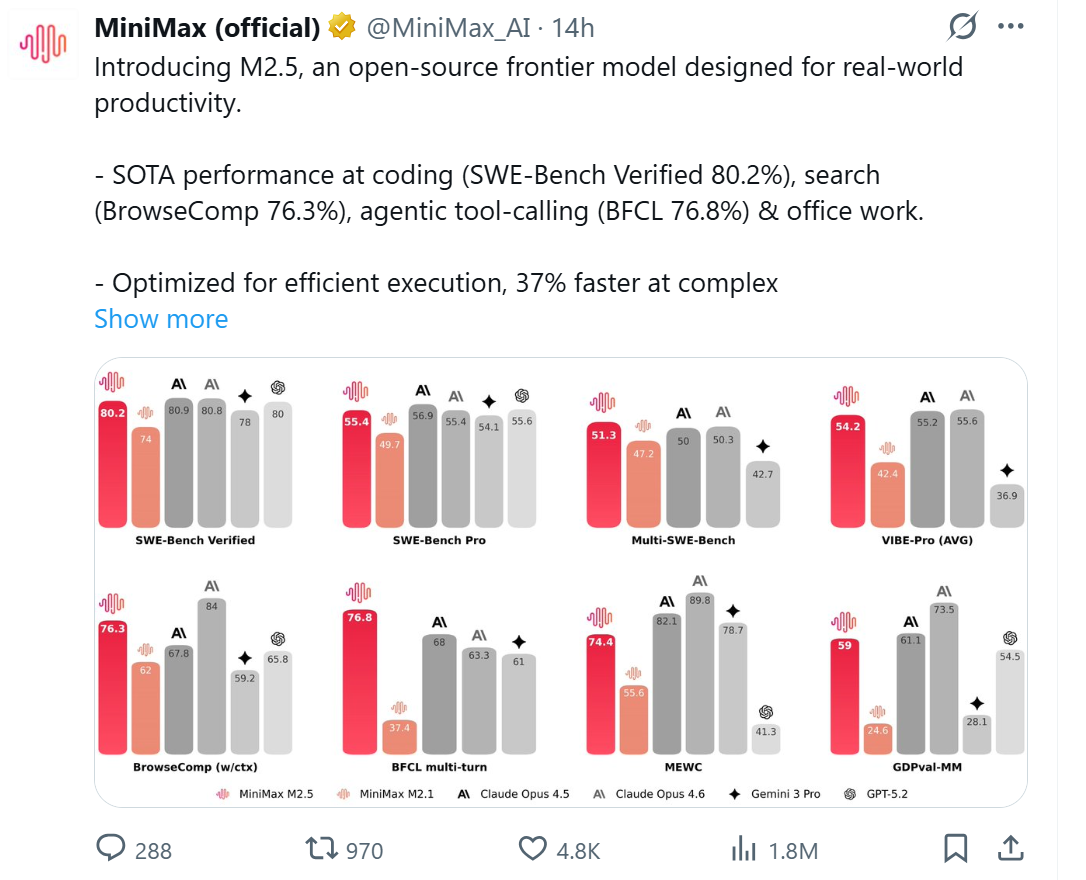
Let me lead with the number that matters most for agentic use: in the BFCL Multi-Turn benchmark, MiniMax M2.5 scored 76.8%, while Claude Opus 4.6 lagged behind at 63.3% — a 13.5% difference that has a huge impact on AI agent programming scenarios.
The Berkeley Function Calling Leaderboard multi-turn benchmark tests exactly what breaks in production agentic pipelines: can the model maintain accurate intent across multiple sequential tool calls without drifting, losing parameters, or requiring a re-prompt? A 13.5 percentage point lead on that benchmark doesn't mean M2.5 is 13.5% "better" — it means it fails meaningfully less often in the situations that cost you the most: long loops where every dropped context event means a wasted retry and wasted tokens.
Two reasons this lead holds up in practice. First, M2.5's real-environment RL training translates directly into better function orchestration — the model was trained inside 200,000+ actual code repositories and tool environments, not just on synthetic preference data. Second, compared to the previous generation M2.1, M2.5 reduces the number of tool-calling rounds needed to complete agent tasks by about 20%. Fewer rounds means lower latency, lower token spend, and simpler orchestration code on your side.
One quick note on what MiniMax calls Architect Mode (or the "Architect Mindset" in their official framing): the model genuinely outlines structure and feature design before touching implementation — and it's not marketing fluff. In agentic multi-file work, this planning-before-patching behavior is a material advantage over models that dive directly into edits. It surfaces conflicts between files before you're three tool calls into a dead-end patch.
Workflow 1 — Multi-File Refactor
Multi-file refactors are where M2.5's 51.3% Multi-SWE-Bench score (first place globally as of February 2026) becomes tangible. Here's the exact pattern we use for a production-grade multi-file refactor run through Verdent's multi-agent architecture.
Context Packaging — Repo Tree + Hotspot Files + Explicit Constraints
The single biggest lever for multi-file refactor quality isn't the model — it's how you package the context. M2.5's Architect Mode needs enough structural information to plan before it edits. Feed it too little and it makes assumptions; feed it too much and you blow your context budget on irrelevant files.
The pattern that works: repo tree + hotspot files + explicit constraints, in that order.
python
import anthropic
import subprocess
def build_refactor_context(root_dir: str, hotspot_files: list[str],
max_file_tokens: int = 8000) -> str:
"""
Package context for a multi-file refactor:
1. Lightweight repo tree (structure, not content)
2. Full content of hotspot files only
3. Explicit constraints the agent must follow
"""
# 1. Repo tree — lightweight, structure only
tree = subprocess.run(
["git", "ls-files", "--others", "--exclude-standard", "-c"],
cwd=root_dir, capture_output=True, text=True
).stdout
# Filter to relevant extensions only
relevant = [f for f in tree.strip().split("\n")
if f.endswith((".py", ".ts", ".go", ".rs", ".java"))]
tree_summary = "\n".join(relevant[:80]) # cap at 80 files
# 2. Hotspot file contents
file_contents = []
for path in hotspot_files:
with open(f"{root_dir}/{path}") as f:
content = f.read()
tokens_est = len(content) // 4 # rough token estimate
if tokens_est > max_file_tokens:
content = content[:max_file_tokens * 4] + "\n... [truncated]"
file_contents.append(f"### File: {path}\n```\n{content}\n```")
# 3. Constraints block
constraints = """
CONSTRAINTS — follow exactly:
- Only modify files listed in HOTSPOT FILES
- Output diffs in unified diff format (diff -u style)
- Do not rename functions or classes — only refactor internals
- Preserve all existing test interfaces
- Flag any cross-file dependency that requires coordinated changes
"""
return f"REPO STRUCTURE:\n{tree_summary}\n\nHOTSPOT FILES:\n" + \
"\n\n".join(file_contents) + f"\n\n{constraints}"Exact Prompt Skeleton (Plan → Diff → Verify)
This three-phase skeleton is what triggers M2.5's Architect Mode planning behavior reliably:
python
SYSTEM_PROMPT = """You are a senior software engineer performing a targeted refactor.
You operate in three strict phases:
1. PLAN: Describe what needs to change and why, file by file. No code yet.
2. DIFF: Output the minimal unified diff for each file change.
3. VERIFY: List what you'd check in a code review of your own output.
Do not skip phases. Label each phase clearly."""
def run_refactor_agent(context: str, refactor_goal: str) -> str:
client = anthropic.Anthropic()
response = client.messages.create(
model="MiniMax-M2.5",
max_tokens=4096,
system=SYSTEM_PROMPT,
messages=[{
"role": "user",
"content": f"{context}\n\nREFACTOR GOAL:\n{refactor_goal}"
}]
)
return response.content[0].textOne Realistic Diff Output Snippet (Minimal Patch Style)
M2.5's PLAN output for a callback-to-async migration of a single module looked like this in our test:
PLAN:
- src/db/connection.py: Replace 3 callback-style query functions with async/await.
Dependencies: src/api/users.py imports query_user() and query_session() from this module.
Coordinated change required: callers in users.py must also be updated to await.
- src/api/users.py: Update 2 call sites for query_user() and query_session() to use await.
No interface changes — external signatures unchanged.
- Cross-file risk: if session_middleware.py also imports from connection.py, it will break.
Flagging for manual check — not in hotspot list.Then the DIFF phase output:
diff
--- a/src/db/connection.py
+++ b/src/db/connection.py
@@ -12,8 +12,8 @@ import psycopg2
-def query_user(user_id: str, callback):
- conn = get_connection()
- result = conn.execute("SELECT * FROM users WHERE id = %s", (user_id,))
- callback(result.fetchone())
+async def query_user(user_id: str) -> dict | None:
+ async with get_async_connection() as conn:
+ result = await conn.execute("SELECT * FROM users WHERE id = %s", (user_id,))
+ return await result.fetchone()The proactive flag about session_middleware.py — a file we hadn't included — saved us from a broken import that would have surfaced only at runtime.
Workflow 2 — Chained Tool Calls + CI Gate

Tool Chain Setup — Search → Execute → Write
The tool chain pattern we use for automated bug remediation follows three steps: search the codebase to locate the problem, execute a test to confirm it exists, write the patch. Each step uses a separate tool.
python
import anthropic
import subprocess
import json
client = anthropic.Anthropic()
# Define the tool chain
TOOLS = [
{
"name": "search_codebase",
"description": "Search the repository for files or patterns. Returns matching file paths and line numbers.",
"input_schema": {
"type": "object",
"properties": {
"pattern": {"type": "string", "description": "Grep pattern to search for"},
"file_glob": {"type": "string", "description": "File glob to limit search, e.g. '*.py'"}
},
"required": ["pattern"]
}
},
{
"name": "run_tests",
"description": "Run the project test suite for a specific file or test name. Returns exit code and output.",
"input_schema": {
"type": "object",
"properties": {
"target": {"type": "string", "description": "Test file path or test function name"},
"timeout_seconds": {"type": "integer", "default": 60}
},
"required": ["target"]
}
},
{
"name": "write_patch",
"description": "Apply a unified diff patch to the repository. Returns success/failure.",
"input_schema": {
"type": "object",
"properties": {
"target_file": {"type": "string", "description": "File path to patch"},
"patch_content": {"type": "string", "description": "Unified diff content to apply"},
"branch": {"type": "string", "description": "Git branch to write to — must not be 'main'"}
},
"required": ["target_file", "patch_content", "branch"]
}
}
]Permission scoping to avoid over-granting tools: The write_patch tool enforces a branch constraint at the tool definition level. The agent is not permitted to call write_patch with branch: "main" — the tool handler rejects it. This is not optional safety theater; it's the guard that stops a runaway agent from pushing directly to your default branch.
python
def handle_tool_call(tool_name: str, tool_input: dict) -> str:
"""Tool executor with permission scoping."""
if tool_name == "search_codebase":
result = subprocess.run(
["grep", "-rn", tool_input["pattern"],
"--include", tool_input.get("file_glob", "*")],
capture_output=True, text=True, cwd="./repo"
)
return result.stdout[:4000] # cap output
elif tool_name == "run_tests":
result = subprocess.run(
["pytest", tool_input["target"], "-v", "--tb=short"],
capture_output=True, text=True, timeout=tool_input.get("timeout_seconds", 60)
)
return f"Exit code: {result.returncode}\n{result.stdout[-2000:]}"
elif tool_name == "write_patch":
# PERMISSION SCOPE: block writes to protected branches
protected = {"main", "master", "develop", "release"}
if tool_input.get("branch") in protected:
return "ERROR: write_patch cannot target protected branches. Use a feature branch."
# Apply the patch
result = subprocess.run(
["git", "apply", "--check"],
input=tool_input["patch_content"], capture_output=True, text=True
)
if result.returncode != 0:
return f"Patch validation failed: {result.stderr}"
subprocess.run(["git", "apply"], input=tool_input["patch_content"])
return f"Patch applied to {tool_input['target_file']} on branch {tool_input['branch']}"
return f"Unknown tool: {tool_name}"One guardrail to stop runaway loops — step budget + tool whitelist:
python
MAX_TOOL_STEPS = 15 # Hard ceiling on tool calls per agent session
def run_agent_with_budget(task: str, tools: list, max_steps: int = MAX_TOOL_STEPS):
messages = [{"role": "user", "content": task}]
steps_used = 0
while steps_used < max_steps:
response = client.messages.create(
model="MiniMax-M2.5",
max_tokens=2048,
tools=tools,
messages=messages
)
# Append full response to maintain reasoning chain
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason == "end_turn":
return response # Agent finished cleanly
if response.stop_reason == "tool_use":
tool_results = []
for block in response.content:
if block.type == "tool_use":
steps_used += 1
if steps_used >= max_steps:
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": "BUDGET EXCEEDED: Agent step limit reached. Summarize progress and stop."
})
break
result = handle_tool_call(block.name, block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result
})
messages.append({"role": "user", "content": tool_results})
raise RuntimeError(f"Agent exceeded {max_steps} tool steps without completing")CI Integration (GitHub Actions)
Once the agent writes a patch to a feature branch, the CI gate takes over. This GitHub Actions workflow triggers on PR open, runs the agent-generated patch through the test suite, and blocks merge on failure.
yaml
# .github/workflows/ai-patch-validation.yml
name: AI Patch Validation
on:
pull_request:
types: [opened, synchronize]
branches: [main]
jobs:
validate-ai-patch:
runs-on: ubuntu-latest
# Only run on PRs from the AI agent branch prefix
if: startsWith(github.head_ref, 'agent/')
steps:
- name: Checkout PR branch
uses: actions/checkout@v4
with:
ref: ${{ github.head_ref }}
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.12'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run full test suite
id: tests
run: |
pytest tests/ -v --tb=short --json-report --json-report-file=results.json
echo "exit_code=$?" >> $GITHUB_OUTPUT
- name: Post test summary as PR comment
uses: actions/github-script@v7
with:
script: |
const fs = require('fs');
const results = JSON.parse(fs.readFileSync('results.json', 'utf8'));
const summary = `## AI Patch Validation Results
- **Passed:** ${results.summary.passed}
- **Failed:** ${results.summary.failed}
- **Duration:** ${results.duration.toFixed(2)}s
${results.summary.failed > 0 ? '❌ Merge blocked — fix failing tests first.' : '✅ All tests pass — ready to merge.'}`;
github.rest.issues.createComment({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: summary
});
- name: Gate merge on test pass
if: steps.tests.outputs.exit_code != '0'
run: exit 1The startsWith(github.head_ref, 'agent/') condition means this job only runs on PRs from agent-created branches — it won't fire on human developer PRs unless they use that prefix. This keeps your CI costs clean.
Failure Modes We Hit — and What We Did
Three real failure modes from our first two weeks. All three are fixable with pattern changes, not model changes.
Wrong Branch Push → Fix: Enforced Branch Targeting + PR-Only Writes
What happened: On day three, an agent using an earlier version of our tool handler successfully called write_patch and pushed directly to develop. The branch guard was checking string equality to "main" only — I'd forgotten develop was also protected.
The impact: No code was lost (Git is a safety net), but the PR review workflow was bypassed. The pushed changes went live to our staging environment before anyone had reviewed the agent's output.
The fix: Two-layer enforcement. First, expand the protected branch set in the tool handler (as shown above). Second, configure the tool to only create branches matching a specific naming pattern, and enforce PR creation as the only write pathway to protected branches:
python
AGENT_BRANCH_PREFIX = "agent/"
def validate_branch_name(branch: str) -> bool:
"""Agent branches must use the 'agent/' prefix and cannot be protected."""
protected = {"main", "master", "develop", "staging", "release"}
if branch in protected:
return False
if not branch.startswith(AGENT_BRANCH_PREFIX):
return False # Must use prefix for CI routing
return TrueAfter this change: every agent write targets agent/<task-id>/<timestamp>, the GitHub Actions workflow fires on PR open, and no agent output ever reaches a protected branch without passing tests first.
Lost Output Format Tags → Fix: Strict Output Schema + Validation Step
What happened: M2.5 reliably outputs the PLAN/DIFF/VERIFY structure when the system prompt is tight — but in three sessions, it merged the DIFF and VERIFY phases into a single block when the task was unusually complex. Our downstream parser expected ### DIFF as a section header and broke silently when it was missing.
The impact: The parser returned an empty diff. The CI pipeline treated "no diff" as "no changes needed" and closed the PR without applying the patch. We didn't notice for two hours.
The fix: Add an explicit schema validation step between the agent response and the patch application:
python
import re
def parse_and_validate_agent_output(raw_output: str) -> dict:
"""
Extract PLAN, DIFF, VERIFY sections from agent output.
Raises ValueError with actionable message if structure is missing.
"""
sections = {}
for section in ["PLAN", "DIFF", "VERIFY"]:
# Flexible pattern: allows markdown headers or plain labels
pattern = rf"(?:#{1,3}\s*)?{section}:?\s*\n(.*?)(?=(?:#{1,3}\s*)?(?:PLAN|DIFF|VERIFY)|$)"
match = re.search(pattern, raw_output, re.DOTALL | re.IGNORECASE)
if not match:
raise ValueError(
f"Agent output missing '{section}' section. "
f"Re-prompt with explicit phase labels required.\n"
f"Output preview: {raw_output[:300]}"
)
sections[section] = match.group(1).strip()
# Extract unified diffs from the DIFF section
diff_pattern = r"```diff\n(.*?)```"
diffs = re.findall(diff_pattern, sections["DIFF"], re.DOTALL)
if not diffs:
raise ValueError(
"DIFF section found but contains no fenced diff blocks. "
"Check that the agent is outputting `diff` code blocks."
)
sections["diffs"] = diffs
return sectionsAfter adding this validation, a missing section triggers a re-prompt with the specific missing field called out, rather than a silent no-op.
Context Overflow in Long Repos → Fix: File Sharding + Hotspot-First Context Selection
What happened: We tried running the refactor agent on a service with 340 Python files. Even sending only the repo tree (file list, no content) plus five hotspot files pushed us over 60,000 input tokens. When we added a sixth file, context drift began affecting the PLAN output quality — the agent started confusing file paths.
The impact: The generated diff referenced a function in src/utils/cache.py that didn't exist. The real function was in src/core/cache_manager.py. A plausible hallucination caused by context pressure.
The fix: File sharding with hotspot-first context selection. Instead of sending all context in one call, we pre-rank files by relevance to the refactor goal and send them in priority order, staying under a per-call budget:
python
def rank_files_by_relevance(repo_root: str, refactor_goal: str,
target_files: list[str]) -> list[tuple[str, int]]:
"""
Rank candidate files by keyword overlap with the refactor goal.
Returns list of (file_path, relevance_score) sorted descending.
"""
keywords = set(refactor_goal.lower().split())
ranked = []
for path in target_files:
try:
with open(f"{repo_root}/{path}") as f:
content = f.read().lower()
score = sum(content.count(kw) for kw in keywords)
ranked.append((path, score))
except (IOError, UnicodeDecodeError):
continue
return sorted(ranked, key=lambda x: x[1], reverse=True)
def build_sharded_context(repo_root: str, refactor_goal: str,
all_files: list[str],
token_budget: int = 40_000) -> list[str]:
"""
Build context shards that each stay under the token budget.
Returns list of context strings for sequential agent calls.
"""
ranked = rank_files_by_relevance(repo_root, refactor_goal, all_files)
shards = []
current_shard_files = []
current_token_estimate = 0
for path, score in ranked:
with open(f"{repo_root}/{path}") as f:
content = f.read()
file_tokens = len(content) // 4
if current_token_estimate + file_tokens > token_budget:
if current_shard_files:
shards.append(current_shard_files)
current_shard_files = [path]
current_token_estimate = file_tokens
else:
current_shard_files.append(path)
current_token_estimate += file_tokens
if current_shard_files:
shards.append(current_shard_files)
return shardsWith sharding, the agent handles the highest-relevance files first and produces a PLAN that's accurate to the files it can actually see. For large repos, we run the agent in two passes: hotspot shard first (PLAN + DIFF), then a second call with the secondary shard to catch any cross-file dependencies flagged in the first PLAN.
What Holds Up in Production
After two weeks of real agentic use, the pattern that holds up is straightforward: M2.5 is reliable in tool-calling loops when you give it explicit structure. The BFCL lead isn't theoretical — you feel it in the reduced re-prompt rate on long sessions. The Architect Mode planning behavior genuinely surfaces dependency conflicts before they become broken patches.
The three failure modes above are all solvable with engineering, not model tuning. Branch targeting is a permissions problem. Output format drift is a validation problem. Context overflow is a retrieval problem. None of them require swapping the model.
For teams building agentic coding pipelines, the full stack we're running — M2.5 + Verdent multi-agent architecture + Git Worktree isolation + CI gate — is covered in the MiniMax M2.5 API setup guide. If you're evaluating the cost side before committing to the workflow, the M2.5 pricing breakdown has the monthly bill math.
Data sources: MiniMax M2.5 official announcement (Feb 12, 2026), Berkeley Function Calling Leaderboard data (Feb 2026), Hugging Face M2.5 architecture analysis by Maxime Labonne (Feb 2026), SWE-bench Results Viewer (Feb 17, 2026), direct API testing and production workflow logs (Feb 15–22, 2026).
