


Achieving 76.1% pass@1 score on SWE-bench Verified, we are excited to bring Verdent to the world, as one of the state-of-the-art coding agent products.
SWE-bench Verified stands as one of the most credible benchmarks, distinguishing agents that truly solve software-engineering issues from those that handle only trivial tasks. Verdent is evaluated as is, without leaderboard tuning or output curation (i.e., generating multiple candidates and then selecting the most promising one), using the same production-grade agent that our users can directly access.
![Figure 1. Pass@1 and pass@3 resolved rates on SWE-bench Verified of Verdent, along with other agents. Some pass@1 scores for comparison are from official submissions [##https://github.com/SWE-bench/experiments/tree/main/evaluation/verified/20250610_augment_agent_v1#augment##1##, ##https://github.com/SWE-bench/experiments/tree/main/evaluation/verified/20250928_trae_doubao_seed_code#1-single-attempt-pass-rate-706##2##].](/blogs/images/2-1.svg)
What is Verdent?
Verdent is a developer-centric coding agent that orchestrates advanced models and subagents in a unified flow of tasks. With orchestration of parallel agents supported by top-tier models, Verdent excels in the "plan-code-verify" loop. Verdent offers smooth integration into traditional coding workflows (i.e., via a Visual Studio Code extension), and also provides an application that enables users to solve multiple tasks in parallel.
Experimental Insights
Performance Measurement
The resolved rate is used as the primary performance metric on SWE-bench Verified, and we report both pass@1 (resolved rate within a single attempt) and pass@3 (resolved rate within up to three attempts). All evaluations are conducted using the exact same production-grade agent. Consequently, the reported metrics directly reflect Verdent's real-world performance, rather than results from a research-only or leaderboard-tuned setup.
In vibe coding, developers and agents frequently experiment through trials and rollbacks in isolated worktrees, where iterations occur safely without affecting the main branch. To reflect this realistic development cycle, we include pass@3 in our evaluation, defined as the resolved rate within up to three consecutive attempts on the same issue. If the agent fixes the issue in any of those attempts, the instance is then counted as resolved.
Variations from Model Provider
Throughout development, we evaluated multiple model providers' API to power our Verdent agent, using the same prompt, toolset, and evaluation harness. We observe that some providers deliver relatively stable behavior across runs, whereas others (e.g., AWS Bedrock) exhibit noticeably higher variance. Under identical conditions, the gap in resolved rate across providers reaches up to 1.2% upon SWE-bench Verified.
Verdent puts user experience first by choosing providers that deliver both top performance and steady reliability. We are continuously monitoring model behavior on real workloads, so that our users always get dependable, high-performing models--without regressions or surprise downgrades.

Figure 2. Performance variation of Claude Sonnet 4.5 across different model providers. All evaluations use the Claude Code agent framework. Models are evaluated without thinking. Pass@1 and Pass@3 resolved rates are reported.
Thinking Matters
Thinking matters a lot, either in benchmarks like SWE-bench Verified or in real workloads. Software engineers usually look before they leap, and so should coding agents be. In early experiments, we examined how the thinking budget (i.e., the number of reasoning tokens an agent may spend) affects performance. Agents, including Verdent and Claude Code, are tested with varying thinking budgets.
Results indicate that increasing the thinking budget yields an improvement of about 0.7% at the resolved rate over the full set of SWE-bench Verified. Additional testing on subsets (randomly sampled 100-problem slices) further confirms this finding. In short, giving an agent more room to reason translates into measurable gains.
Table 1. Performance gains from enabling thinking mode. Evaluated on subsets of SWE-bench Verified.
| Verdent + Claude sonnet 4.5 | Claude Code + Claude sonnet 4.5 | ||
|---|---|---|---|
| Pass@1 | w/o Thinking | 80% | 76% |
| w/ Thinking | 82% | 78% | |
| Pass@3 | w/o Thinking | 86% | 85% |
| w/ Thinking | 88% | 86% |
Tool-Set Simplification
Real-world development runs on series of tools. Our internal tests and early user feedback show that agents need thoughtfully designed tools. Equipped with an appropriate tool-set, Verdent meaningfully improves usability, trust, and developing flow. However, we find that SWE-bench Verified is not particularly sensitive to intricate, highly engineered tool-sets or agent designs, which means powerful tools or sophisticated orchestrations do not always yield higher benchmark scores.
To test this, we conduct an ablation, where agent design is simplified and the advanced tools are eliminated. Specifically, Verdent (with Claude Sonnet 4.5) equipping only basic bash, read, write, and edit tools are evaluated. The outcome is surprising, as the performance on SWE-bench Verified changes little. It reveals a potential bias of current benchmarks, as the minimal tool-set, which suffices for SWE-bench Verified, clearly goes against the logic of software engineering.
Code Review Subagent
In AI-driven development, generation volume is not the ultimate goal; instead, production-ready delivery is. Verdent adds multiple quality gates, notably a code review subagent. In our SWE-bench Verified tests, turning on the review subagent lifts pass@3 by about 0.5%. In real projects, it also lets users further shape code style and quality. Verdent's philosophy is simple: automatically generated code should be explainable, reviewable, and ready to ship.
How Does Verdent get 76.1% on SWE-bench Verified?
Multi-model Orchestration
Top-tier models such as the Claude series and the GPT series are increasingly diverging in specialization: GPT excels at project navigation, review, and refactoring, while Claude shines in coding and debugging. Verdent operates seamlessly across them all, rather than tailoring coding agents to a specific model and restricting user flexibility.
Verdent keeps its core logic (the "plan-code-verify" loop) intact, regardless of which single model or model orchestration is in use. By matching the right model to each stage and subagent, Verdent further ensures reliable results and consistently high-quality software. We evaluate several top-tier models on SWE-bench Verified using the same Verdent runtime.

Figure 3. Pass@1 of Verdent on top-tier models (Claude Sonnet 4.5 and GPT-5), compared with other top coding agents.
These models are already accessible to users within Verdent, allowing instant switching with a single click. Verdent provides transparent and configurable model selection, empowering users with full control over their development process.
Figure 4. Model accessibility in Verdent.
Long Context & Persistent Memory
An explicit and structured to-do list is maintained in Verdent during task execution. Verdent reads and updates this to-do list throughout the entire task-solving process. This helps Verdent track progress on the specific task and stay focused on the current state.
Developers often keep a to-do list (either mentally or on paper) to track their workflow. When tackling an issue, they might break it down into clear steps: reproducing the bug, pinpointing the error, updating the codebase, rerunning the tests, and submitting the pull request. Each completed step is crossed off, and if a new issue appears, additional steps are quickly added to the list. This systematic procedure helps developers stay oriented when tackling complex problems.
Likewise, many problems in SWE-bench Verified come from real-world repositories and are inherently complex. When an issue description is vague, the coding agent being evaluated may lose focus or become trapped in repetitive, unproductive loops. By anchoring to a clear to-do list, Verdent improves task resolved rates and reduces wasted token usage.
This design effectively prevents "model drift", keeping the agent focused not only upon problems from SWE-bench Verified, but also real tasks from the users.
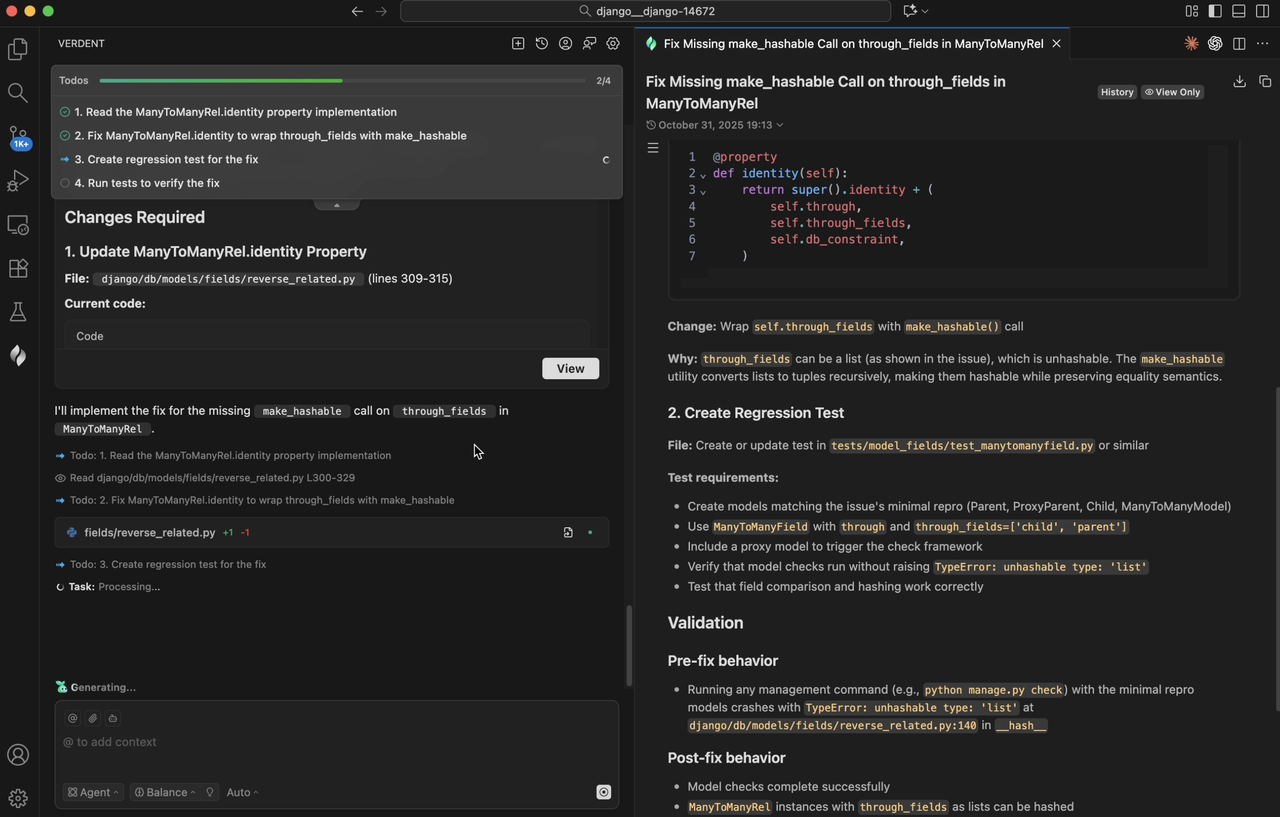
Figure 5. To-do list in Verdent.
Automated Verification & Review
Verdent treats verification as a first-class stage in the loop, not an afterthought. After meaningful edits, Verdent performs type checking, conducts static analysis (e.g., using python -m py_compile in Python), and executes test runs. For larger edits, Verdent spawns an intelligent code review subagent that inspects the diff, flags potential risks, and reports back to the main agent once the assigned review task is complete. In SWE-bench, this process involves comparing issue descriptions with the resulting code diffs. If any regressions are detected, it triggers a new cycle of debugging and fixing.
Whereas SWE-bench Verified measures success by unit test results, Verdent aims higher. Code generated by Verdent goes beyond simply passing tests -- it reflects the user’s intent and fits into the existing codebase.
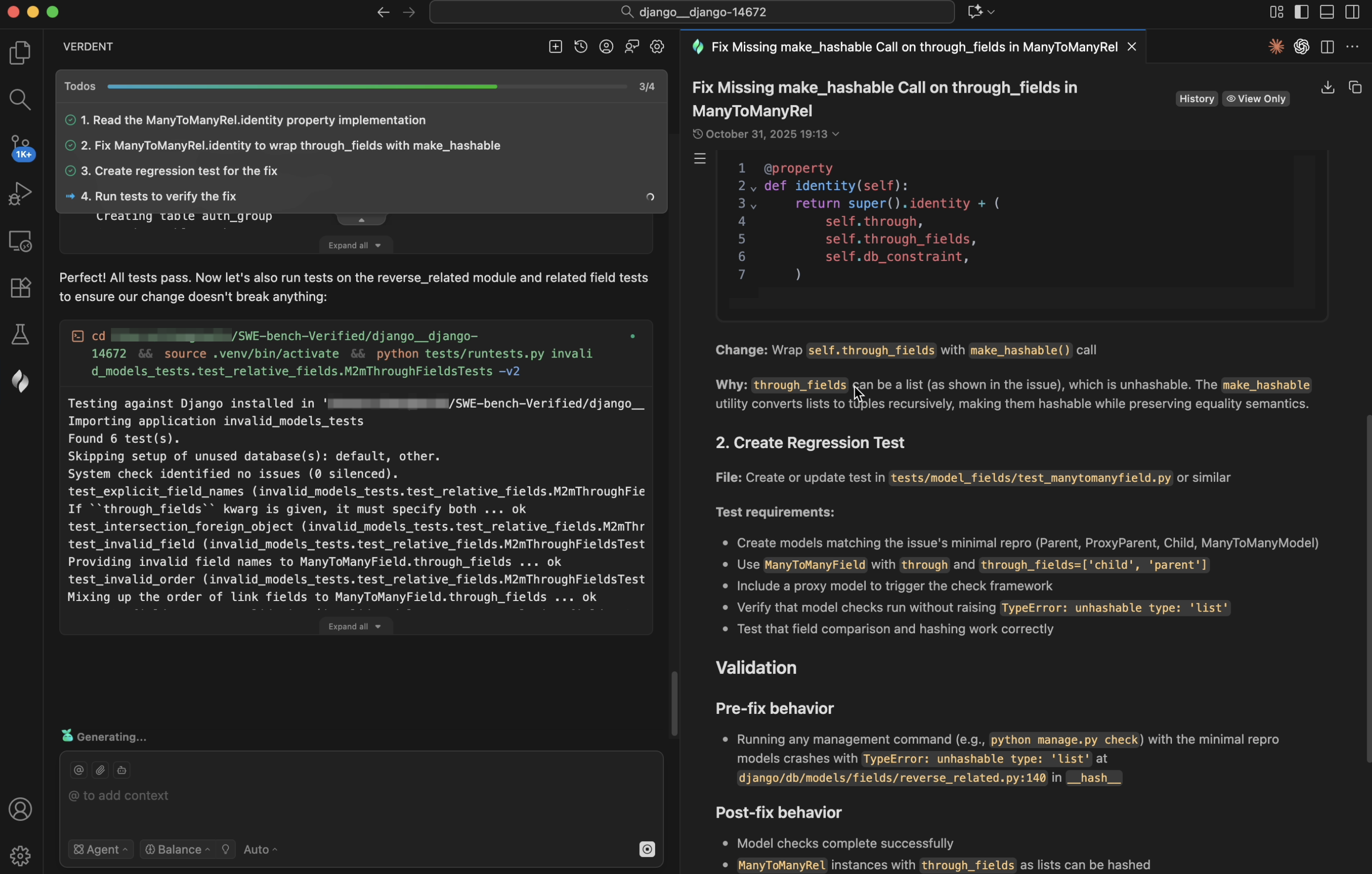
Figure 6. Automatic test execution in Verdent.
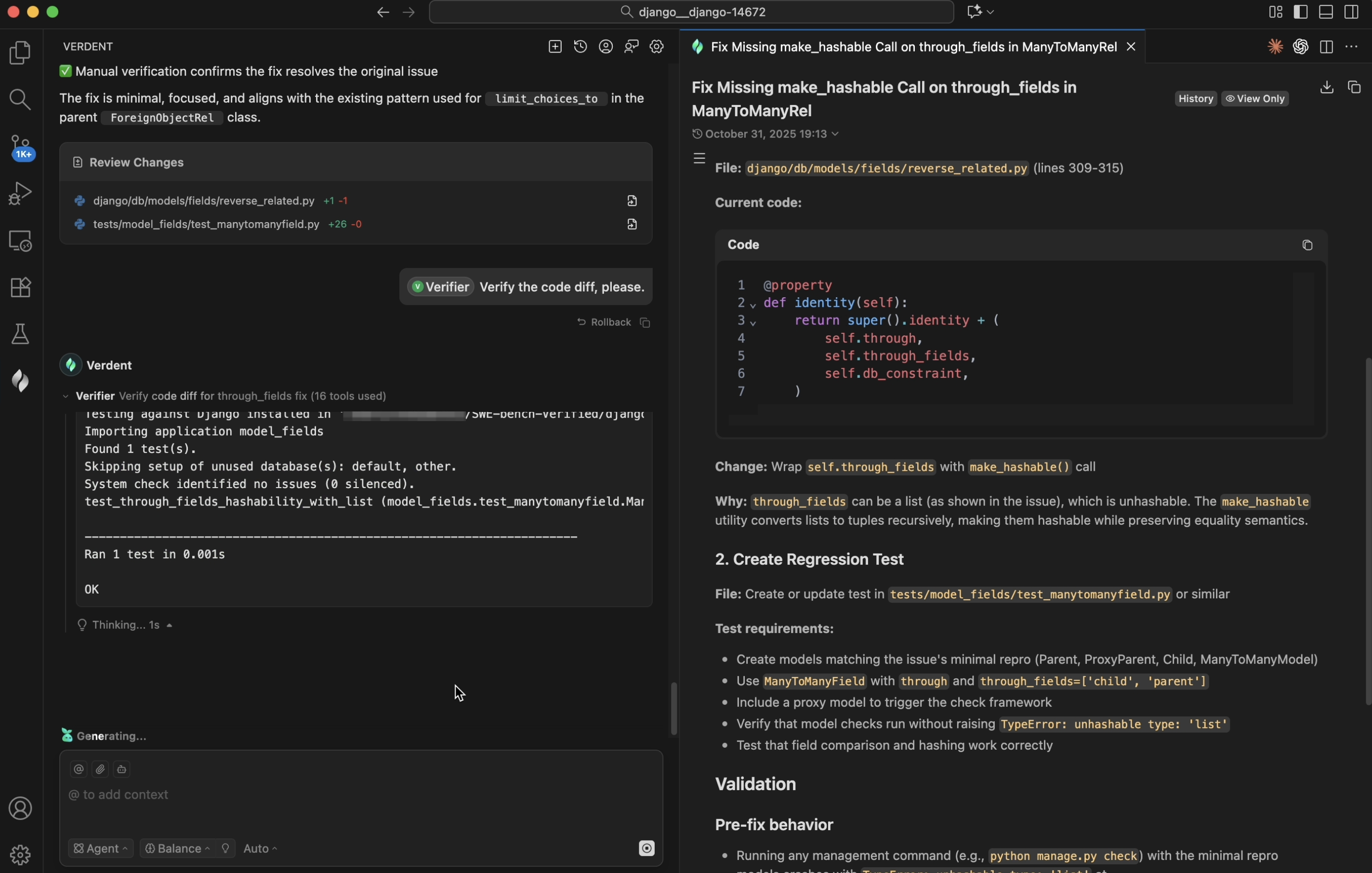
Figure 7. Code review subagent in Verdent.